Ubuntu 20.04
Nvidia graphic driver version: 515.65.01
CUDA version: 11.6
Cudnn version: 8.4.1
1. 주의할점
pip 명령줄 한줄이면 설치가 되나,
CUDA, cudnn, torch, torchivision, torchaudio, 그리고 마지막 torch-tensorrt 의 버전이 모두 맞아야 작동한다.
또한, 설치가 꼬였을때, torch, torchvision, torchaudio, torch-tensorrt 모두 지웠다가 새로 설치를 해야한다.
(CUDA, cudnn은 그대로 둬도 된다)
2. torch 설치
현재 torch 1.13 버전이 배포되고 있으나, 에러가 발생하여 1.12.1 버전으로 진행
공식 링크(Previous PyTorch Versions | PyTorch)
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
3. torch-tensorrt 설치
(meta-generation-failed 에러가 발생하는 pip 설치 명령어로 설명하는 곳이 엄청 많다.)
공식 깃헙이 가장 정확하다. (GitHub - pytorch/TensorRT: PyTorch/TorchScript/FX compiler for NVIDIA GPUs using TensorRT)
pip install torch-tensorrt==1.2.0 --find-links https://github.com/pytorch/TensorRT/releases/expanded_assets/v1.2.0
4. import 및 버전 확인
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
import torch_tensorrt
print(torch_tensorrt.__version__)
위 코드를 실행했을때, 아래처럼 나와야 한다.
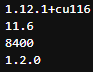
만약 다른 CUDA 버전(특히 10.2)이 나온다면,
torch, torchaudio, torchvision, torch-tensorrt 모두 재설치
5. torch-tensorrt 사용 (torch model compile)
torch 모델 불러오기
import torch
import torchvision
import timm
model = timm.create_model('efficientnet_lite0', pretrained=False, num_classes=2)
model.eval().to('cuda')
FP16으로 compile
(FP32로 compile 할 경우, torch.half를 torch.float32로 바꿔준다)
trt_model_fp16 = torch_tensorrt.compile(model, inputs = [torch_tensorrt.Input((1, 3, 256, 256), dtype=torch.half)],
enabled_precisions = {torch.half}, #FP32의 경우 {torch.half}를 torch.float32로 변경
workspace_size = 1 << 22
)
6. torch-tensorrt 사용 (image에 inference)
normalize 함수 정의
def normalize(image: np.ndarray) -> np.ndarray:
"""
Normalize the image to the given mean and standard deviation
for CityScapes models.
"""
image = image.astype(np.float32)
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
image /= 255.0
image -= mean
image /= std
return image
패키지 import 및 데이터 경로 정의
import cv2
import os
import time
path = 'tensorrt_test/'
pics = os.listdir(path)
각 이미지에 대해서 inference 및 시간 측정
start = time.perf_counter()
for pic in pics:
image_filename = path + pic
image = cv2.cvtColor(cv2.imread(image_filename), cv2.COLOR_BGR2RGB)
resized_image = cv2.resize(image, (256, 256))
normalized_image = normalize(resized_image)
input_image = np.expand_dims(np.transpose(normalized_image, (2, 0, 1)), 0)
input_image = torch.Tensor(input_image)
input_data = input_image.to("cuda")
input_data = input_data.half()
with torch.no_grad():
result_infer = trt_model_fp16(input_data)
result_infer = result_infer.cpu().detach()
result_index = np.argmax(result_infer)
probability = torch.nn.functional.softmax(result_infer, dim=1)
print(probability, result_index)
end = time.perf_counter()
time_tensorrt_gpu = end - start
print(
f"runtime/pic: {time_tensorrt_gpu/len(pics)} \n"
f"images per second: {len(pics)/time_tensorrt_gpu} "
)
모델 저장코드
torch.jit.save(trt_model_fp16, "trt_model_fp16.ts")
현재 글의 torch-tensorrt 환경에서 FP16으로 jupyter를 통해 compile 할 경우
block 실행이 끝나지 않는 버그가 있다. (FP32는 문제없음)
이를위해 ipynb 파일을 .py 파일로 변환한 후 compile, inference, 모델 저장을 한다.
#파일명 확인
jupyter nbconvert --to script torch_tensorrt.ipynb
convert된 .py 파일을 실행
python torch_tensorrt.py
위 코드 그대로 사용하였다면,
아래와 같이 출력할 것이다.

튜토리얼 모음
Torch-TensorRT Getting Started - EfficientNet-B0 — Torch-TensorRT master documentation (pytorch.org)
Torch-TensorRT Getting Started - EfficientNet-B0 — Torch-TensorRT master documentation
Docs > Torch-TensorRT Getting Started - EfficientNet-B0 Shortcuts
pytorch.org
끝
'컴퓨터 > 머신러닝 (Machine Learning)' 카테고리의 다른 글
| 이미지 분류모델 비디오에 적용하기 + 이동평균 (0) | 2022.11.27 |
|---|---|
| Ubuntu, TensorRT 설치 (0) | 2022.11.27 |
| Pytorch model을 ONNX로, ONNX를 openVINO로 변환하기 (0) | 2022.11.17 |
| Nvidia 그래픽 드라이버/CUDA/cudnn 설치 및 제거 (0) | 2022.11.14 |
| Super Resolution EDT 사용하기 (1) | 2022.10.08 |



