작업내용
이미지 분류를 위해 학습/준비된 모델을 비디오에 적용
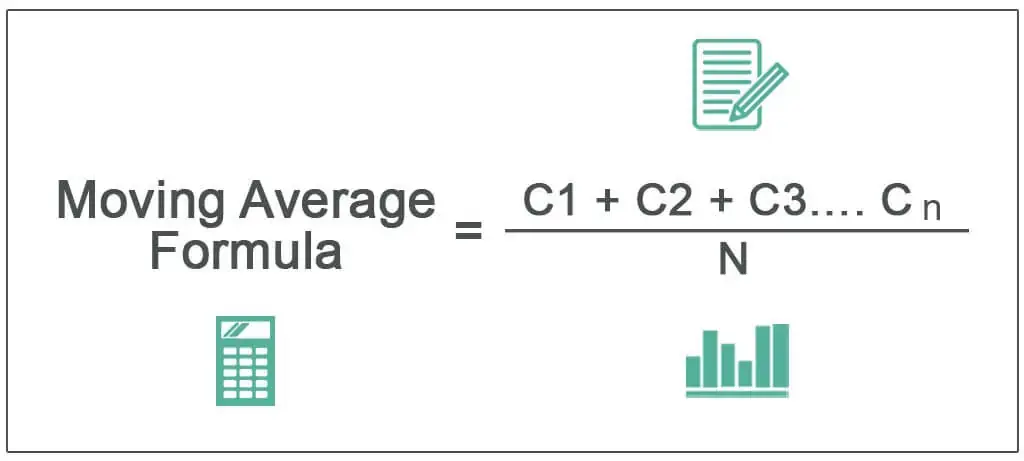
이동평균(moving average)을 적용하여,
frame 5장에 대한 inference probability의 평균이 0.5 이상일때, True로 표시하도록 조절
참고한글:
Video classification with Keras and Deep Learning - PyImageSearch
Video classification with Keras and Deep Learning - PyImageSearch
In this tutorial, you will learn how to perform video classification using Keras, Python, and Deep Learning.
pyimagesearch.com
1. package 로드 및 모델 로드
import torch
import timm
from collections import deque
import cv2
import albumentations as A
from albumentations.pytorch import ToTensorV2
model = timm.create_model('efficientnet_lite0', pretrained=False, num_classes=2)
device_type = 'cuda'
# 저장된 weight가 있다면 아래의 코드로 weight load
device = torch.device(device_type)
model.load_state_dict(torch.load("20%_drop_efficientnet_lite0_47", map_location=device))
model.eval()
2. inference 함수 정의
def inference(img, model, device_type):
#Image Preprocessing
input_size = 256
transforms = {}
transforms['test'] = A.Compose([
A.Resize(input_size, input_size),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0),
ToTensorV2(p=1.0)
], p=1.)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = transforms['test'](image=img)['image']
img = img.unsqueeze(0)
#Inference
img = img.to(device_type)
model = model.to(device_type)
model.eval()
output = model(img)
output = output.cpu().detach()
probs = torch.nn.functional.softmax(output, dim=1)
prob_label_1 = probs[0][1].detach().numpy()
prob_label_0 = probs[0][0].detach().numpy()
outputs = torch.argmax(output, dim=1)
return prob_label_1, prob_label_0, outputs
3. 이동평균 계산을 위한 deque 정의 및 비디오 로드
#maxlen의 숫자를 조절하여 이동평균의 window size 조절
Q = deque(maxlen=5)
vs = cv2.VideoCapture('video.mpg')
4. 프레임 별 inference, 이동평균, 결과 text 입력, 비디오 저장
while True:
#read video
(grabbed, frame) = vs.read()
if not grabbed:
break
if W is None or H is None:
(H, W) = frame.shape[:2]
#model inference
img = frame.copy()
prob_1, prob_2, label = inference(img, model, device_type)
#moving average calculation
Q.append(prob_1)
result = np.array(Q).mean(axis=0)
#check moving average and define label_text
if result > 0.5:
label_text = 'True'
else:
label_text = 'False'
#put label_text on the frame
text = "{}".format(label_text)
cv2.putText(img, text, (35, 50), cv2.FONT_HERSHEY_SIMPLEX,
1.25, (0, 255, 0), 5)
#save as video
if writer is None:
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
writer = cv2.VideoWriter('test.mp4', fourcc, 30,
(W, H), True)
writer.write(output)
print("[INFO] cleaning up...")
writer.release()
vs.release()
끝
'컴퓨터 > 머신러닝 (Machine Learning)' 카테고리의 다른 글
| Windows, OpenVINO 설치하기 (1) | 2022.11.30 |
|---|---|
| OpenVINO, intel 내장 그래픽, 사용 model inference 하기 (1) | 2022.11.29 |
| Ubuntu, TensorRT 설치 (0) | 2022.11.27 |
| Ubuntu, torch-tensorrt 설치 및 사용 (0) | 2022.11.27 |
| Pytorch model을 ONNX로, ONNX를 openVINO로 변환하기 (0) | 2022.11.17 |



