Ubuntu 20.04
공식 github
https://github.com/XPixelGroup/HAT
GitHub - XPixelGroup/HAT: Arxiv2022 - Activating More Pixels in Image Super-Resolution Transformer
Arxiv2022 - Activating More Pixels in Image Super-Resolution Transformer - GitHub - XPixelGroup/HAT: Arxiv2022 - Activating More Pixels in Image Super-Resolution Transformer
github.com
- 앞선 글에서 (https://honbul.tistory.com/59)
4번, setup.py까지 진행된 상태에서 진행 - 2배 증강 학습을 위한 gt (원본) 영상(이미지)와 lq (1/2 해상도) 영상(이미지) 준비
- 학습에 사용된 영상 해상도
- 고화질: 958 x 1154
- 저화질: 479 x 577
1. ffmpeg를 활용한 영상에서 이미지 추출
gt 영상과 lq 영상에 각각 디렉토리를 만들어 실행
저장되는 이미지 이름은 gt와 lq가 같아야 함
#bash 에서
ffmpeg -i video.mp4 frames/video_%06d.png
2. train set 및 valid set 분할
적절한 비율로 train/valid 셋 분할
- gt
- train
- valid
- lq
- train
- valid
구조로 구성
gt와 lq 의 train/valid를 구성하는 이미지들의 이름과 순서는 같아야 한다.
3. meta_info_file.txt 제작
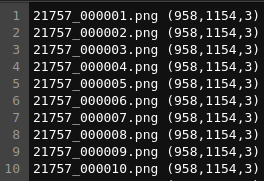
아래 이미지와 같은 구조를 갖는 meta 정보 텍스트 파일 제작
image_이름 (크기) 로 구성
크기는 고화질 데이터의 사이즈 정보 입력
4. options/train 디렉토리 내부
train_HAT_SRx2_finetune_from_ImageNet_pretrain.yml 파일 수정

수정되어야할 부분을 정리하면
- dataroot_gt: 고화질 학습 데이터셋 경로
- dataroot_lq: 저화질 학습 데이터셋 경로
- meto_info_file: 위에서 제작한 meta 정보 (고화질데이터) 텍스트 파일 경로
validation 데이터셋 정보는 위처럼 입력, 이후 사진에는 없지만
- pretrain_netrwork_g: 사전 학습된 모델 경로
- val_freq: validation 데이터셋 성능 확인 빈도
5. 학습 시작
# 2개 GPU 분산 학습
CUDA_VISIBLE_DEVICES=0,1 python3 -m torch.distributed.launch --nproc_per_node=2 --master_port=4321 hat/train.py -opt options/train/train_HAT_SRx2_finetune_from_ImageNet_pretrain.yml --launcher pytorch
끝
'컴퓨터 > 머신러닝 (Machine Learning)' 카테고리의 다른 글
| Ubuntu, ROCm, AMD GPU, Docker, Tensorflow, 환경에서 JAX 세팅 정리 (0) | 2022.12.28 |
|---|---|
| Pytorch distributed launch watchdog timeout 에러 해결 (0) | 2022.12.27 |
| AMD GPU MIGraphX docker 사용 정리 (0) | 2022.12.22 |
| Super resolution 모델, HAT, inference 사용 정리 (0) | 2022.12.19 |
| TensorRT Docker 사용 정리 (0) | 2022.12.13 |



