[E ProcessGroupNCCL.cpp:587] [Rank 3] Watchdog caught collective operation timeout: WorkNCCL(OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1803170 milliseconds before timing outUbuntu 20.04
BSRGAN, HAT 모델 학습 중 확인
https://github.com/cszn/BSRGAN
GitHub - cszn/BSRGAN: Designing a Practical Degradation Model for Deep Blind Image Super-Resolution (ICCV, 2021) (PyTorch) - We
Designing a Practical Degradation Model for Deep Blind Image Super-Resolution (ICCV, 2021) (PyTorch) - We released the training code! - GitHub - cszn/BSRGAN: Designing a Practical Degradation Model...
github.com
https://github.com/XPixelGroup/HAT
GitHub - XPixelGroup/HAT: Arxiv2022 - Activating More Pixels in Image Super-Resolution Transformer
Arxiv2022 - Activating More Pixels in Image Super-Resolution Transformer - GitHub - XPixelGroup/HAT: Arxiv2022 - Activating More Pixels in Image Super-Resolution Transformer
github.com
https://github.com/WongKinYiu/yolov7/issues/714
Watchdog caught collective operation timeout · Issue #714 · WongKinYiu/yolov7
Hi all, I am trying to train the yolov7 model with --multi-scale , I was training it for 20 epochs and my batch size was 4. Also I was using 4 RTX 3080 GPUs for multi-GPU training. training command...
github.com
학습은 잘 되다가, validation process에서 갑자기 아래의 에러와 함께 학습이 종료될 때가 있다.
[E ProcessGroupNCCL.cpp:587] [Rank 3] Watchdog caught collective operation timeout: WorkNCCL(OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1803170 milliseconds before timing out
이는 pytorch에서 분산 학습에 사용되는 torch.distributed.init_process_group 함수의 default timeout 값이 1800초 이기 때문
https://pytorch.org/docs/stable/distributed.html
Distributed communication package - torch.distributed — PyTorch 1.13 documentation
Shortcuts
pytorch.org
따라서 아래 사진의 가장 아랫줄의 dist.init_process_group(backend=backend, **kwargs) 부분을 수정
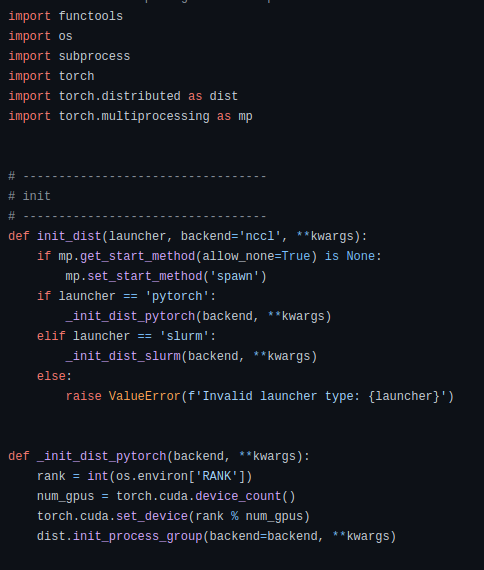
def _init_dist_pytorch(backend, **kwargs):
rank = int(os.environ['RANK'])
num_gpus = torch.cuda.device_count()
torch.cuda.set_device(rank % num_gpus)
dist.init_process_group(backend=backend, timeout=datetime.timedelta(seconds=18000), **kwargs)
끝
'컴퓨터 > 머신러닝 (Machine Learning)' 카테고리의 다른 글
| Yolov9 Jupyter에서 돌려보기 (1) | 2024.05.15 |
|---|---|
| Ubuntu, ROCm, AMD GPU, Docker, Tensorflow, 환경에서 JAX 세팅 정리 (0) | 2022.12.28 |
| Super resolution 모델, HAT train 정리 (0) | 2022.12.26 |
| AMD GPU MIGraphX docker 사용 정리 (0) | 2022.12.22 |
| Super resolution 모델, HAT, inference 사용 정리 (0) | 2022.12.19 |



