Video Restoration Transformer (VRT) 사용하기 - 1 (tistory.com)
Video Restoration Transformer (VRT) 사용하기 - 1
Super Resolution에 (Image Restoration) 대해 알아보던 중 아래의 모델을 찾게되어 사용법을(학습/추론) 공부해 보았다. 이번 글에서는 모델 구동 환경/데이터 준비를 (REDS dataset) 다루겠다. GitHub - Jingyun..
honbul.tistory.com
에 이어지는 글로
학습에 대한 내용을 다루겠다.
사용자의 환경과 목적에 따라 모델 조건을 바꿔야 할텐데
vrt 모델에서는 options/vrt 폴더안의 여러 json 파일로 조정할 수 있다.

이번 글에서는 REDS 데이터셋을 활용한 sr (super resolution) 이므로
001_train_vrt_videosr_bi_reds_6frames.json 파일을 조정한다.
options/vrt 폴더에 위치하여 편집기로 열어보자 (nano 001_train_vrt_videosr_bi_reds_6frames.json 입력)
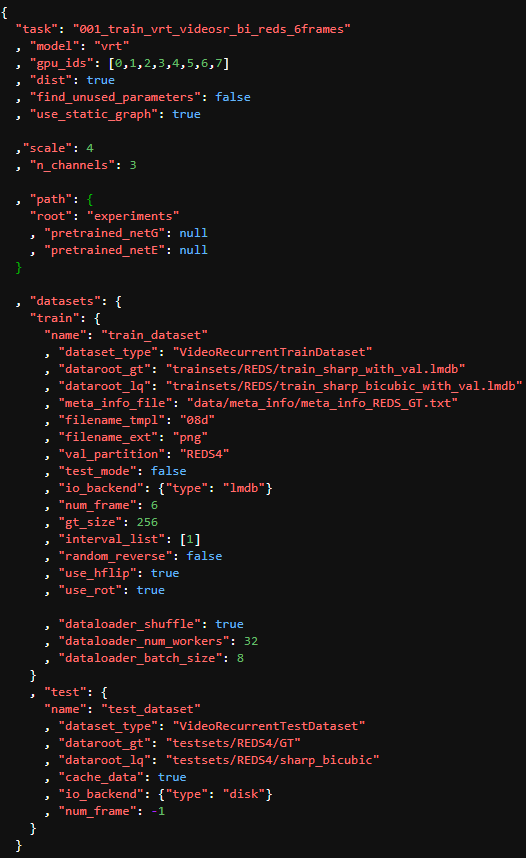
대충 이런 내용이 보일텐데,
중요한 부분만 설명하자면,
"gpu_ids" - 사용할 gpu 개수와 번호이다. 만약 2개라면 [0, 1]만 남기면 된다.
"scale" - super resolution 배수, 이미지를 4배로 키우면 4.
"dataroot_gt" - 높은 해상도 이미지들이 담긴 폴더 경로,
"trainsets/REDS/train_sharp_with_val.lmdb" 로 입력되어 있을텐데 .lmdb를 지우고
"trainsets/REDS/train_sharp_with_val"로 바꿔준다.
"dataroot_lq" - 낮은 해상도 이미지들이 담긴 폴더 경로,
위처럼 .lmdb를 지우고, train_sharp_bicubic_with_val 폴더를 보면 X4 안에 001~269의 이미지 폴더들이 있다.
따라서 "trainsets/REDS/train_sharp_bicubic_with_val/X4" 를 입력해준다.
"io_backend" - {"type": "lmdb"}로 입력되어 있을텐데, {"type":"disk"}로 바꿔준다.
"num_frame" - 학습시 모델에 들어갈 frame의 수 정도로 보면된다.
2 이상의 수가 들어가야하며 낮을수록 GPU 메모리를 적게 먹는다.
"dataloader_batch_size" - 8로 입력되어 있을텐데 낮으면 낮을수록 GPU 메모리를 적게 먹는다.
하단의 train 이후에는 모델 학습에 필요한 내용들인데,
pretrain된 모델을 가져와서 할 경우,
"G_param_strict" 를 true에서 false로 바꿔준다.
#필자의 환경에서만 발생하는 문제일 수도 있다.
그 외 "total_iter", "G_scheduler_periods", "checkpoint_test", "checkpoint_save", "checkpoint_print" 는 모두
반복 학습의 수, 모델 저장 수 등등이므로 적절하게 조절한다.
설명한대로 세팅을 다 했다면,
KAIR 폴더에 위치해서
python3 -m torch.distributed.launch --nproc_per_node=2 --master_port=1234 main_train_vrt.py --opt options/vrt/001_train_vrt_videosr_bi_reds_6frames.json --dist True 를 입력했을때 학습을 시작할 것이다.
#위 커맨드 중 --nproc_per_node=2 는 GPU가 2개라는 의미이므로 사용하는 GPU의 수로 바꿔준다.
#처음에는 아마 spynet이라는 모델을 다운받고 어쩌고 하다가 오류가 나올수 있으니 반복해서 입력해보자.
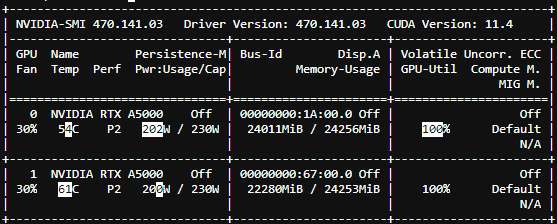
위의 사진은 batch_size 2일때, A5000 (24GB) 2장에서 각각 약 22~24GB의 메모리를 차지하면서 학습중인 모습이다.
학습 결과나 모델의 저장은 KAIR/experiments/001~ 폴더안으로 된다.
"checkpoint_print" 를 250으로 수정하면 아래와 같이 출력된다.

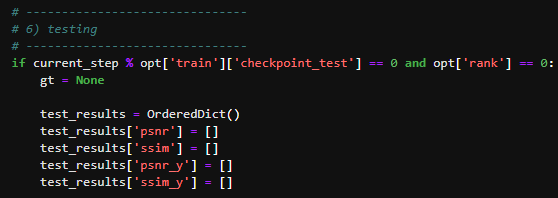
#혹시 모델이 저장될때, main_train_vrt.py 에서 gt 어쩌고 하는 에러가 발생할 경우
main_train_vrt.py 파일을 편집기로 열어서, 아래의 사진처럼 gt = None을 추가한다.
추가로, pretrained 모델을 사용을 위해서는
모델을 받아서, 적절한 폴더에 넣은 후, 적절한 이름으로 변경해 주어야 한다.
먼저 모델을 받는 곳은 아래이고,
#001~ 파일을 받으면 된다.
Releases · JingyunLiang/VRT · GitHub
Releases · JingyunLiang/VRT
VRT: A Video Restoration Transformer (official repository) - JingyunLiang/VRT
github.com

해당 파일을 KAIR/experiments/001~/models 폴더안에 위치한다.

위치한 pth 파일을 0_G.pth로 이름을 바꿔준다.
이후 모델을 실행하면 출력되는 내용에서 로드된 것을 확인할 수 있다.

inference는 다음에!
끝
'컴퓨터 > 머신러닝 (Machine Learning)' 카테고리의 다른 글
| Nvidia 그래픽 드라이버/CUDA/cudnn 설치 및 제거 (0) | 2022.11.14 |
|---|---|
| Super Resolution EDT 사용하기 (1) | 2022.10.08 |
| Video Restoration Transformer (VRT) 사용하기 - 1 (0) | 2022.09.01 |
| WSL2, Nvidia GPU, CUDA 환경에서 super-resolution 모델 (SwinIR) 돌려보기 (0) | 2022.07.29 |
| WSL2, AMD GPU, DirectML 환경에서 super-resolution 모델 (tecogan) 돌려보기 (0) | 2022.07.25 |



