subtitle: "장거리 DNA 상호작용을 통합한 유전자 발현 예측"
Enformer 논문 핵심 정리
원문 논문
Žiga Avsec, Vikram Agarwal, Daniel Visentin, Joseph R. Ledsam, Agnieszka Grabska-Barwinska, Kyle R. Taylor, Yannis Assael, John Jumper, Pushmeet Kohli, David R. Kelley.
Effective gene expression prediction from sequence by integrating long-range interactions.
Nature Methods 18, 1196–1203 (2021).
DOI: 10.1038/s41592-021-01252-x
라이선스 메모
원문은 CC BY 4.0 오픈액세스 논문이다. 아래 figure는 원문 figure를 가독성을 위해 crop한 이미지이며, 블로그에 재사용할 때는 논문 출처와 라이선스를 함께 표기하는 것이 안전하다.
한 줄 요약
Enformer는 CNN 중심의 기존 유전자 발현 예측 모델을 transformer 기반으로 확장해, 최대 약 100 kb 거리의 장거리 조절 정보를 더 잘 통합하고, 그 결과 gene expression prediction, enhancer prioritization, noncoding variant effect prediction을 전반적으로 개선한 논문이다.
1. 이 논문이 풀고자 한 문제
유전자 발현은 프로모터 근처 정보만으로 결정되지 않는다.
멀리 떨어진 enhancer, repressor, insulator 같은 조절 원소가 함께 작동한다. 문제는 기존 sequence-to-expression 모델이 이런 원거리 상호작용(long-range interaction) 을 충분히 반영하지 못했다는 점이다.
기존 SOTA였던 Basenji2 같은 CNN 기반 모델은 사실상 약 20 kb 범위의 정보 활용에 제약이 있었다.
하지만 실제 생물학에서는 20 kb보다 훨씬 먼 조절 원소가 발현을 바꾸는 경우가 많다.
이 논문의 핵심 질문은 간단하다.
- DNA 서열만 보고도, 더 먼 거리의 조절 정보를 반영해 발현 예측을 개선할 수 있는가?
- 그 개선이 단순한 benchmark 점수 상승이 아니라, enhancer-gene linking과 variant interpretation에도 이어지는가?
2. 핵심 아이디어
참고로 Enformer라는 이름은 enhancer + transformer의 합성어다.
2-1. CNN만으로는 멀리 떨어진 정보가 잘 안 섞인다
합성곱(convolution)은 기본적으로 국소(local) 연산이다.
멀리 떨어진 enhancer 정보를 프로모터 쪽으로 전달하려면 여러 층을 거쳐야 한다.
2-2. Self-attention으로 장거리 정보를 직접 연결한다
Enformer는 convolution tower 뒤에 transformer self-attention 을 붙여,
각 위치가 서열 내 다른 위치를 직접 참고하도록 설계했다.
직관적으로 말하면:
- 프로모터 근처 위치가
- 수만 bp 떨어진 enhancer 후보를
- 직접 “보면서”
- 발현 예측에 필요한 정보를 끌어온다.
2-3. 단순히 transformer를 붙인 것이 아니라, “거리와 방향”을 잘 다루도록 설계했다
이 논문에서 중요한 기술 포인트는 다음 3가지다.
- 긴 입력 서열: 입력 DNA는 약 196,608 bp
- Conv + Transformer 하이브리드 구조: motif/국소 패턴은 convolution, 장거리 상호작용은 attention
- 상대적 위치 인코딩(relative positional encodings): 거리의 감소 효과와 upstream/downstream 방향성을 구분하기 쉽게 설계
3. 모델 구조를 아주 짧게 정리하면
- 입력: one-hot encoded DNA sequence (196,608 bp)
- convolution/pooling으로 128 bp 단위 representation으로 압축
- 그 위에 11개 transformer block
- 최종적으로 human 5,313개 track, mouse 1,643개 track 예측
- 멀리 떨어진 조절 원소를 최대 약 100 kb 거리까지 효과적으로 활용
- 저자 추정으로, 모델이 직접 볼 수 있는 관련 enhancer 비율이 대략 47%(<20 kb) → 84%(<100 kb) 로 넓어짐
여기서 중요한 포인트는
“입력 길이 자체가 긴 것” 과 “실제로 장거리 정보를 잘 통합하는 것” 은 다르다는 점이다.
저자들의 메시지는 Enformer가 단지 서열을 길게 넣은 것이 아니라, attention 덕분에 distal regulatory information을 더 잘 쓴다는 데 있다.
4. 그림으로 이해하는 핵심 결과
그림 1. Enformer의 전체 그림: 구조 + 기본 성능 향상
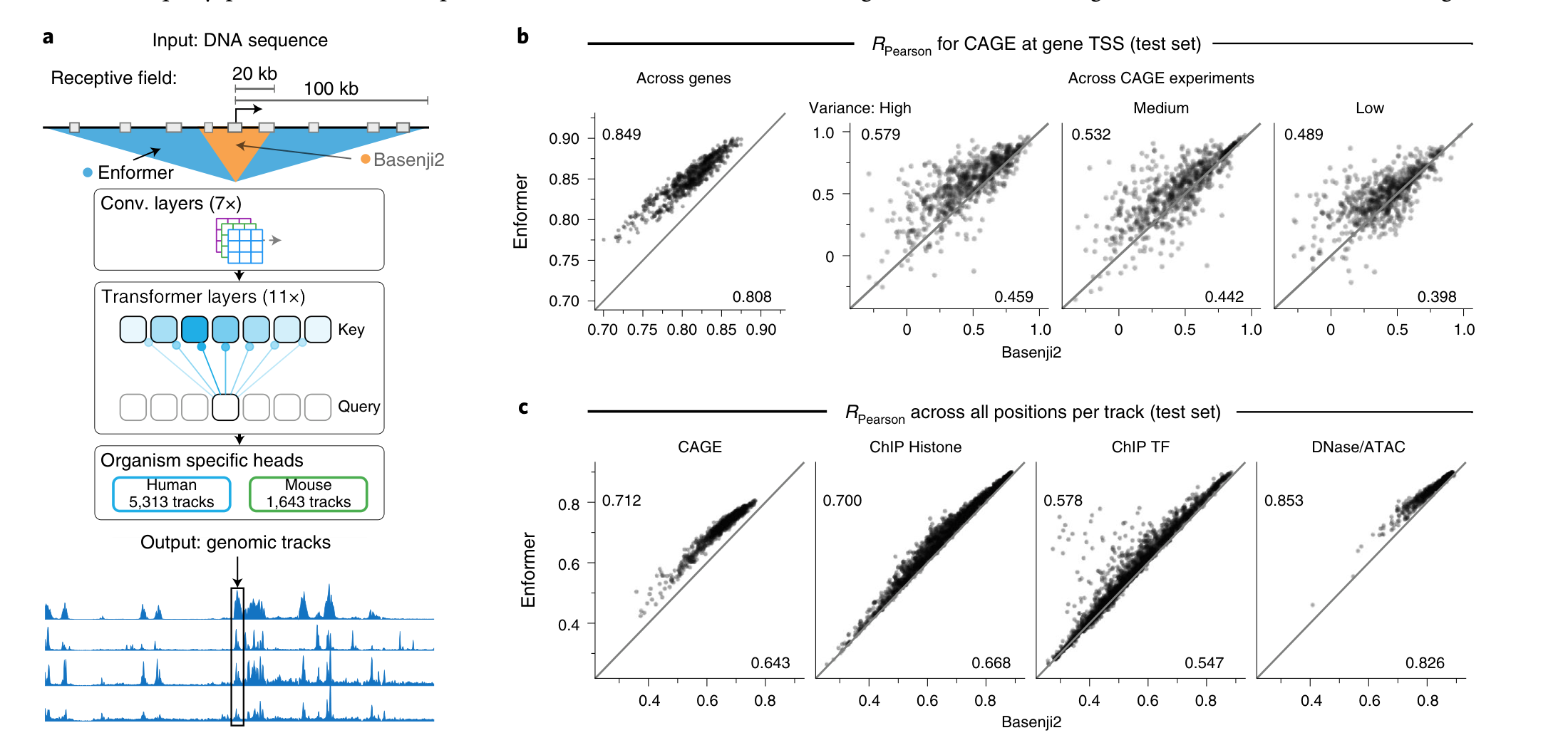
원문 Fig. 1a–c crop. Transformer를 사용해 receptive field를 확장했고, 여러 assay에서 Basenji2보다 높은 예측 성능을 보인다.
이 그림에서 봐야 할 포인트
- 왼쪽(a): Basenji2는 사실상 20 kb, Enformer는 100 kb 수준의 장거리 정보를 활용한다는 메시지
- 오른쪽 위(b): CAGE 기반 gene expression prediction에서 across-genes Pearson r가 0.808 → 0.849로 개선
- 오른쪽 아래(c): CAGE뿐 아니라 histone marks, TF binding, DNase/ATAC에서도 일관된 개선
해석
이 그림은 논문의 가장 핵심적인 claim을 한 장에 보여준다.
즉, 장거리 정보를 더 잘 쓰는 구조적 변화가 실제 benchmark 성능 향상으로 이어진다는 것이다.
그림 2. 정성적 예시: 실제 locus에서도 Enformer가 더 그럴듯하게 맞춘다

원문 Fig. 1d crop. 특정 locus에서 실험값(초록)에 대해 Enformer(파랑)가 Basenji2(주황)보다 더 가까운 패턴을 보인다.
포인트
- 단순 평균 점수뿐 아니라, 실제 genome browser 형태의 예시에서도 차이가 보인다.
- 특히 tissue/cell-type specific한 신호를 Enformer가 더 잘 따라가는 장면이 중요하다.
- 블로그에서 이 그림은 “숫자만 좋아진 것이 아니라, 실제 biological track 모양도 더 비슷해졌다” 는 메시지를 전달하기 좋다.
그림 3. 모델이 distal enhancer와 TAD boundary를 “어디까지” 학습했는가
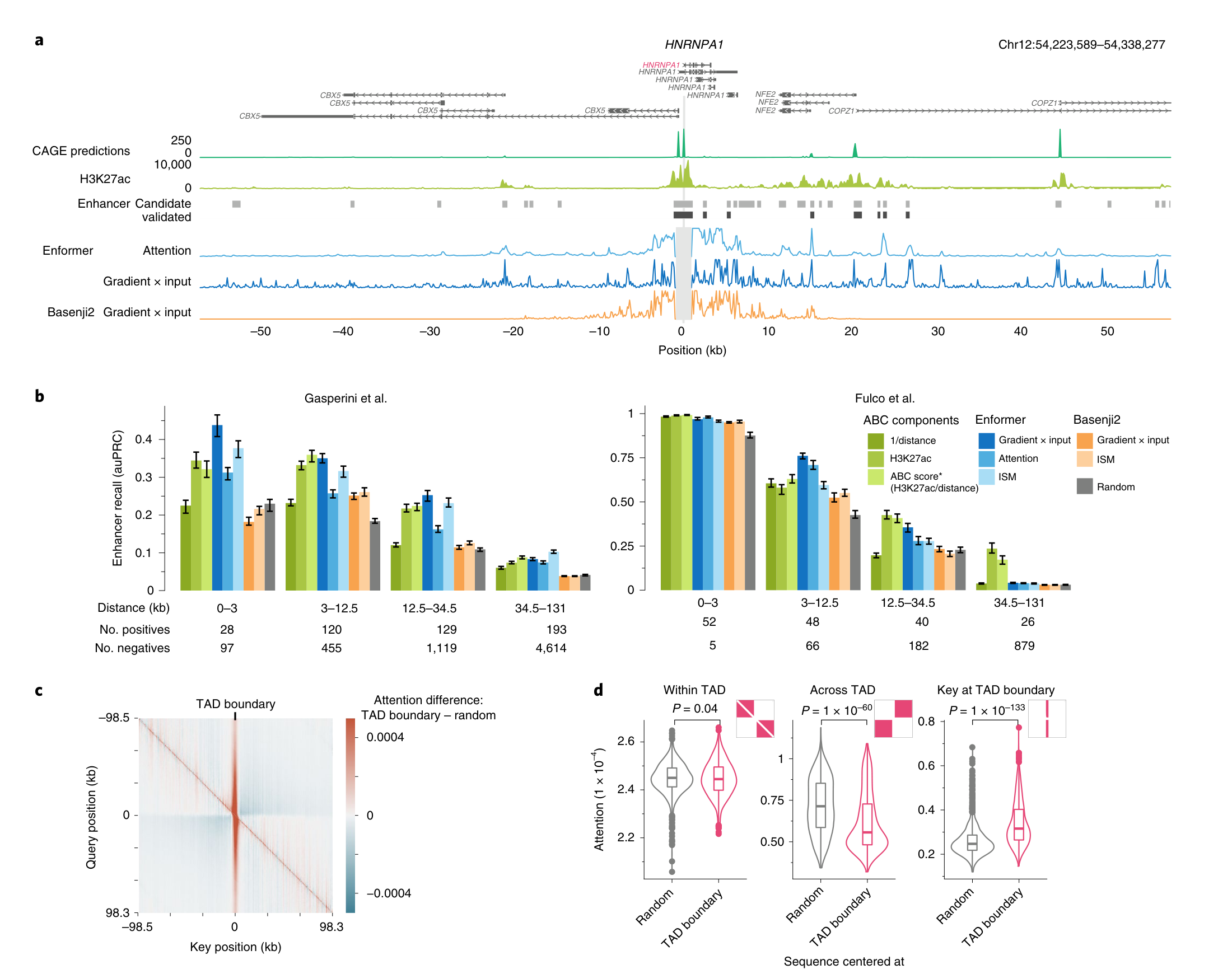
원문 Fig. 2 crop. Enformer는 gene-specific attention / contribution을 통해 distal enhancer를 더 잘 포착하고, TAD boundary 부근의 구조적 패턴도 학습한다.
이 그림에서 핵심은 3가지다.
(1) distal enhancer를 실제로 본다
상단(a)을 보면 HNRNPA1 주변에서
Enformer의 attention과 gradient × input이 프로모터 근처뿐 아니라 떨어진 enhancer 후보까지 강조한다.
Basenji2는 receptive field 한계 때문에 이 부분을 충분히 못 본다.
(2) enhancer prioritization이 실제로 좋아진다
중간(b)에서 Enformer의 contribution score는
CRISPRi로 검증된 enhancer–gene pair를 더 잘 우선순위화한다.
흥미로운 점은, 이 성능이 ABC score 같은 실험 데이터 기반 방법에 가깝거나 경우에 따라 더 낫다는 것이다.
즉,
- ABC: H3K27ac, distance, Hi-C 같은 실험 정보 사용
- Enformer: DNA sequence만 사용
그런데도 경쟁력이 있다.
이 부분이 이 논문을 “단순 prediction benchmark”가 아니라 functional interpretation 논문으로 보이게 만든다.
(3) insulator/TAD boundary 신호도 학습한다
하단(c, d)은 Enformer attention이 TAD boundary 부근에 더 모이고,
boundary를 가로지르는 attention은 줄어드는 경향을 보여준다.
이는 모델이 단순 motif detector를 넘어서,
genome organization이 gene regulation에 미치는 구조적 제약까지 어느 정도 반영했음을 시사한다.
그림 4. GTEx eQTL와의 일치도: variant effect prediction도 좋아진다

원문 Fig. 3a–c crop. Enformer의 variant effect prediction은 GTEx eQTL summary statistics와 더 잘 맞는다.
핵심 포인트
- 저자들은 SLDP regression 으로 model-derived variant score와 GTEx eQTL summary statistics의 concordance를 측정했다.
- 그 결과, CAGE dataset 중 59.4%에서 Enformer가 Basenji2보다 더 높은 최대 Z-score를 보였다.
- matched tissue 예시에서도 improvement가 명확하다.
예를 들어 skeletal muscle, subcutaneous adipose 관련 샘플에서 더 잘 맞는다.
이 결과가 의미하는 것
모델이 단순히 “발현값 자체”를 잘 맞추는 수준을 넘어서,
자연 변이가 발현을 어느 방향으로 얼마나 바꿀지도 더 잘 반영한다는 뜻이다.
그림 5. Fine-mapped eQTL 분류와 실제 변이 사례

원문 Fig. 3d–f crop. Fine-mapped causal eQTL 분류 성능이 좋아지고, 개별 변이 사례에서도 plausible한 motif-level 해석을 제시한다.
이 그림에서 볼 포인트
- (d) GTEx fine-mapped variant classification에서 평균 auROC가 0.729 → 0.747로 개선
- (e) TSS와의 거리 구간별로 봐도 전반적으로 Enformer가 우세
- (f) NLRC5 locus의 rs11644125 사례에서, SP1 motif 교란을 통해 발현 변화가 설명될 수 있음을 제시
블로그에서 강조할 문장
Enformer의 장점은 “변이가 중요하다”고만 말하는 것이 아니라,
어느 motif가 깨졌고 그것이 어떤 발현 변화를 유도했는지까지 더 설득력 있게 연결한다는 점이다.
그림 6. MPRA / saturation mutagenesis benchmark에서도 우세

원문 Fig. 4 crop. Enformer는 saturation mutagenesis MPRA에서도 강한 variant effect prediction 성능을 보인다.
핵심 포인트
- CAGI5 competition 기준으로, Enformer 기반 접근은 평균적으로 가장 좋은 축에 속한다.
- 특히 lasso를 얹은 Enformer는 당시 winning team(Group 3)보다 더 나은 평균 correlation을 보였고, 논문에서는 P = 0.002를 보고한다.
- 추가 학습 없이 쓰는 training-free score도 강력하다는 점이 인상적이다.
왜 중요한가
GTEx는 population structure와 LD의 영향을 받는다.
반면 MPRA는 훨씬 직접적인 functional assay다.
즉, Enformer의 개선이 population-level 통계에서만 좋아 보이는 착시가 아니라,
실제 돌연변이 효과 예측에서도 통한다는 걸 보여준다.
5. 이 논문의 진짜 기여를 4줄로 요약하면
- architecture 기여
CNN 중심 구조에서 transformer self-attention을 도입해 long-range regulatory information integration을 강화했다. - biological interpretation 기여
enhancer, promoter, insulator/TAD boundary 같은 조절 요소를 더 잘 반영한다는 해석적 근거를 제시했다. - variant effect prediction 기여
eQTL와 MPRA 두 축에서 모두 noncoding variant interpretation 성능을 개선했다. - sequence-only modeling의 가능성 제시
Hi-C나 H3K27ac 같은 실험 데이터에 의존하지 않고도 상당히 경쟁력 있는 enhancer-gene linking이 가능함을 보였다.
6. 숫자로 보는 핵심 결과
- CAGE gene expression prediction (across genes, Pearson r): 0.808 → 0.849
- 실험 replicate 수준 정확도와의 간극을 저자들은 약 1/3 정도 줄였다고 해석
- GTEx 관련 CAGE dataset 중 59.4%에서 더 높은 SLDP 최대 Z-score
- GTEx fine-mapped causal variant classification 평균 auROC 0.729 → 0.747
- 48개 GTEx tissue 중 47개에서 Enformer feature 기반 classifier가 Basenji2보다 우세
- MPRA/CAGI5 benchmark에서 Enformer(Lasso) 가 strongest performer 중 하나이며, Group 3 대비 유의한 우세 보고
7. 읽을 때 헷갈리기 쉬운 포인트
7-1. “100 kb를 본다”는 말의 정확한 의미
이 논문은 입력 길이가 긴 것만을 말하는 게 아니다.
핵심은 self-attention 덕분에 멀리 떨어진 정보가 실제로 예측에 반영될 수 있다는 주장이다.
7-2. attention = 인과성은 아니다
attention이나 gradient score는 어디를 참고했는지에 대한 모델 내부 설명이지,
그 자체가 곧 생물학적 인과성의 직접 증거는 아니다.
그래서 저자들은 CRISPRi, eQTL, MPRA 같은 외부 실험 결과로 이를 검증한다.
7-3. “sequence-only”라는 점이 중요하다
이 논문의 임팩트는 정확도 자체도 크지만,
그 정확도를 DNA sequence만으로 달성했다는 데 있다.
8. 한계와 남은 과제
이 논문이 매우 강하지만, 완전히 해결된 것은 아니다.
- 학습된 cell type / assay 범위를 벗어난 일반화는 제한적
- 실험 replicate 수준(약 0.94)에는 아직 못 미침
- 프로모터에서 멀리 떨어진 variant의 sign prediction 은 여전히 어렵다
- transformer 기반이라 계산량과 학습 비용이 크다
- 3D genome contact를 직접 쓰는 모델은 아니므로, 향후 Akita/DeepC류 정보와의 결합 가능성이 남아 있다
즉, Enformer는 “문제를 끝낸 모델”이 아니라
sequence-to-regulation 분야의 기준선을 한 단계 올린 모델로 이해하는 편이 정확하다.
9. 요약
짧은 소개
Enformer는 DNA 서열만 보고 유전자 발현과 크로마틴 상태를 예측하는 딥러닝 모델이다. 이 논문의 핵심은 기존 CNN 기반 모델의 한계를 넘기 위해 transformer self-attention을 도입했다는 점이다. 그 결과 프로모터 주변의 국소 정보뿐 아니라 최대 약 100 kb 떨어진 enhancer 정보까지 더 효과적으로 통합할 수 있게 되었고, 실제로 gene expression prediction, enhancer-gene linking, eQTL interpretation, MPRA 기반 variant effect prediction에서 모두 이전 모델보다 더 나은 성능을 보였다.
조금 더 설명
이 논문이 중요한 이유는 “발현 예측 점수가 조금 올랐다”는 데만 있지 않다. Enformer는 sequence-only 모델임에도 불구하고, CRISPRi로 검증된 enhancer를 더 잘 우선순위화하고, GTEx eQTL와 MPRA에서 noncoding variant의 기능적 효과를 더 정확하게 예측한다. 즉, 이 모델은 단순한 회귀기를 넘어, 비암호화 변이가 왜 중요한지 해석하는 도구로도 의미가 있다. 규제유전체(regulatory genomics)에서 transformer가 왜 강력한지 보여주는 대표 사례라고 볼 수 있다.
10. 결론
Enformer는 “유전자 발현은 멀리 떨어진 조절 원소를 함께 봐야 한다”는 생물학적 상식을, transformer 기반 sequence model로 실제 성능 향상까지 연결한 대표 논문이다.
11. 출처
아래 중 하나로 표기하면 무난하다.
- Source: Avsec et al., Effective gene expression prediction from sequence by integrating long-range interactions, Nature Methods (2021), CC BY 4.0.
- Figure source: Cropped from Avsec et al., Nature Methods 2021, DOI: 10.1038/s41592-021-01252-x, CC BY 4.0.
- Adapted from: Avsec et al. (2021), Nature Methods, CC BY 4.0.
부록. 기술적으로 조금 더 보고 싶다면

Extended Data Fig. 1 crop. Enformer, dilated-convolution variant, Basenji2 구조 비교.
이 부록 그림에서 볼 포인트는 다음과 같다.
- Enformer는 conv tower + transformer block + organism-specific head 구조
- 단순히 attention을 추가한 것이 아니라, pooling과 pointwise block까지 함께 재설계
- Basenji2와의 비교를 통해 “무엇이 바뀌었는지”를 구조적으로 보여준다
기술 블로그를 쓰려면 이 그림을 함께 넣는 것이 좋다.
반대로 일반 독자 대상 요약 글이라면 본문에서는 생략하고, 부록이나 접기 영역으로 보내는 편이 읽기 좋다.
마지막 정리
이 논문을 한 문장으로 요약하면 다음과 같다.
Enformer는 DNA sequence만으로도 distal regulatory logic를 더 잘 포착할 수 있음을 보여준 transformer 기반 규제유전체 모델이며, 그 개선은 expression prediction을 넘어 enhancer prioritization과 variant interpretation까지 확장된다.
'AI 생성 글 정리 > bio' 카테고리의 다른 글
| 논문 정리: Graph-Augmented Retrieval for Digital Evidence-Based Medical Synthesis (0) | 2026.04.06 |
|---|---|
| Energy-Based Flow Matching for Generating 3D Molecular Structure 정리 (0) | 2026.04.06 |
| DNABERT-2 논문 핵심 정리 (0) | 2026.04.03 |
| 논문 정리: Benchmarking DNA Foundation Models: Biological Blind Spots in Evo2 Variant-Effect Prediction (0) | 2026.04.03 |
| PATH-ORACLE 논문 핵심 정리 (0) | 2026.04.03 |



