Bi-Directional Equivariant Long-Range DNA Sequence Modeling
논문: Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
저자: Yair Schiff, Chia-Hsiang Kao, Aaron Gokaslan, Tri Dao, Albert Gu, Volodymyr Kuleshov
발표: ICML 2024 / arXiv:2403.03234v2
한 줄 요약
이 논문은 Mamba 기반 DNA 언어모델에 양방향성(bidirectionality)과 reverse-complement(RC) equivariance를 동시에 넣어서,
멀리 떨어진 유전자 조절 신호까지 더 잘 읽는 DNA foundation model, Caduceus를 제안합니다.
먼저 잡고 가야 할 핵심
논문이 내세우는 가장 큰 기여는 Caduceus를 최초의 RC-equivariant bi-directional long-range DNA language model 계열로 제시했다는 점입니다.
이 논문은 DNA를 “그냥 긴 문자열”로 보지 않습니다. 저자들은 DNA 모델링에서 특히 중요한 세 가지를 전면에 둡니다.
- 양방향 문맥이 필요하다.
자연어처럼 왼쪽에서 오른쪽으로만 읽는 것이 아니라, DNA는 upstream와 downstream 문맥이 모두 중요합니다. - DNA는 reverse-complement 대칭을 가진다.
DNA는 두 가닥이 서로 reverse complement 관계이므로, 어떤 서열과 그 RC 서열은 생물학적으로 같은 정보를 담는 경우가 많습니다. - 장거리 상호작용이 중요하다.
유전자 발현 조절은 가까운 염기만 보는 문제가 아니라, 멀리 떨어진 염기까지 영향을 줄 수 있는 long-range 문제입니다.
이 세 가지를 동시에 잘 반영하는 것이 이 논문의 설계 목표입니다.
이 논문의 핵심 아이디어
논문의 구조를 가장 짧게 요약하면 아래와 같습니다.
| 구성 요소 | 해결하려는 문제 | 핵심 아이디어 |
|---|---|---|
| Mamba | 긴 시퀀스를 효율적으로 처리 | attention 대신 SSM 계열의 선형 시간 모델 사용 |
| BiMamba | DNA의 양방향 문맥 | 정방향 + 역방향 시퀀스를 함께 처리 |
| MambaDNA | DNA의 RC 대칭 | 원본 서열과 RC 서열을 공유 파라미터로 처리 |
| Caduceus | 실제 DNA foundation model | BiMamba + MambaDNA + RC-aware embedding/head 결합 |
여기서 중요한 점은, 저자들이 완전히 새로운 블록을 처음부터 만든 것이 아니라
Mamba를 DNA 문제에 맞게 감싼(wrapper) 구조를 설계했다는 점입니다.
즉, 긴 시퀀스 처리의 장점은 유지하면서 DNA 도메인 지식을 구조적으로 주입합니다.
Figure 1. Mamba → BiMamba → MambaDNA

그림 1. Mamba를 어떻게 DNA 친화적으로 확장했는지를 보여주는 핵심 도식.
이 그림은 사실상 논문의 중심입니다.
1) Mamba
기본 Mamba는 left-to-right causal 방식입니다.
즉, 자연어 next-token prediction처럼 앞에서 뒤로 읽는 데 최적화되어 있습니다.
하지만 DNA는 앞뒤 문맥이 모두 중요하므로 이것만으로는 부족합니다.
2) BiMamba
BiMamba는 원본 서열과 뒤집은 서열을 둘 다 처리합니다.
역방향 출력은 다시 뒤집어서 정방향 출력과 합칩니다.
여기서 중요한 구현 포인트는 projection weight를 공유(weight tying)한다는 점입니다.
이렇게 하면 양방향 모델을 만들면서도 파라미터 수 증가를 크게 억제할 수 있습니다.
3) MambaDNA
MambaDNA는 DNA의 reverse-complement 성질을 구조적으로 반영합니다.
입력 채널을 둘로 나눈 뒤, 한쪽에는 RC 변환을 적용하고, 동일한 Mamba/BiMamba 파라미터로 원본과 RC를 함께 처리합니다.
그 다음 RC 쪽 출력을 다시 RC 변환해서 합칩니다.
이 그림에서 꼭 짚을 포인트
- BiMamba는 “양방향성”을 넣는 장치입니다.
- MambaDNA는 “RC equivariance”를 넣는 장치입니다.
- 논문의 본질은 결국 장거리 처리 효율 + 양방향성 + DNA 대칭성을 한 구조 안에 묶었다는 데 있습니다.
블로그용 해석:
“Caduceus는 Mamba를 버린 모델이 아니라, Mamba 위에 DNA에 필요한 두 가지 편향—양방향성, RC 대칭—을 정교하게 덧씌운 모델”이라고 보면 이해가 쉽습니다.
Figure 2. Caduceus 전체 아키텍처

그림 2. Caduceus-PS와 Caduceus-Ph의 전체 구조.
이 그림은 Caduceus가 실제로 어떻게 쌓이는지 보여줍니다.
Caduceus-PS
Caduceus-PS는 parameter sharing 기반 RC equivariance를 모델 내부에 넣습니다.
- RC-aware token embedding 사용
- 여러 개의 MambaDNA 블록을 스택으로 쌓음
- 최종 language-model head도 RC-equivariant 하게 구성
즉, 모델 자체가 RC 변환에 맞춰 함께 변하도록 설계됩니다.
Caduceus-Ph
Caduceus-Ph는 구조를 조금 단순하게 가져갑니다.
- backbone은 BiMamba stack
- pretraining 때는 RC data augmentation
- downstream inference 때는 원본과 RC 입력을 둘 다 넣고 평균을 내는 post-hoc conjoining 사용
즉, PS는 구조적 내장형, Ph는 추론 시 앙상블형이라고 볼 수 있습니다.
여기서 중요한 개념: Equivariance vs Invariance
이 논문을 읽을 때 가장 중요한 개념 차이입니다.
- Equivariance: 입력을 RC로 바꾸면, 모델의 표현/출력도 그 규칙에 맞게 함께 변함
- Invariance: 입력을 RC로 바꿔도 최종 예측값은 동일함
논문은 먼저 LM 단계에서 equivariance를 만들고, downstream task에서는 averaging이나 conjoining으로 invariance를 확보합니다.
이 구분이 이 논문의 설계를 이해하는 핵심입니다.
왜 pretraining objective도 바뀌는가
기본 Mamba는 causal operator이기 때문에 보통 next-token prediction(NTP)에 맞습니다.
하지만 Caduceus는 bi-directional 모델이므로 BERT 스타일 masked language modeling(MLM)을 사용합니다.
이 선택이 중요한 이유는 다음과 같습니다.
- DNA는 자연어처럼 명확한 좌→우 생성 문제가 아님
- 앞뒤 문맥을 모두 보는 쪽이 DNA 표현 학습에 더 적합
- RC-equivariant language modeling을 실제로 pretraining 단계에 넣었다는 점이 이 논문의 차별점
특히 Caduceus-PS는 RC-equivariant LM이기 때문에, pretraining 단계에서 별도의 RC data augmentation 없이도 RC 대칭을 반영할 수 있습니다.
반면 Caduceus-Ph는 RC-equivariant LM이 아니므로 pretraining에서 RC augmentation을 사용합니다.
Figure 3. Pretraining loss에서 무엇이 보였나
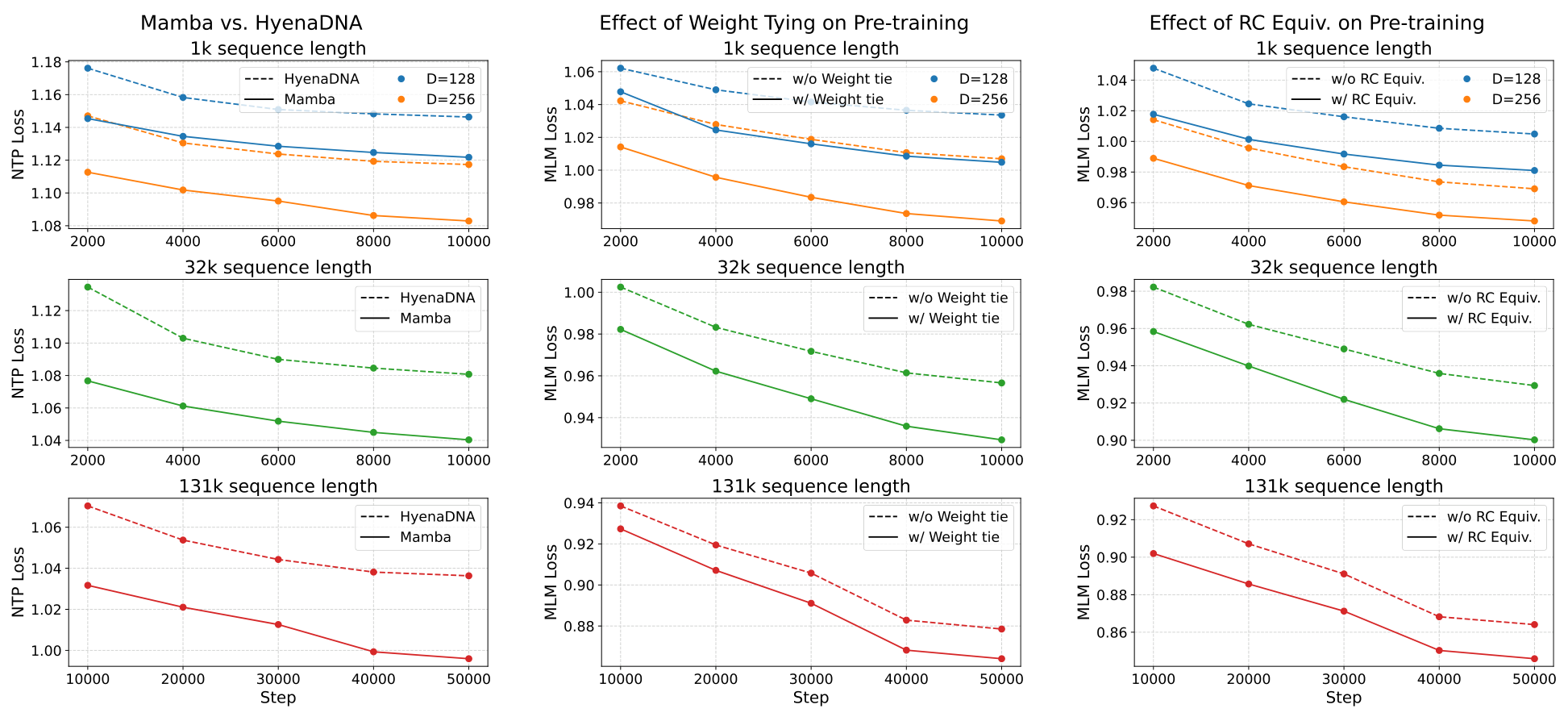
그림 3. pretraining 단계에서의 손실 비교.
이 그림은 세 가지 메시지를 줍니다.
(a) Mamba vs HyenaDNA
같은 수준의 모델 크기와 시퀀스 길이에서 Mamba가 HyenaDNA보다 더 낮은 pretraining loss를 보입니다.
즉, 저자들이 backbone으로 Mamba를 선택한 이유가 실험적으로 뒷받침됩니다.
(b) Weight tying의 효과
BiMamba에서 projection weight를 공유하면, 같은 파라미터 예산에서 더 깊은 양방향 모델을 만들 수 있습니다.
그 결과 weight tying을 쓴 쪽이 더 좋은 MLM loss를 보입니다.
(c) RC equivariance의 효과
RC equivariance를 구조적으로 넣은 모델이 더 낮은 MLM loss를 보입니다.
즉, RC 편향은 단순히 “생물학적으로 그럴듯한 아이디어” 수준이 아니라, 학습 효율과 표현 품질에도 실제 이득을 줍니다.
이 그림의 진짜 의미
많은 논문이 “도메인 지식을 넣었다”고 말하지만, 실제 pretraining loss가 개선되지 않는 경우도 많습니다.
이 논문은 양방향성, weight tying, RC equivariance가 모두 실제 학습 곡선 개선으로 이어진다는 점을 먼저 보여주고 downstream으로 넘어갑니다.
이 흐름이 상당히 설득력 있습니다.
실험 결과는 어떻게 읽으면 좋은가
논문은 크게 세 종류의 downstream 평가를 합니다.
- Genomics Benchmark
- Nucleotide Transformer benchmark 계열 18개 태스크
- Variant Effect Prediction(VEP)
이를 블로그용으로 압축하면 아래 정도로 정리할 수 있습니다.
| 실험 | 핵심 결과 |
|---|---|
| Genomics Benchmark (8개 과제) | Caduceus 계열이 전 과제에서 최고 성능권을 형성. 특히 Caduceus-Ph가 전반적으로 가장 강함 |
| Nucleotide Transformer tasks (18개 과제) | 1.9M 파라미터 수준의 Caduceus-Ph가 117M~500M 크기의 transformer 계열 모델을 18개 중 8개 태스크에서 능가 |
| Long-range VEP | 멀리 떨어진 조절 효과를 볼수록 Caduceus의 장점이 더 뚜렷해짐. 특히 Caduceus-PS가 long-range 구간에서 가장 강함 |
Genomics Benchmark에서 볼 점
논문 표 1을 보면, 전체적으로 Caduceus 계열이 각 태스크 최고 성능을 가져가는 패턴이 분명합니다.
흥미로운 점은 짧고 중간 길이의 분류 태스크들에서는 Caduceus-Ph가 특히 강하다는 것입니다.
이 결과는 저자들이 언급하듯,
post-hoc conjoining이 RC parameter sharing보다 실제 분류 성능에서 더 강하게 작동할 수 있다는 기존 관찰과도 잘 맞습니다.
Nucleotide Transformer benchmark에서 볼 점
여기서 더 인상적인 것은 모델 크기 차이입니다.
- Enformer: 252M
- DNABERT-2: 117M
- NT-v2: 500M
- Caduceus-Ph / PS: 1.9M
즉, Caduceus는 훨씬 작은 모델이면서도 여러 과제에서 경쟁력 있는 성능을 냅니다.
논문이 말하고 싶은 포인트는 단순히 “작아도 잘한다”가 아니라,
DNA에 맞는 inductive bias를 잘 넣으면 거대한 일반 아키텍처를 항상 이길 필요가 없다는 점입니다.
Figure 4. 이 논문의 가장 강한 결과
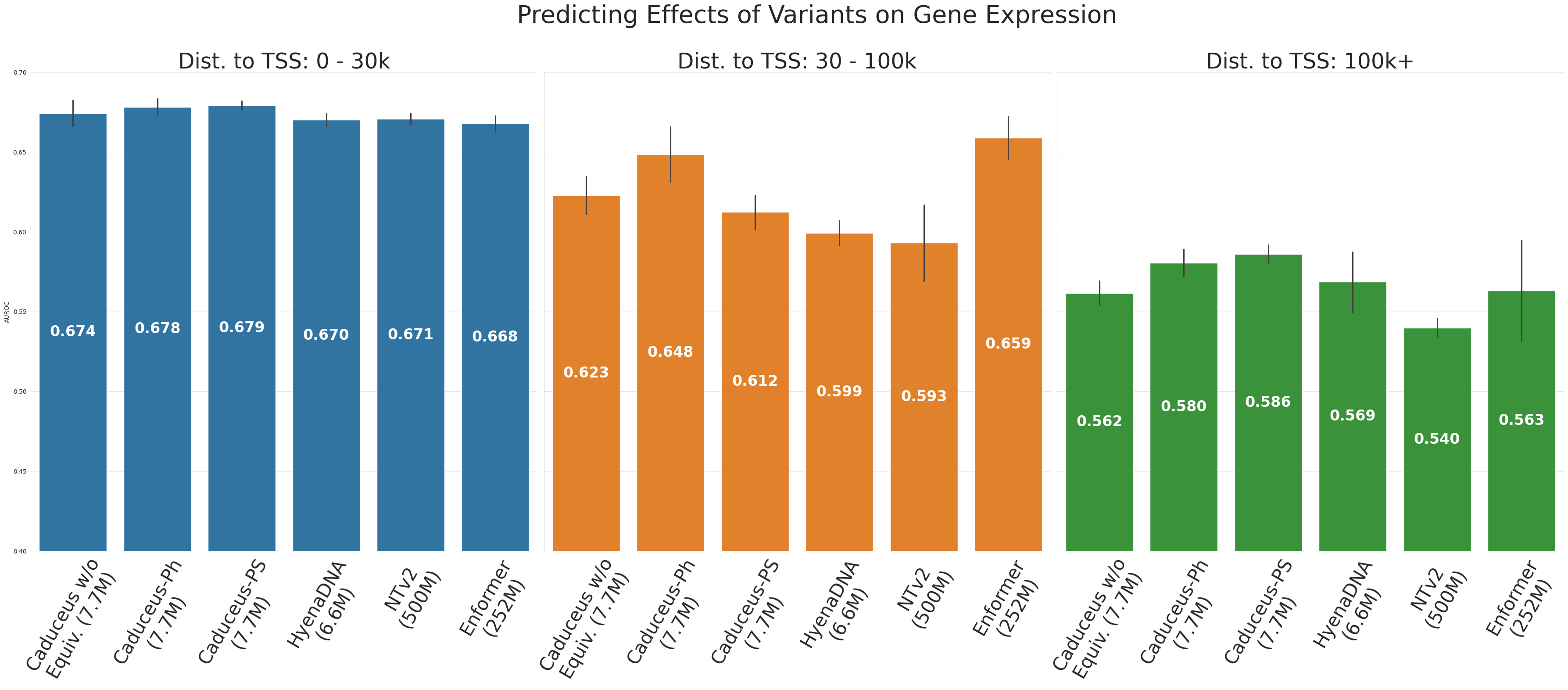
그림 4. SNP가 TSS에서 얼마나 떨어져 있는지에 따라 variant effect prediction 성능이 어떻게 달라지는지 보여주는 결과.
이 그림은 블로그에서 가장 강조하기 좋은 결과입니다.
논문은 SNP와 가장 가까운 TSS(Transcription Start Site) 사이 거리를 기준으로 세 구간을 나눕니다.
- 0–30k bp
- 30–100k bp
- 100k+ bp
짧은 거리(0–30k)
짧은 거리에서는 모델 간 차이가 아주 크지 않습니다.
Caduceus-PS가 0.679, Caduceus-Ph가 0.678로 가장 높고, HyenaDNA는 0.670, Enformer는 0.668 수준입니다.
중간 거리(30–100k)
중간 거리에서는 Enformer가 0.659로 가장 높지만, Caduceus-Ph가 0.648로 바짝 따라갑니다.
이 구간에서는 Caduceus가 강하지만, 아직 압도적이라고 말하긴 어렵습니다.
긴 거리(100k+)
이 구간이 핵심입니다.
가장 멀리 떨어진 조절 효과를 예측하는 설정에서:
- Caduceus-PS: 0.586
- Caduceus-Ph: 0.580
- HyenaDNA: 0.569
- Enformer: 0.563
- NT-v2: 0.540
즉, 가장 긴 거리 구간에서는 Caduceus-PS가 최고 성능을 냅니다.
이 그림의 해석
이 결과가 중요한 이유는 단순히 숫자가 조금 높아서가 아닙니다.
저자들의 주장은 “DNA에서 정말 어려운 문제는 long-range regulatory effect”라는 것인데,
그 주장이 맞다면 장거리 구간으로 갈수록 구조적 편향의 효과가 더 커져야 합니다.
Figure 4는 바로 그 이야기를 뒷받침합니다.
가까운 곳에서는 다들 비슷하지만, 멀어질수록 bi-directionality와 RC equivariance를 넣은 모델이 더 유리해진다는 메시지입니다.
블로그용 핵심 문장:
“Caduceus의 진짜 장점은 평균적인 분류 점수보다, 멀리 떨어진 조절 신호가 중요한 long-range 문제에서 더 분명하게 드러난다.”
이 논문에서 특히 좋은 포인트 5가지
1. DNA를 자연어처럼만 보지 않았다
많은 DNA LM 연구가 “긴 시퀀스”에만 집중했다면, 이 논문은
DNA 고유의 대칭성(RC)과 양방향 생물학을 구조 안에 직접 넣습니다.
2. equivariance와 invariance를 구분해서 설계했다
이 부분이 이 논문의 가장 세련된 지점입니다.
pretraining에서는 equivariance, downstream에서는 invariance를 구현합니다.
이 차이를 이해하면 논문 전체가 훨씬 명확해집니다.
3. 파라미터 효율까지 신경 썼다
BiMamba는 단순히 forward/backward 두 개를 두는 것이 아니라
projection weight tying으로 메모리와 파라미터 증가를 줄입니다.
즉, 아이디어가 예쁘기만 한 것이 아니라 실용적입니다.
4. 성능 향상이 “학습 곡선”부터 확인된다
Figure 3처럼 pretraining loss부터 설득력이 있습니다.
구조적 편향이 downstream 우연이 아니라 학습 초반부터 도움이 되는 성질임을 보여줍니다.
5. task별로 PS와 Ph의 장단점이 갈린다
- Caduceus-Ph: 일반 분류 벤치마크에서 강함
- Caduceus-PS: long-range VEP에서 특히 강함
즉, 이 논문은 “무조건 하나가 다 이긴다”가 아니라
RC 처리 전략에 따라 강점이 달라질 수 있다는 현실적인 메시지도 줍니다.
읽으면서 같이 보면 좋은 해석 포인트
포인트 1. 왜 DNA에는 bidirectional 모델이 더 자연스러운가
자연어 생성은 왼쪽에서 오른쪽으로 읽는 설정이 자연스럽지만,
DNA는 특정 위치의 의미가 좌우 문맥 전체에 의존하는 경우가 많습니다.
그래서 causal LM보다 MLM + bidirectional backbone이 더 잘 맞습니다.
포인트 2. 왜 RC equivariance가 중요한가
DNA 실험에서는 어느 strand가 관측될지 달라질 수 있고,
생물학적으로 동일한 정보를 다른 방향에서 본 것뿐인 경우가 많습니다.
그런데 모델이 이것을 매번 데이터 증강으로만 배우게 하면 비효율적입니다.
논문은 이를 구조적 bias로 넣습니다.
포인트 3. 이 논문의 경쟁력은 “더 큰 모델”이 아니라 “더 맞는 모델”
이 논문은 거대한 범용 모델을 더 키우는 방향과 다릅니다.
오히려 DNA 문제에 맞는 inductive bias를 잘 넣으면, 더 작은 모델로도 강한 결과를 낼 수 있음을 보여줍니다.
한계나 주의해서 볼 점
이 논문이 강한 것은 맞지만, 몇 가지는 같이 보는 것이 좋습니다.
- 모든 태스크에서 PS가 최고는 아닙니다.
일반 분류 태스크에서는 오히려 Caduceus-Ph가 더 자주 강합니다. - splice site 계열에서는 HyenaDNA가 더 나은 경우도 있습니다.
즉, Caduceus의 강점은 모든 DNA 태스크를 일괄 지배한다기보다,
RC와 long-range가 중요한 문제에서 특히 잘 드러난다고 보는 편이 정확합니다. - 비교 대상의 입력 길이와 모델 크기가 완전히 동일한 것은 아닙니다.
따라서 결과 해석에서는 “절대적 우열”보다
어떤 inductive bias가 어떤 문제에서 유리한가를 보는 것이 더 중요합니다.
요약
Caduceus는 Mamba 기반 DNA 언어모델에 양방향성과 reverse-complement equivariance를 결합한 모델이다. 이 논문의 핵심은 DNA를 단순한 긴 문자열로 보지 않고, DNA가 실제로 갖는 생물학적 구조—앞뒤 문맥의 중요성, 두 가닥의 RC 대칭성, 그리고 장거리 조절 상호작용—를 모델 구조 안에 직접 반영했다는 점이다. 실험에서도 이러한 inductive bias는 단순한 아이디어 수준에 머물지 않고 pretraining loss 개선으로 이어졌으며, 특히 long-range variant effect prediction에서는 더 큰 transformer 계열 모델과 비교해도 경쟁력 있는 성능을 보였다. 따라서 이 논문은 “더 큰 DNA 모델”보다 “DNA에 더 맞는 DNA 모델”이 왜 중요한지를 잘 보여주는 사례라고 볼 수 있다.
최종 정리
이 논문의 핵심은 아래 한 문장으로 정리할 수 있습니다.
Caduceus는 Mamba의 장거리 효율 위에, DNA에 꼭 필요한 양방향성과 reverse-complement 대칭을 얹어서 만든 DNA foundation model이다.
그리고 성능 측면에서 가장 중요한 메시지는 이것입니다.
가까운 신호만 보는 문제보다, 멀리 떨어진 조절 신호가 중요한 문제에서 Caduceus의 설계 이점이 더 크게 드러난다.
참고
- Schiff et al., Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling, ICML 2024.
- 본 정리는 업로드된 논문 PDF를 기반으로 작성했습니다.
'AI 생성 글 정리 > bio' 카테고리의 다른 글
| Predicting pathogen evolution and immune evasion in the age of artificial intelligence 정리 (0) | 2026.04.07 |
|---|---|
| Concepts and methods for predicting viral evolution 정리 (0) | 2026.04.07 |
| NucleusDiff 논문 정리 (0) | 2026.04.06 |
| GeneAgent 논문 정리 (0) | 2026.04.06 |
| 논문 정리: Graph-Augmented Retrieval for Digital Evidence-Based Medical Synthesis (0) | 2026.04.06 |



