한 줄 요약
ProteinMPNN은 단백질의 3차원 골격(backbone)만 보고 그 구조에 맞는 아미노산 서열을 설계하는 모델이다. 핵심은 빠른 속도, 다중 체인과 대칭 설계 지원, 그리고 실제 실험에서의 높은 구조 재현성이다.

핵심 숫자
- native backbone sequence recovery: 52.4%
- Rosetta recovery: 32.9%
- 100-residue 설계 시간: 1.2초
- Rosetta 시간: 4.3분
- AlphaFold 기반 실패 설계의 용해성 발현 수율 중앙값: 9 mg/L → 247 mg/L
이 논문이 푸는 문제
단백질 설계의 기본 문제는 단순하다.
원하는 backbone, 즉 단백질의 주사슬 골격이 있을 때 그 구조로 실제 접힐 서열을 찾는 것이다.
하지만 현실은 어렵다.
- backbone은 좋아 보여도 서열이 그 구조를 충분히 지지하지 못할 수 있다.
- 발현은 되지만 불용성일 수 있다.
- 원하는 조립체 대신 다른 상태로 뭉칠 수 있다.
- 기존 Rosetta 기반 방법은 강력하지만 느리고, 설계 문제마다 손조정이 많이 필요했다.
이 논문은 질문을 바꾼다.
에너지 탐색을 매번 다시 하기보다, 구조와 서열의 관계 자체를 학습해 바로 서열을 설계할 수 있는가.
ProteinMPNN의 핵심 아이디어
ProteinMPNN은 backbone을 그래프로 읽는 그래프 신경망이다.
각 위치는 주변 잔기들과의 3차원 관계 속에서 해석된다.
직관적으로 보면 이렇다.
- backbone 원자 사이의 거리 정보를 입력으로 쓴다.
- 각 잔기가 주변 이웃과 어떤 공간 관계를 가지는지 읽는다.
- 이미 정해진 서열 정보를 문맥으로 삼아 다음 위치를 채운다.
- 이때 채우는 순서를 N말단에서 C말단으로 고정하지 않는다.
이 마지막 요소가 중요하다.
고정 순서 대신 임의 순서로 채울 수 있으면 다음이 가능해진다.
- 일부 잔기는 고정하고 나머지만 다시 설계할 수 있다.
- 표적 결합 모티프는 유지하고 구조 틀(scaffold)만 손볼 수 있다.
- 대칭 복합체에서는 여러 체인의 대응 위치를 같은 아미노산으로 묶을 수 있다.
- 반복 단백질, 동종 복합체(homo-oligomer), 이종 복합체(heteromer), 인터페이스 설계까지 같은 틀로 다룰 수 있다.
아래 그림은 이 모델의 범용성이 어디서 나오는지를 가장 명확하게 보여준다.

주목 포인트: B와 C는 "알고 있는 서열은 먼저 고정하고, 대칭 위치는 함께 결정한다"는 전략이 ProteinMPNN의 실전 활용성을 만든다는 점을 보여준다.
성능은 얼마나 좋아졌나
가장 먼저 볼 숫자는 recovery와 속도다.
| 지표 | ProteinMPNN | Rosetta |
|---|---|---|
| native backbone sequence recovery | 52.4% | 32.9% |
| 100-residue 설계 시간 | 1.2초 | 4.3분 |
여기서 sequence recovery는 자연 단백질의 backbone이 주어졌을 때, 원래 서열을 얼마나 잘 맞히는지를 보는 지표다. 완전한 성공 지표는 아니지만, backbone-서열 적합성을 비교하기에는 유용하다.
추가로 논문은 다음도 보여준다.
- 단량체, 동종 복합체, 이종 복합체에서 median recovery가 각각 52%, 55%, 51%였다.
- 성능 향상은 특정 위치 몇 개에만 국한되지 않았다.
- 내부 잔기부터 표면 잔기까지 전반적으로 우세했다.
- 대칭 복합체에서는 대응 위치의 예측을 묶는 방식이 가장 잘 작동했다.
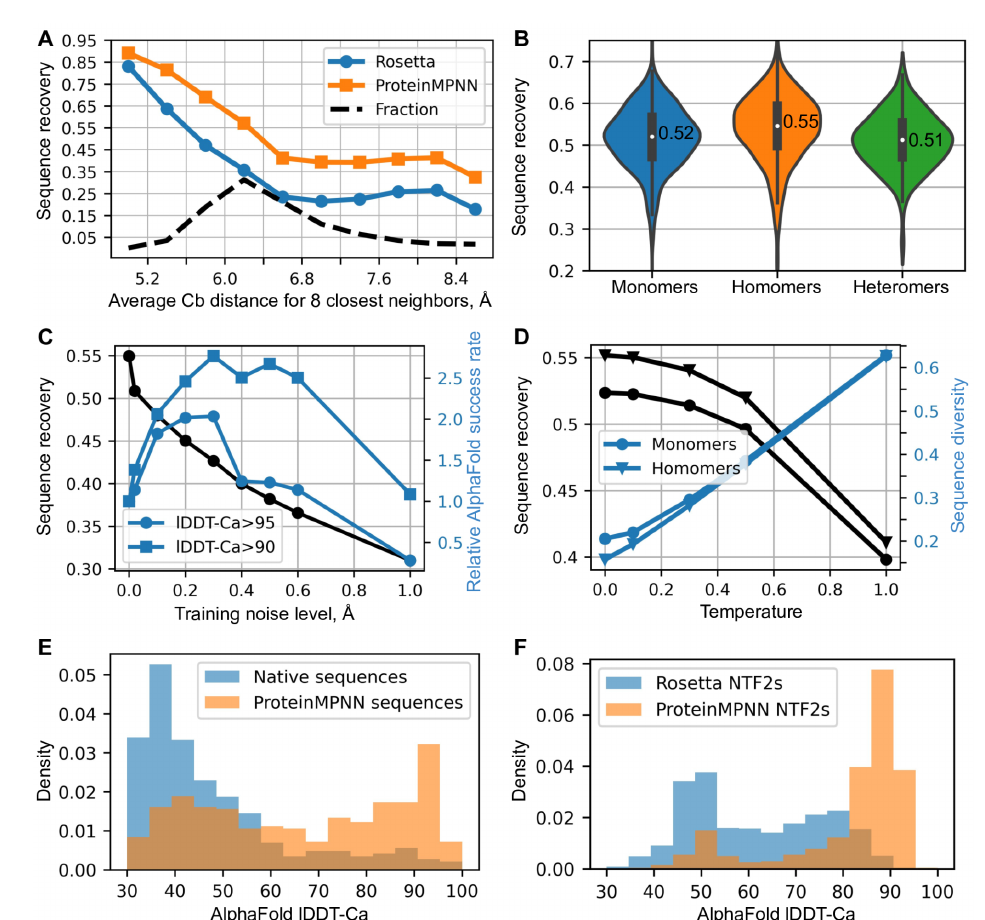
주목 포인트: A는 Rosetta 대비 전반적 우위를, C와 D는 recovery 하나만 높다고 끝이 아니라 "강하게 접히는 서열"과 "다양한 서열" 사이의 균형이 중요하다는 점을 보여준다.
왜 학습 때 backbone에 노이즈를 넣었나
이 논문의 좋은 점은 recovery만 극대화하지 않았다는 데 있다.
실전 설계에서는 backbone 좌표가 원자 단위로 완벽하지 않을 때가 많다.
예측 모델이 만든 구조나 설계 중간 산물은 특히 그렇다.
그래서 저자들은 학습 때 backbone 좌표를 조금 흔들었다.
이 선택의 의미는 직관적이다.
- 좌표를 약간 흔들면 모델은 아주 미세한 원자 배치에 덜 집착한다.
- 대신 전체적인 접힘 패턴을 더 중요하게 본다.
- 완벽한 PDB backbone에서는 원래 서열과의 정확한 일치율이 다소 낮아질 수 있다.
- 하지만 실제 설계에서는 목표 구조를 더 강하게 부호화한 서열을 얻을 수 있다.
논문은 이 효과를 AlphaFold 단일 서열 예측으로 확인했다.
- 노이즈를 넣어 학습한 모델은 목표 구조를 더 자신 있게 재현하는 서열을 더 자주 만들었다.
- 특히 어느 정도 노이즈를 준 모델은 높은 구조 일치도를 보이는 서열을 2-3배 더 많이 만들었다.
- 샘플링 온도, 즉 무작위성의 정도를 높이면 recovery는 조금 떨어지지만 서열 다양성은 크게 늘었다.
즉, 이 모델은 정답 하나를 찾는 도구라기보다 실험해볼 만한 후보군을 빠르게 넓게 제안하는 도구에 가깝다.
실제 실험에서도 통했나
이 논문의 설득력은 계산 결과보다 실험 결과에서 더 분명해진다.
저자들은 기존에 실패했던 설계들을 같은 backbone 위에서 ProteinMPNN으로 다시 설계했다.
대표 결과는 다음과 같다.
- AlphaFold 기반으로 생성한 단량체와 올리고머 backbone에서 기존 서열은 대부분 불용성이었다.
- ProteinMPNN으로 재설계하자 용해성 발현 수율 중앙값이 9 mg/L에서 247 mg/L로 크게 상승했다.
- 96개 설계 중 73개가 용해성으로 발현됐다.
- 이 중 50개는 기대한 단량체 또는 올리고머 상태를 보였다.
- 여러 설계는 95°C에서도 2차 구조를 유지할 정도로 안정했다.
- 한 monomer 설계의 X-ray 구조는 목표 backbone과 2.35 Å 수준으로 가깝게 일치했다.
범위도 넓었다.
- 반복 단백질 설계에서 기존 Rosetta 실패 사례를 구조적으로 복구했다.
- cyclic oligomer에서도 Rosetta보다 높은 성공률을 보였다.
- repeat 대칭과 cyclic 대칭을 동시에 강제한 경우, Rosetta 세트는 40%만 soluble했고 올바른 조립 상태는 0%였다. ProteinMPNN 세트는 88%가 soluble했고 27.7%가 올바른 조립 상태를 보였다.
- two-component tetrahedral nanoparticle 76개 중 13개는 기대한 약 1 MDa 조립체를 형성했다.
- 이 중 한 설계의 결정 구조는 디자인 모델과 1.2 Å 수준으로 가깝게 맞았다.

주목 포인트: A의 발현 수율 개선과 D/K의 구조 일치는 "계산상 그럴듯함"이 실제 단백질 생산과 구조 재현으로 이어졌다는 사실을 압축해서 보여준다.
기능성 단백질 설계에도 적용됐다
마지막 검증은 더 어렵다.
단순히 접히는 단백질이 아니라, 표적에 실제로 결합하는 기능성 단백질을 설계할 수 있는지를 본다.
저자들은 Grb2 SH3 도메인이 인식하는 proline-rich peptide motif를 안정적으로 지지하는 scaffold를 만들었다.
핵심 결과는 명확하다.
- 같은 backbone에서 Rosetta로 만든 서열은 제대로 작동하지 않았다.
- ProteinMPNN으로 다시 설계한 서열은 강한 결합 신호를 보였다.
- 결합에 중요하다고 본 두 위치를 돌연변이로 바꾸자 신호가 크게 줄었다.
이 결과의 의미는 크다.
모델이 단순히 접힐 서열을 고른 것이 아니라, 기능을 만드는 배치까지 어느 정도 보존했다는 뜻이기 때문이다.

주목 포인트: 오른쪽 결합 곡선 비교는 ProteinMPNN 재설계가 실제 표적 결합을 끌어올리고, 대조 돌연변이는 그 결합이 설계 의도와 직접 연결돼 있음을 보여준다.
이 논문의 핵심 기여
정리하면 기여는 네 가지다.
- 고정 backbone 서열 설계의 표준 선택지를 바꿨다.
Rosetta를 보완하는 수준을 넘어서, 기본 엔진으로 쓸 수 있는 성능을 보였다. - 랜덤 디코딩 순서를 실전 기능으로 연결했다.
부분 고정, 대칭 설계, 인터페이스 설계가 자연스럽게 가능해졌다. - 정확한 복원보다 robust design이 더 중요하다는 점을 보여줬다.
실제 folding 가능성과 실험 성공은 recovery 하나로 판단할 수 없음을 분명히 했다. - 계산과 실험을 끊지 않았다.
결정구조, cryoEM, 발현, SEC, 결합 실험까지 연결해 설계 성공을 검증했다.
한계와 해석 포인트
과도한 일반화는 피할 필요가 있다.
- 이 모델은 주어진 backbone에서 서열을 설계한다. backbone 자체를 생성하는 모델은 아니다.
- sequence recovery는 편리한 지표지만 folding success와 동일하지 않다.
- AlphaFold 단일 서열 예측은 강력한 보조 지표지만 여전히 간접 평가다.
- 제공된 PDF는 bioRxiv preprint 버전이다.
그럼에도 실무적 의미는 분명하다.
ProteinMPNN은 단백질 서열 설계를 느리고 수작업이 많은 탐색에서, 빠르고 반복 가능한 설계 파이프라인으로 옮겨놓은 논문이다.
Source
- J. Dauparas et al. Robust deep learning based protein sequence design using ProteinMPNN. bioRxiv preprint, 2022. https://doi.org/10.1101/2022.06.03.494563
- ProteinMPNN code: https://github.com/dauparas/ProteinMPNN



