한 줄 요약
DeepSeek-V3는 671B 전체 파라미터를 가진 MoE 언어 모델이다.
하지만 매 토큰마다 전체 모델을 쓰지 않는다.
토큰 하나를 처리할 때는 37B 파라미터만 활성화한다.
핵심은 단순한 대형화가 아니다.
- 필요한 전문가만 호출하는 구조
- 추론 시 메모리를 줄이는 Attention
- 통신 병목을 숨기는 훈련 파이프라인
- FP8 기반 저정밀 훈련
- DeepSeek-R1로부터의 추론 능력 증류
이 다섯 가지가 함께 맞물린 결과다.
논문이 강조하는 목표는 명확하다.
강한 성능을 유지하면서, 훈련과 추론 비용을 낮추는 것.
왜 중요한가
DeepSeek-V3는 다음 세 가지를 동시에 주장한다.
- 성능
공개 모델 중 최상위권 성능을 보인다. - 비용
전체 훈련에 2.788M H800 GPU 시간이 들었다. - 안정성
전체 훈련 중 회복 불가능한 loss spike나 rollback이 없었다.
논문 기준으로 H800을 시간당 2달러로 계산하면 전체 공식 훈련 비용은 약 557.6만 달러다.
단, 이 비용에는 사전 연구, 실패한 실험, 아키텍처 탐색 비용은 포함되지 않는다.
전체 성능 그림
DeepSeek-V3는 지식형 벤치마크뿐 아니라 수학, 코드, 소프트웨어 수정 벤치마크에서도 강한 결과를 보인다.
특히 MATH 500, AIME 2024, Codeforces, SWE-bench Verified에서 이전 공개 모델 대비 차이가 크다.

Crop 포인트: DeepSeek-V3 막대가 수학·코딩·소프트웨어 수정 영역에서 두드러지는 구간은 이 모델의 핵심 이득이 추론과 코드 능력에 집중되어 있음을 보여준다.
모델 구조: “전체를 쓰지 않고 강해지는” 방식
DeepSeek-V3는 Transformer 기반 모델이다.
다만 일반적인 dense 모델과 다르게 계산을 아낀다.
핵심 구조는 두 가지다.
- MLA: 추론 시 Attention의 캐시 메모리를 줄인다.
- DeepSeekMoE: 토큰마다 필요한 전문가만 골라 계산한다.
여기에 두 가지 개선이 추가된다.
- Auxiliary-loss-free load balancing
- Multi-Token Prediction

Crop 포인트: 오른쪽 위 MoE 영역과 오른쪽 아래 MLA 영역을 함께 보면, DeepSeek-V3가 계산량과 캐시 메모리를 동시에 줄이도록 설계되었음을 알 수 있다.
MLA: Attention 캐시를 작게 만든다
LLM 추론에서는 이전 토큰의 정보를 계속 기억해야 한다.
이때 Key-Value cache가 커진다.
문맥이 길어질수록 메모리 부담도 커진다.
MLA의 직관은 간단하다.
모든 Attention 정보를 그대로 저장하지 말고, 핵심만 압축해서 저장하자.
논문은 Key와 Value를 더 작은 잠재 표현으로 압축한다.
위치 정보는 별도로 유지한다.
이 방식은 추론 중 필요한 캐시 크기를 줄인다.
결과적으로 긴 문맥 처리와 대규모 서비스 배포에 유리해진다.
DeepSeekMoE: 모든 전문가를 쓰지 않는다
MoE는 여러 전문가 네트워크를 두고, 토큰마다 일부만 호출하는 방식이다.
DeepSeek-V3는 각 MoE 층에서 다음을 사용한다.
- 항상 쓰이는 공유 전문가
- 토큰별로 선택되는 라우팅 전문가
- 더 세분화된 전문가 구성
이 구조의 장점은 명확하다.
전체 모델은 크다.
하지만 실제 계산은 선택된 일부 전문가에 집중된다.
그래서 모델 용량은 키우면서도 토큰당 계산 비용은 억제한다.
Load Balancing: 전문가 쏠림을 손실 함수로 억지 조정하지 않는다
MoE의 문제는 전문가 쏠림이다.
특정 전문가에게 토큰이 몰리면 계산이 비효율적이다.
기존 방식은 보조 손실을 추가해 균형을 맞췄다.
하지만 보조 손실이 강하면 모델 품질을 해칠 수 있다.
DeepSeek-V3는 다른 접근을 쓴다.
전문가마다 라우팅 보정값을 둔다.
- 과부하된 전문가는 다음 단계에서 덜 선택되게 만든다.
- 덜 쓰인 전문가는 다음 단계에서 더 선택되게 만든다.
- 실제 출력 가중치는 원래 점수를 기준으로 유지한다.
즉, 라우팅 선택만 부드럽게 조정한다.
모델이 학습하는 표현 자체에 불필요한 압력을 덜 준다.
Multi-Token Prediction: 다음 토큰 하나만 보지 않는다
일반적인 LLM 훈련은 다음 토큰을 맞히는 방식이다.
DeepSeek-V3는 한 걸음 더 나간다.
현재 위치에서 바로 다음 토큰뿐 아니라, 그 다음 미래 토큰까지 예측하게 한다.
의도는 두 가지다.
- 학습 신호를 더 촘촘하게 만든다.
- 모델이 다음 한 단어만이 아니라 이후 흐름까지 준비하게 한다.
추론 시에는 이 MTP 모듈을 버려도 된다.
메인 모델은 독립적으로 작동한다.
또는 MTP를 speculative decoding에 활용해 생성 속도를 높일 수 있다.

Crop 포인트: 메인 모델 뒤에 순차적으로 붙은 MTP 모듈은 “다음 하나”가 아니라 “짧은 미래 흐름”을 함께 학습시키는 장치다.
훈련 인프라: 성능의 절반은 시스템 설계다
DeepSeek-V3는 2048개의 NVIDIA H800 GPU 클러스터에서 훈련됐다.
노드 내부는 NVLink와 NVSwitch로 연결된다.
노드 간 연결은 InfiniBand를 사용한다.
논문에서 중요한 점은 모델 구조만이 아니다.
훈련 시스템 자체가 모델 성능과 비용을 좌우한다.
DeepSeek-V3는 다음 조합을 사용한다.
- Pipeline Parallelism
- Expert Parallelism
- ZeRO-1 Data Parallelism
- 통신과 계산의 중첩
- FP8 혼합 정밀도 훈련
DualPipe: 통신 시간을 계산 뒤에 숨긴다
MoE 훈련은 통신량이 많다.
토큰을 전문가가 있는 GPU로 보내야 하기 때문이다.
DeepSeek-V3는 이 병목을 DualPipe로 줄인다.
핵심은 단순하다.
계산 중에 통신을 같이 처리해, 통신 시간이 따로 드러나지 않게 만든다.

Crop 포인트: 계산 블록 사이에 통신 블록이 끼워진 구조는 통신을 별도 대기 시간이 아니라 계산과 겹치는 작업으로 바꾸려는 설계를 보여준다.
DualPipe는 마이크로배치를 양방향으로 흘린다.
그 결과 파이프라인이 비는 시간이 줄어든다.
논문은 이 방식이 cross-node expert parallelism의 부담을 크게 낮춘다고 설명한다.

Crop 포인트: 색이 촘촘히 채워진 스케줄 표는 GPU가 쉬는 구간을 줄이고, forward와 backward 작업을 겹쳐 처리하는 방식을 직관적으로 보여준다.
Cross-node All-to-All: MoE 통신을 직접 최적화한다
MoE에서는 토큰을 여러 전문가에게 보내고 다시 합쳐야 한다.
이 과정이 all-to-all communication이다.
DeepSeek-V3는 이를 위해 전용 커널을 설계했다.
중요한 전략은 다음과 같다.
- 토큰이 이동할 노드 수를 제한한다.
- 노드 간 통신은 InfiniBand를 쓴다.
- 노드 내부 전달은 NVLink를 쓴다.
- 두 통신 경로가 최대한 겹치도록 만든다.
이 설계는 대규모 MoE 훈련에서 병목이 되는 통신 시간을 줄인다.
메모리 절약도 함께 설계했다
논문은 메모리 절약을 위해 여러 방법을 함께 사용한다.
- 일부 중간 결과는 저장하지 않고 역전파 때 다시 계산한다.
- EMA 파라미터는 GPU가 아니라 CPU 메모리에 둔다.
- MTP 모듈의 embedding과 output head는 메인 모델과 공유한다.
결과적으로 값비싼 tensor parallelism 없이도 대규모 모델 훈련이 가능해졌다고 설명한다.
FP8 훈련: 더 낮은 정밀도로 더 크게 훈련한다
DeepSeek-V3의 중요한 공헌 중 하나는 FP8 혼합 정밀도 훈련이다.
FP8은 메모리와 계산 비용을 줄일 수 있다.
하지만 불안정해지기 쉽다.
값의 범위가 좁기 때문이다.
DeepSeek-V3는 모든 연산을 무작정 FP8로 바꾸지 않는다.
- 큰 행렬 곱셈은 FP8 중심으로 처리한다.
- 민감한 연산은 BF16 또는 FP32로 유지한다.
- optimizer 상태와 master weight는 더 안정적인 정밀도로 관리한다.
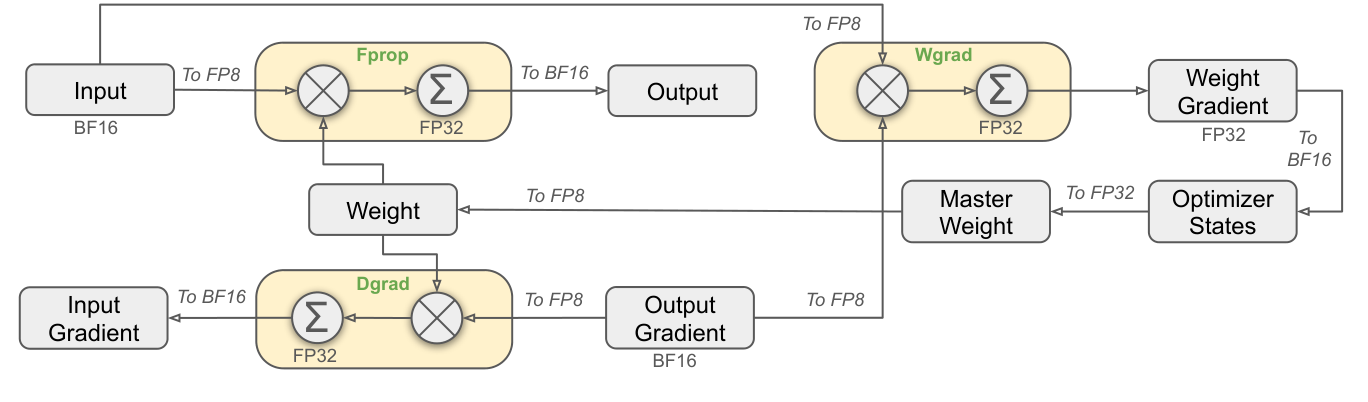
Crop 포인트: FP8이 주로 큰 계산 경로에 배치되고, 안정성이 필요한 지점에는 더 높은 정밀도가 남아 있다는 점이 핵심이다.
Fine-grained Quantization: 큰 이상값 하나에 전체가 흔들리지 않게 한다
저정밀 훈련의 문제는 outlier다.
일부 값이 너무 크면 전체 스케일이 그 값에 맞춰진다.
그러면 나머지 값의 정보가 손실된다.
DeepSeek-V3는 더 작은 단위로 스케일을 잡는다.
활성값과 가중치를 세밀한 그룹으로 나눠 양자화한다.
덕분에 특정 outlier가 전체 텐서를 망가뜨릴 가능성을 줄인다.
또한 중간 누적은 더 높은 정밀도로 보강한다.
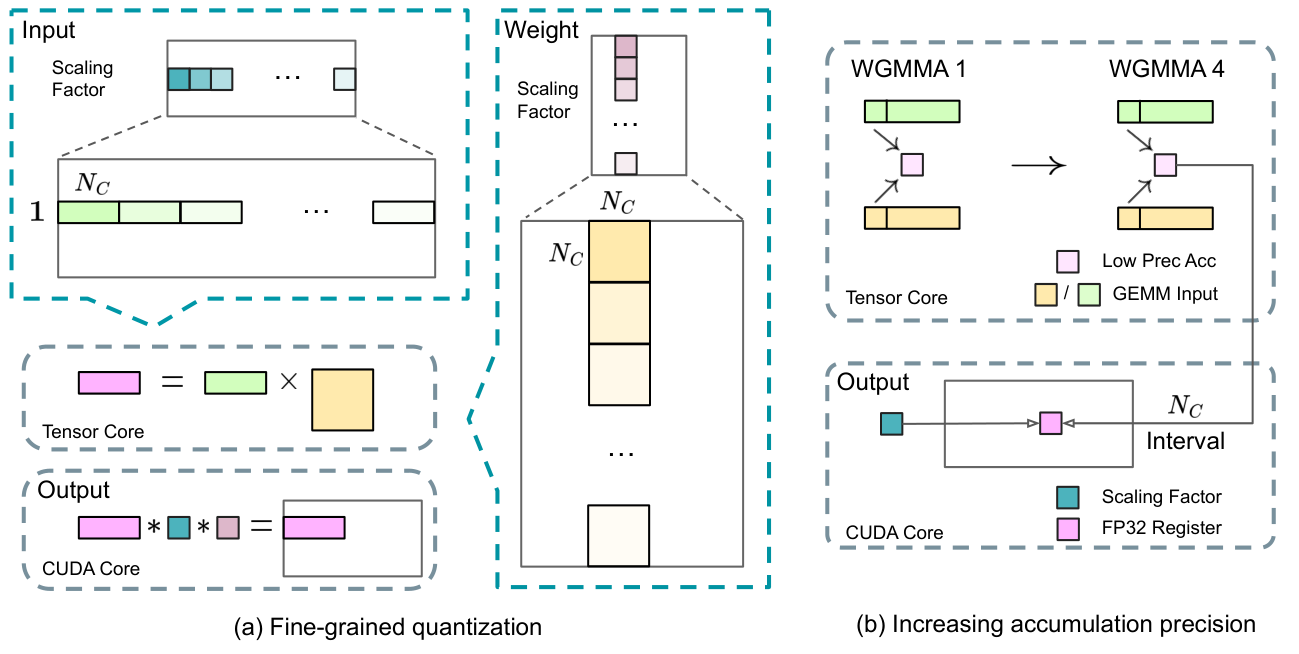
Crop 포인트: 왼쪽의 작은 그룹 단위 스케일링과 오른쪽의 고정밀 누적 흐름은 FP8의 속도 이점과 훈련 안정성을 동시에 잡기 위한 장치다.
논문은 FP8 훈련을 BF16 기준선과 비교했다.
상대 loss 차이는 실험 범위에서 매우 작게 유지됐다.
이는 FP8 훈련이 대형 모델에서도 실용적일 수 있음을 보여준다.
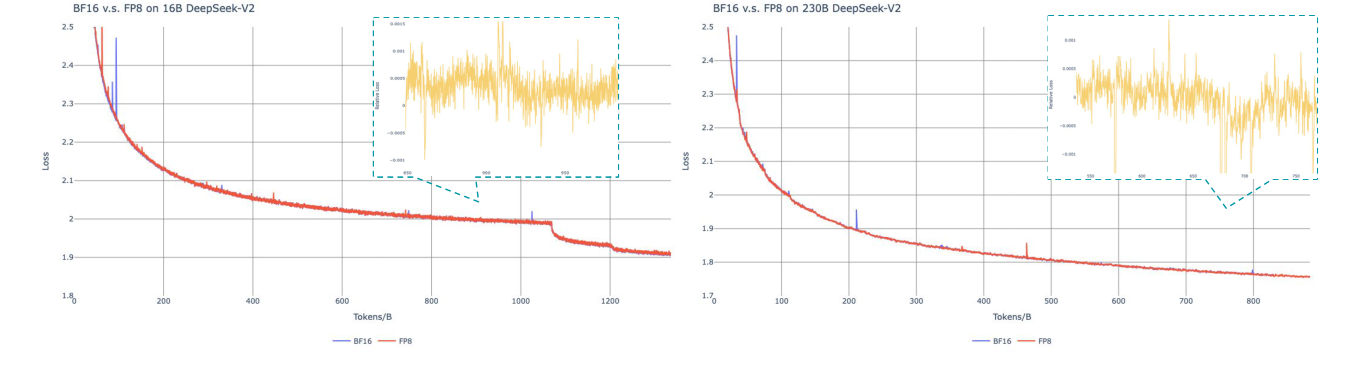
Crop 포인트: FP8과 BF16 곡선이 거의 함께 움직이는 구간은 저정밀 훈련이 성능 붕괴 없이 안정적으로 작동했음을 보여준다.
데이터와 프리트레이닝
DeepSeek-V3는 14.8T 토큰으로 프리트레이닝됐다.
데이터 구성에서 논문이 강조하는 변화는 다음과 같다.
- 수학 데이터 비중 강화
- 프로그래밍 데이터 비중 강화
- 영어와 중국어 외 다국어 커버리지 확대
- 중복 제거와 다양성 유지
- Fill-in-Middle 방식 포함
토크나이저는 byte-level BPE 기반이다.
어휘 크기는 128K다.
다국어 압축 효율을 개선하도록 pretokenizer와 훈련 데이터도 조정했다.
모델 규모와 훈련 설정
DeepSeek-V3의 기본 구성은 다음과 같다.
| 항목 | 내용 |
|---|---|
| 전체 파라미터 | 671B |
| 토큰당 활성 파라미터 | 37B |
| Transformer layer | 61 |
| MoE 구성 | 공유 전문가 1개, 라우팅 전문가 256개 |
| 토큰당 선택 전문가 | 라우팅 전문가 8개 |
| 프리트레이닝 토큰 | 14.8T |
| 최대 문맥 길이 | 128K까지 확장 |
훈련 비용은 다음과 같이 보고된다.
| 단계 | H800 GPU 시간 | 비용 추정 |
|---|---|---|
| Pre-training | 2.664M | 532.8만 달러 |
| Context extension | 119K | 23.8만 달러 |
| Post-training | 5K | 1만 달러 |
| Total | 2.788M | 557.6만 달러 |
이 비용은 공식 훈련 실행 기준이다.
연구 탐색 비용은 제외된다.
긴 문맥 확장: 4K에서 128K까지
DeepSeek-V3는 프리트레이닝 이후 두 단계로 문맥 길이를 늘렸다.
먼저 32K까지 확장한다.
그 다음 128K까지 확장한다.
긴 문맥 성능은 Needle In A Haystack 테스트로 확인했다.
이 테스트는 긴 문서 어딘가에 들어 있는 특정 정보를 잘 찾아내는지 보는 방식이다.
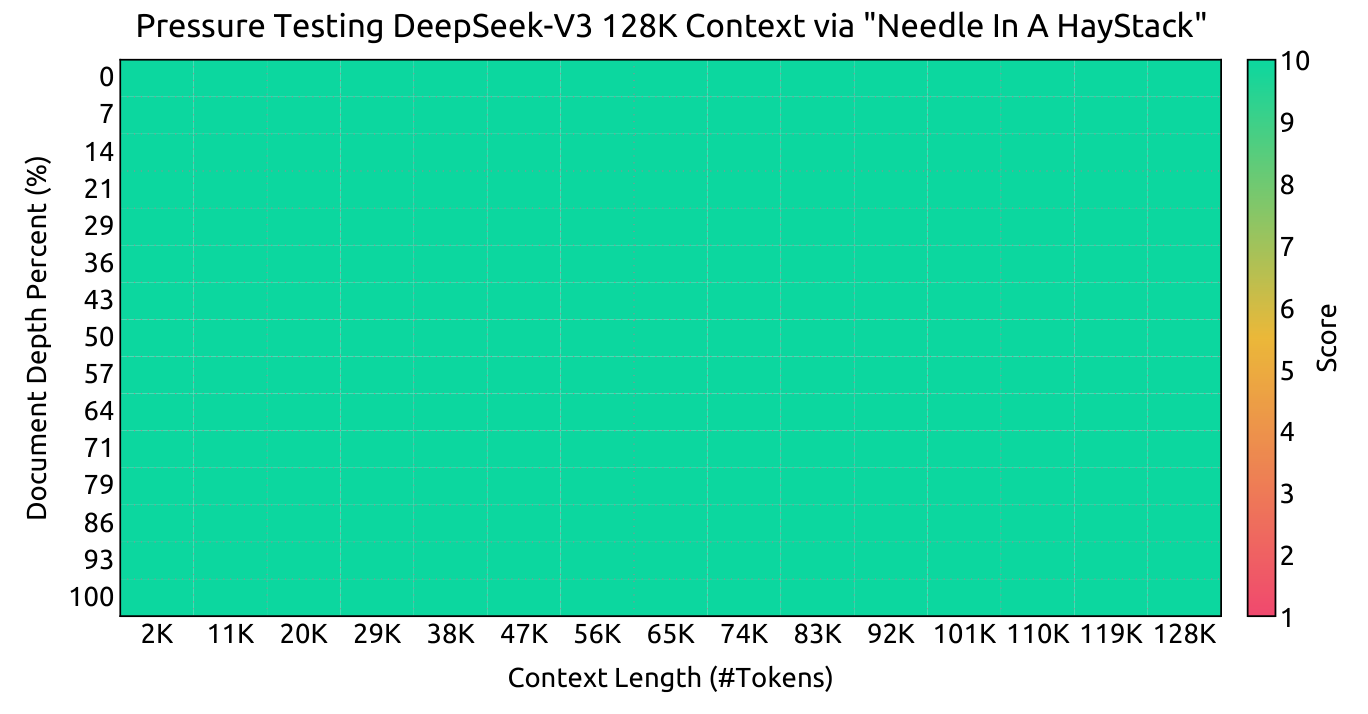
Crop 포인트: 거의 전체가 높은 점수 색으로 유지되는 구간은 128K 문맥에서도 정보 검색 성능이 크게 무너지지 않았음을 보여준다.
후처리: SFT, RL, 그리고 DeepSeek-R1 증류
프리트레이닝 이후에는 supervised fine-tuning과 reinforcement learning을 수행한다.
SFT 데이터는 약 1.5M 인스턴스다.
도메인별로 데이터 생성 방식을 다르게 썼다.
Reasoning 데이터
수학, 코드 대회, 논리 퍼즐 같은 reasoning 데이터는 내부 DeepSeek-R1 모델을 활용했다.
R1이 만든 데이터는 정확도가 높다.
하지만 길고, 과하게 생각하며, 형식이 불안정할 수 있다.
DeepSeek-V3의 목표는 둘 사이의 균형이다.
- R1의 높은 추론 정확도
- 일반 챗 모델의 간결하고 읽기 쉬운 답변
논문은 R1의 검증과 반성 패턴을 V3에 증류하되, 출력 길이는 통제하려고 했다고 설명한다.
RL: 검증 가능한 문제와 열린 문제를 나눠 다룬다
보상 모델은 두 종류다.
- Rule-based reward
수학 정답, 코드 테스트처럼 자동 검증 가능한 문제에 사용한다. - Model-based reward
창작, 역할극, 자유형 답변처럼 정답이 하나로 고정되지 않는 문제에 사용한다.
RL 알고리즘은 GRPO를 사용한다.
핵심 직관은 다음과 같다.
한 질문에서 여러 답을 뽑고, 그 그룹 안에서 상대적으로 좋은 답을 더 강화한다.
이 방식은 별도의 거대한 critic 모델 부담을 줄이는 데 유리하다.
평가 결과: 공개 모델의 상한을 끌어올렸다
논문은 base model과 chat model을 나눠 평가한다.
Base model
DeepSeek-V3-Base는 공개 base model들과 비교된다.
비교 대상은 DeepSeek-V2-Base, Qwen2.5 72B Base, LLaMA-3.1 405B Base다.
논문은 DeepSeek-V3-Base가 대부분의 벤치마크에서 가장 좋은 성능을 보였다고 보고한다.
특히 코드와 수학에서 강하다.
대표 결과는 다음과 같다.
- HumanEval: 65.2
- MBPP: 75.4
- LiveCodeBench-Base: 19.4
- GSM8K: 89.3
- MATH: 61.6
- CMath: 90.7
- MMMLU non-English: 79.4
Chat model
Chat 모델은 공개 모델뿐 아니라 GPT-4o, Claude-3.5-Sonnet과도 비교된다.
DeepSeek-V3는 공개 모델 중 최상위 성능을 보인다.
닫힌 모델과도 여러 벤치마크에서 경쟁 가능한 수준을 보인다.
대표 결과는 다음과 같다.
| 영역 | DeepSeek-V3 결과 |
|---|---|
| MMLU | 88.5 |
| MMLU-Pro | 75.9 |
| GPQA-Diamond | 59.1 |
| DROP | 91.6 |
| LongBench v2 | 48.7 |
| HumanEval-Mul | 82.6 |
| LiveCodeBench | 37.6 |
| Codeforces | 51.6 |
| SWE-bench Verified | 42.0 |
| AIME 2024 | 39.2 |
| MATH-500 | 90.2 |
| CNMO 2024 | 43.2 |
| C-SimpleQA | 64.8 |
주목할 점은 수학이다.
MATH-500과 AIME 2024에서 강한 성과를 보인다.
논문은 이를 DeepSeek-R1 기반 추론 증류의 효과로 해석한다.
Open-ended 평가
Arena-Hard와 AlpacaEval 2.0에서도 강한 결과를 보고한다.
DeepSeek-V3는 Arena-Hard에서 Claude-Sonnet-3.5와 유사한 수준의 승률을 보인다.
AlpacaEval 2.0에서는 길이 통제 기준으로 매우 높은 점수를 기록한다.
이는 단순 지식형 문제뿐 아니라 글쓰기, 지시 따르기, 복합 프롬프트 대응에서도 개선이 있었음을 시사한다.
Ablation: 무엇이 실제로 효과가 있었나
논문은 주요 설계 요소를 제거하거나 바꿔 비교한다.
MTP의 효과
MTP를 붙인 모델은 대부분의 벤치마크에서 baseline보다 나았다.
추론 시 MTP 모듈을 버리면 비용은 동일하다.
즉, 훈련 때만 더 강한 학습 신호를 주고, 추론 비용은 늘리지 않는 구조다.
Auxiliary-loss-free balancing의 효과
보조 손실 기반 균형 조정과 비교했을 때, auxiliary-loss-free 방식은 더 나은 성능을 보였다.
논문은 그 이유를 전문가 특화에서 찾는다.
sequence 단위로 너무 강하게 균형을 맞추면 모든 전문가가 비슷하게 쓰이기 쉽다.
batch 단위로 더 유연하게 맞추면 전문가가 도메인별 역할을 나눌 여지가 생긴다.

Crop 포인트: auxiliary-loss-free 행에서 특정 도메인과 전문가가 더 강하게 연결되는 패턴은 균형을 맞추면서도 전문가 특화를 허용한다는 논문의 주장을 뒷받침한다.
FP8의 효과
FP8은 훈련 비용과 메모리 사용량을 줄인다.
하지만 잘못 쓰면 훈련이 불안정해질 수 있다.
DeepSeek-V3는 세밀한 양자화와 고정밀 누적으로 이를 완화했다.
논문은 BF16과의 loss 차이가 실험 범위에서 작게 유지됐다고 보고한다.
논문의 핵심 직관
DeepSeek-V3의 메시지는 단순하다.
모델 성능은 파라미터 수만으로 결정되지 않는다.
중요한 것은 공동 설계다.
- 아키텍처
- 데이터
- 훈련 목표
- 병렬화 전략
- 통신 커널
- 정밀도 관리
- 후처리 증류
이들이 하나의 시스템으로 맞물려야 한다.
DeepSeek-V3는 “큰 모델”이라기보다 “큰 모델을 감당할 수 있게 만든 시스템”에 가깝다.
한계
논문도 한계를 인정한다.
첫째, 배포 단위가 크다.
권장 inference deployment unit이 작지 않다.
소규모 팀에는 부담이 될 수 있다.
둘째, 생성 속도 개선 여지가 남아 있다.
DeepSeek-V2 대비 end-to-end generation speed는 2배 이상 개선됐다고 설명하지만, 추가 최적화 가능성을 남겨둔다.
셋째, 모든 벤치마크에서 닫힌 모델을 앞서는 것은 아니다.
예를 들어 영어 factuality 성격의 SimpleQA에서는 GPT-4o와 Claude 계열보다 낮다.
대신 중국어 factuality 벤치마크에서는 강한 결과를 보인다.
앞으로의 방향
논문은 향후 연구 방향을 네 가지로 제시한다.
- 더 효율적인 아키텍처
- 더 넓고 좋은 데이터
- 더 깊은 reasoning 능력
- 더 종합적인 평가 체계
특히 무한에 가까운 문맥 길이 지원과 Transformer 한계 극복을 장기 목표로 언급한다.
정리
DeepSeek-V3는 세 가지 관점에서 의미가 있다.
첫째, 공개 모델의 성능 상한을 끌어올렸다.
둘째, MoE와 MLA를 통해 대형 모델의 계산 비용을 줄였다.
셋째, FP8과 DualPipe를 통해 훈련 시스템 자체를 성능의 핵심 요소로 만들었다.
이 논문은 모델 아키텍처 논문이면서 동시에 대규모 시스템 엔지니어링 보고서다.
가장 중요한 메시지는 다음과 같다.
다음 세대 LLM 경쟁은 모델 크기 경쟁이 아니라, 모델·데이터·시스템을 함께 설계하는 경쟁이다.
Source
- DeepSeek-AI. DeepSeek-V3 Technical Report. arXiv:2412.19437v2, 18 Feb 2025. https://arxiv.org/abs/2412.19437
- Model checkpoints: https://github.com/deepseek-ai/DeepSeek-V3
'AI 생성 글 정리 > modeling' 카테고리의 다른 글
| [Switch Transformers] 논문 정리 (0) | 2026.04.21 |
|---|---|
| [Mixtral of Experts] 논문 정리 (0) | 2026.04.21 |
| DeepSeek-R1 논문 정리 (1) | 2026.04.21 |
| Training Language Models to Self-Correct via Reinforcement Learning 논문 정리 (0) | 2026.04.21 |
| [STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning] 논문 정리 (1) | 2026.04.21 |



