핵심 한 줄
ReasoningBank는 LLM 에이전트가
성공 경험뿐 아니라 실패 경험에서도 재사용 가능한 추론 전략을 뽑아내는 메모리 프레임워크다.
핵심 메시지는 명확하다.
- 과거 궤적을 그대로 저장하는 것은 부족하다.
- 성공한 절차만 저장해도 부족하다.
- 실패에서 얻은 예방 전략까지 추상화해야 한다.
- 이렇게 만든 메모리는 테스트 시점 스케일링과 결합될 때 더 강해진다.

Crop 포인트: 오른쪽 성능 곡선에서 ReasoningBank가 작업이 누적될수록 No Memory보다 더 많은 성공을 쌓는 흐름에 주목하면 된다.

왜 이 논문이 중요한가
LLM 에이전트는 점점 더 긴 시간 동안 실제 환경에서 일한다.
예를 들면 다음과 같다.
- 웹사이트 탐색
- 쇼핑몰 주문 조회
- GitLab 이슈 처리
- 코드 저장소 버그 수정
- 반복적인 운영 업무 자동화
문제는 대부분의 에이전트가 매번 처음부터 다시 푼다는 점이다.
같은 실수를 반복한다.
비슷한 작업에서 얻은 힌트도 버린다.
결국 오래 사용해도 스스로 좋아지지 않는다.
이 논문은 이 문제를 “메모리”로 푼다.
다만 단순 기록장이 아니다.
ReasoningBank는 경험을 압축해 전략 단위의 기억으로 바꾼다.
기존 메모리 방식의 한계
논문은 기존 에이전트 메모리를 크게 두 흐름으로 본다.
첫째, Trajectory Memory다.
과거 행동 기록을 그대로 저장한다.
장점은 정보가 많다는 것이다.
단점은 너무 길고, 시끄럽고, 현재 작업에 바로 쓰기 어렵다는 것이다.
둘째, Workflow Memory다.
성공한 절차를 워크플로로 저장한다.
장점은 재사용이 쉽다는 것이다.
단점은 실패에서 배우지 못하고, 상황이 조금만 바뀌어도 유연성이 떨어진다는 것이다.
ReasoningBank는 이 둘 사이에서 다른 선택을 한다.
행동 로그가 아니라 왜 성공했는지, 왜 실패했는지를 기억한다.
ReasoningBank의 기본 아이디어
ReasoningBank의 메모리 항목은 세 부분으로 구성된다.
| 구성 | 의미 |
|---|---|
| Title | 전략을 짧게 부르는 이름 |
| Description | 언제 쓰는 전략인지 한 문장으로 설명 |
| Content | 실제 의사결정에 도움이 되는 추론 힌트 |
이 구조는 사람도 읽을 수 있고, 에이전트도 프롬프트 안에서 바로 쓸 수 있다.
중요한 점은 메모리의 원천이다.
ReasoningBank는 두 종류의 경험을 모두 쓴다.
- 성공 궤적: 검증된 전략을 추출
- 실패 궤적: 반복하면 안 되는 함정과 예방 규칙을 추출
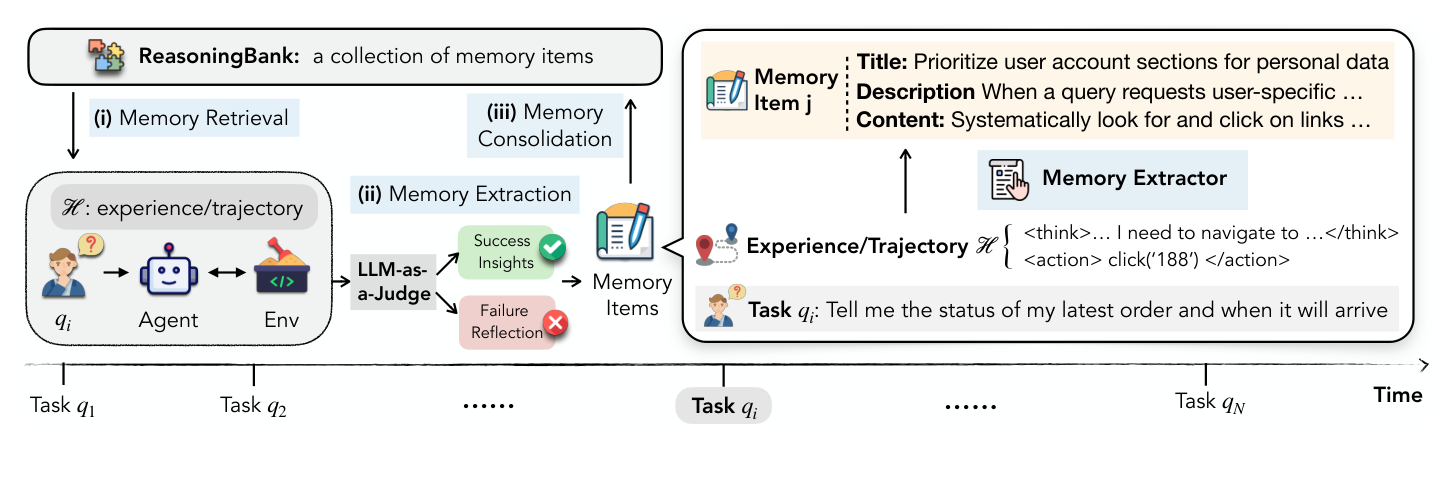
Crop 포인트: 왼쪽의 검색·추출·통합 루프가 ReasoningBank의 핵심이며, 작업이 끝날 때마다 새 경험이 다시 메모리로 들어간다.
작동 흐름
ReasoningBank는 테스트 중에 계속 갱신된다.
흐름은 간단하다.
- 새 작업이 들어온다.
- 현재 작업과 관련 있는 과거 메모리를 검색한다.
- 검색된 메모리를 에이전트 지시문에 넣는다.
- 에이전트가 환경과 상호작용한다.
- 작업이 끝나면 LLM-as-a-Judge가 성공 또는 실패를 판단한다.
- 성공이면 좋은 전략을 뽑는다.
- 실패이면 실패 원인과 예방 전략을 뽑는다.
- 새 메모리를 ReasoningBank에 추가한다.
수식으로 보면 복잡해 보이지만, 직관은 단순하다.
에이전트가 과거의 시행착오를 짧은 조언 카드로 바꾸고, 다음 작업에서 그 카드를 참고하는 방식이다.
MaTTS: 메모리-aware 테스트 시점 스케일링
논문은 ReasoningBank를 더 강하게 만드는 방법도 제안한다.
이름은 MaTTS다.
풀어 쓰면 Memory-aware Test-Time Scaling이다.
일반적인 테스트 시점 스케일링은 한 작업에 더 많은 추론 비용을 쓴다.
예를 들면 여러 번 시도하거나, 한 답을 다시 점검한다.
하지만 그냥 많이 시도한다고 좋은 메모리가 생기지는 않는다.
MaTTS는 여러 시도를 메모리 품질을 높이는 재료로 쓴다.
방식은 두 가지다.
| 방식 | 설명 | 메모리에 주는 신호 |
|---|---|---|
| 병렬 스케일링 | 같은 작업을 여러 경로로 동시에 시도 | 성공 경로와 실패 경로를 비교 |
| 순차 스케일링 | 하나의 경로를 반복적으로 재검토 | 중간 수정과 자기 점검을 기록 |
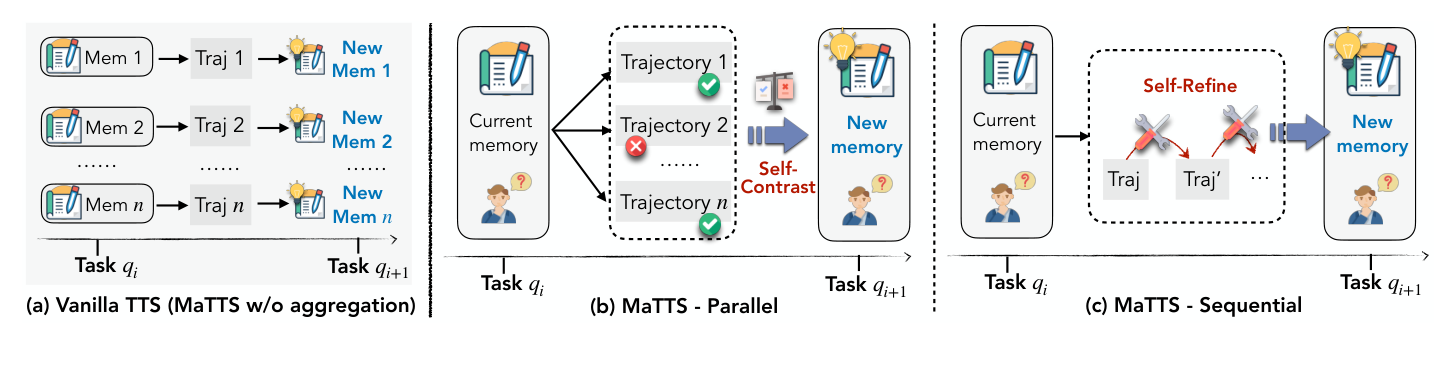
Crop 포인트: 가운데 병렬 구조에서는 여러 궤적을 서로 비교하고, 오른쪽 순차 구조에서는 같은 궤적을 다시 점검하며 메모리를 만든다.
실험 환경
논문은 세 가지 유형의 벤치마크에서 평가했다.
| 벤치마크 | 작업 유형 | 핵심 평가 |
|---|---|---|
| WebArena | 실제 웹사이트 탐색 | 성공률, 평균 단계 수 |
| Mind2Web | 웹 일반화 능력 | 요소 선택, 행동 정확도, 작업 성공률 |
| SWE-Bench-Verified | 저장소 수준 버그 수정 | 이슈 해결률, 평균 단계 수 |
사용한 주요 모델은 다음과 같다.
- Gemini-2.5-flash
- Gemini-2.5-pro
- Claude-3.7-sonnet
- Gemma-3-12B-Instruct
비교 대상은 세 가지다.
- No Memory: 메모리 없음
- Synapse: 과거 궤적을 예시로 저장
- AWM: 성공한 워크플로를 저장
- ReasoningBank: 성공과 실패에서 추론 전략을 추출
주요 결과: 성능과 효율이 함께 오른다
WebArena에서 ReasoningBank는 모든 백본 모델에서 No Memory보다 높은 성공률을 보였다.
| 모델 | No Memory | ReasoningBank | ReasoningBank + MaTTS |
|---|---|---|---|
| Gemini-2.5-flash | 40.5% | 48.8% | 51.8% |
| Gemini-2.5-pro | 46.7% | 53.9% | 56.3% |
| Claude-3.7-sonnet | 41.7% | 46.3% | 48.8% |
성공률만 오른 것이 아니다.
평균 상호작용 단계도 줄었다.
Gemini-2.5-pro 기준 WebArena 전체 평균 단계는 다음과 같다.
| 방식 | 평균 단계 수 |
|---|---|
| No Memory | 8.8 |
| Synapse | 8.5 |
| AWM | 8.7 |
| ReasoningBank | 7.4 |
| ReasoningBank + MaTTS | 7.1 |
즉, ReasoningBank는 더 많이 맞히면서도 덜 헤맨다.
MaTTS 결과: 많이 시도하되, 메모리로 정리해야 한다
WebArena-Shopping 실험에서 MaTTS는 시도 횟수가 늘어날수록 성능을 높였다.
병렬 스케일링에서는 ReasoningBank 기반 MaTTS가 49.7%에서 55.1%까지 상승했다.
순차 스케일링도 49.7%에서 54.5%까지 올랐다.
반면 메모리 없는 스케일링은 개선 폭이 작고 불안정했다.

Crop 포인트: 파란 실선인 MaTTS가 회색 막대인 메모리 없는 스케일링보다 꾸준히 위에 있는 점이 핵심이다.
메모리와 스케일링의 시너지
논문의 중요한 주장 중 하나는 이것이다.
좋은 메모리는 스케일링을 더 잘하게 만들고, 스케일링은 더 좋은 메모리를 만든다.
WebArena-Shopping에서 다섯 번 병렬 시도한 결과를 보면 차이가 크다.
| 메모리 방식 | No Scaling | 다중 시도 후 최선 결과 |
|---|---|---|
| No Memory | 39.0% | 42.2% |
| Synapse | 40.6% | 44.4% |
| AWM | 44.4% | 47.6% |
| ReasoningBank | 49.7% | 55.1% |
ReasoningBank는 출발점도 높고, 스케일링을 붙였을 때 상승 폭도 크다.

Crop 포인트: ReasoningBank 구간에서 분홍색 Pass@1과 파란색 Best-of-5가 모두 가장 높은 점을 보면 메모리와 스케일링의 양방향 효과가 드러난다.
흥미로운 분석: 메모리가 점점 추상화된다
ReasoningBank의 메모리는 단순히 쌓이기만 하지 않는다.
시간이 지나면서 더 추상적인 전략으로 발전한다.
초기에는 실행 규칙에 가깝다.
예를 들면 “다음 페이지를 눌러라” 같은 수준이다.
이후에는 자기 점검이 붙는다.
예를 들면 “클릭 전 요소 식별자를 다시 확인하라”는 식이다.
더 많은 경험이 쌓이면 복합 전략으로 바뀐다.
예를 들면 “현재 화면이 사용자 요구와 맞지 않으면 검색 필터, 페이지 이동, 대체 섹션을 다시 검토하라”는 수준이다.

Crop 포인트: 왼쪽의 절차적 전략에서 오른쪽의 교차 확인·재평가 전략으로 이동하는 흐름이 메모리 진화의 핵심이다.
실패 경험을 넣었을 때 더 강해진다
이 논문에서 가장 실용적인 부분은 실패 궤적 활용이다.
ReasoningBank는 실패를 노이즈로만 보지 않는다.
실패 원인을 분석해 “다음에는 피해야 할 규칙”으로 만든다.
WebArena-Shopping 결과는 다음과 같다.
| 방식 | 성공 궤적만 사용 | 실패 궤적도 사용 |
|---|---|---|
| Synapse | 40.6% | 41.7% |
| AWM | 44.4% | 42.2% |
| ReasoningBank | 46.5% | 49.7% |
AWM은 실패를 넣으면 오히려 떨어진다.
ReasoningBank는 실패를 전략으로 바꾸기 때문에 오른다.

Crop 포인트: ReasoningBank의 실패 포함 막대가 성공 전용 막대보다 높아지는 구간이 이 논문의 차별점을 보여준다.
LLM-as-a-Judge가 완벽하지 않아도 버틴다
ReasoningBank는 궤적의 성공·실패를 LLM-as-a-Judge로 판단한다.
당연히 이 판단은 완벽하지 않을 수 있다.
논문은 이를 검증하기 위해 판단 정확도를 일부러 낮춘 실험을 했다.
결과적으로 70~90% 수준의 판단 정확도에서는 성능이 크게 흔들리지 않았다.
이는 실무적으로 중요하다.
정답 라벨이 없는 환경에서도 어느 정도 견고하게 쓸 수 있다는 뜻이다.

Crop 포인트: 가운데 붉은 점선 영역에서 판단 정확도가 달라져도 성공률이 비슷하게 유지되는 점을 보면 된다.
여러 후보를 만들수록 성공 후보를 더 잘 포함한다
병렬 스케일링의 또 다른 장점은 좋은 후보를 포함할 확률이 높아진다는 점이다.
MaTTS는 단순히 후보를 많이 만드는 데서 끝나지 않는다.
메모리를 이용해 더 유망한 방향으로 후보를 만든다.
그래서 시도 횟수가 늘어날수록 성공 후보를 포함할 가능성이 더 크게 올라간다.

Crop 포인트: 진한 파란 삼각형 선이 오른쪽으로 갈수록 가장 크게 상승하며, 메모리-aware 스케일링의 표본 효율을 보여준다.
사례 1: 최신 주문만 보고 틀리는 문제를 피한다
사용자가 “첫 구매 날짜”를 묻는다고 하자.
메모리 없는 에이전트는 최근 주문 표만 보고 답한다.
그래서 첫 구매가 아니라 최근 구매 날짜를 말한다.
ReasoningBank는 다르게 행동한다.
과거 메모리에서 “전체 주문 내역을 확인해야 한다”는 힌트를 가져온다.
그 결과 전체 주문 페이지로 이동하고, 더 이른 구매 날짜를 찾는다.

Crop 포인트: 위쪽 Baseline은 Recent Orders에 머물지만, 아래쪽 ReasoningBank는 My Orders와 다음 페이지까지 확인한다.
사례 2: 불필요한 탐색 단계를 줄인다
쇼핑몰에서 조건에 맞는 남성 신발을 찾아 구매하는 작업도 있다.
메모리 없는 에이전트는 필터 위치를 찾지 못해 많은 단계를 소비한다.
ReasoningBank는 과거의 카테고리 필터링 전략을 참고한다.
그 결과 같은 목표를 훨씬 적은 단계로 끝낸다.
논문 사례에서는 29단계가 10단계로 줄었다.
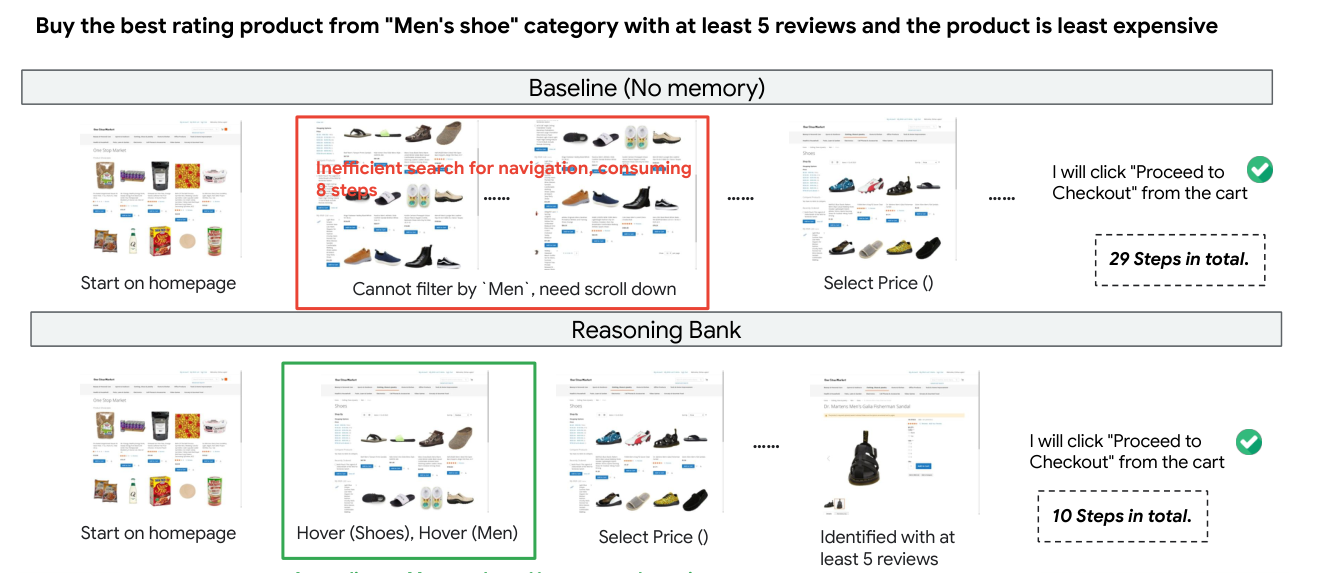
Crop 포인트: Baseline의 빨간 영역은 비효율적 탐색을, ReasoningBank의 초록 영역은 바로 필터링 경로를 잡는 차이를 보여준다.
사례 3: 실패를 검색 전략으로 바꾼다
블루투스 헤드폰 정보를 찾는 작업에서는 실패 원인이 분명했다.
검색어가 넓어 너무 많은 상품이 나왔다.
관련 없는 객체도 섞였다.
ReasoningBank는 이 실패를 다음 전략으로 바꿨다.
- 검색어를 더 정확하게 만들 것
- 한 페이지 표시 개수를 조정할 것
- 가능한 필터를 적극적으로 사용할 것
이런 기억은 다음 작업에서 같은 종류의 실패를 줄인다.
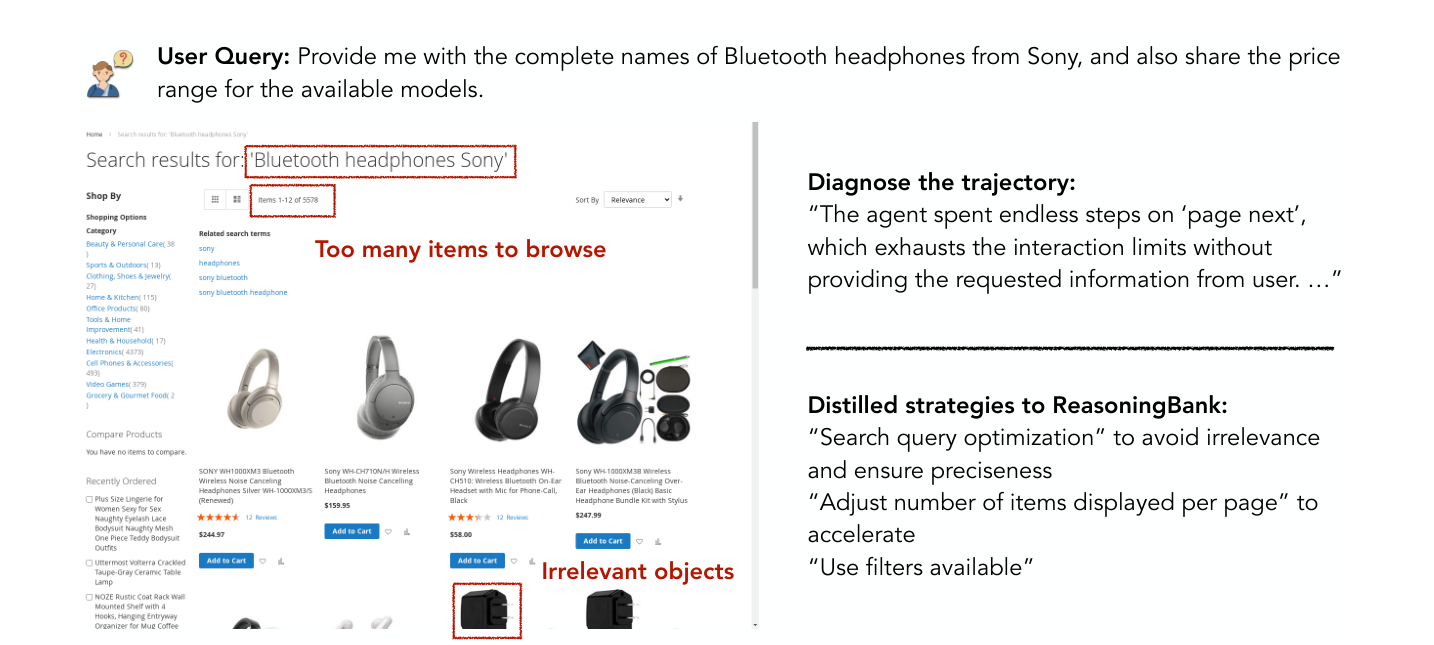
Crop 포인트: 왼쪽의 과도한 검색 결과와 오른쪽의 실패 진단·전략 추출 부분을 함께 보면 실패가 메모리로 바뀌는 과정이 보인다.
이 논문의 기여
ReasoningBank의 기여는 세 가지로 정리된다.
1. 메모리의 단위를 바꿨다
과거 로그를 그대로 저장하지 않는다.
성공 절차만 저장하지도 않는다.
대신 일반화 가능한 추론 전략을 저장한다.
2. 실패를 학습 신호로 썼다
실패 궤적은 버릴 데이터가 아니다.
어떤 행동이 잘못됐는지 알려주는 반례다.
ReasoningBank는 이 반례를 예방 전략으로 바꾼다.
3. 메모리와 테스트 시점 스케일링을 연결했다
추가 계산은 더 많은 시행착오를 만든다.
ReasoningBank는 그 시행착오를 더 좋은 메모리로 정리한다.
다음 작업에서는 그 메모리가 다시 더 나은 탐색을 유도한다.
한계
논문도 한계를 분명히 인정한다.
메모리 구조 자체는 단순하다
검색은 임베딩 기반 유사도 검색에 가깝다.
통합도 새 항목을 추가하는 방식에 가깝다.
고급 병합, 삭제, 계층화는 깊게 다루지 않는다.
LLM-as-a-Judge에 의존한다
성공과 실패 판단은 자동 평가 모델에 맡긴다.
판단이 틀리면 잘못된 메모리가 들어갈 수 있다.
논문은 견고성을 보였지만, 실제 서비스에서는 더 강한 검증기가 필요할 수 있다.
장기 메모리 운영 문제는 남아 있다
메모리가 계속 쌓이면 충돌하거나 중복될 수 있다.
어떤 기억을 보존하고, 어떤 기억을 잊을지에 대한 정책은 후속 연구가 필요하다.
실무적 시사점
ReasoningBank는 LLM 에이전트를 운영하는 관점에서 꽤 현실적인 방향을 제시한다.
핵심은 “더 큰 모델”만이 아니다.
에이전트가 이미 겪은 일을 어떻게 저장하느냐도 중요하다.
특히 다음 환경에서 유용하다.
- 반복 업무가 많은 웹 자동화
- 고객 계정 기반 정보 탐색
- 운영 콘솔 작업
- 코드 수정 에이전트
- 장기적으로 개선되어야 하는 사내 에이전트
실무 적용 시에는 다음 설계가 중요해 보인다.
- 성공과 실패를 모두 기록할 것
- 원본 로그보다 짧은 전략 메모리를 만들 것
- 메모리 검색 결과를 프롬프트에 넣되, 관련성이 낮은 항목은 줄일 것
- 다중 시도 결과를 단순 투표가 아니라 메모리 개선에 사용할 것
- 메모리 품질을 주기적으로 점검할 것
결론
ReasoningBank는 에이전트 메모리를 “과거 기록”에서 “추론 전략 저장소”로 바꾼다.
이 변화가 중요하다.
LLM 에이전트가 장기적으로 유용해지려면 단순히 작업을 수행하는 데서 끝나면 안 된다.
작업 후에 배워야 한다.
성공에서는 절차를 얻고, 실패에서는 경고를 얻어야 한다.
ReasoningBank는 그 과정을 테스트 시점에 닫힌 루프로 만든다.
MaTTS는 이 루프를 더 빠르게 돌린다.
그래서 이 논문은 에이전트 성능 향상의 새로운 축을 제안한다.
그 축은 모델 크기나 프롬프트 기교가 아니라, 경험을 메모리로 바꾸는 능력이다.
Source
- Paper: ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
- Authors: Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, Tomas Pfister
- arXiv: 2509.25140v2
- Version date: 16 Mar 2026
- Paper link: https://arxiv.org/abs/2509.25140
- Code: https://github.com/google-research/reasoning-bank



