핵심 요약
AgentArk는 여러 LLM 에이전트가 토론하며 얻는 추론 능력을 하나의 LLM에 증류하는 프레임워크다.
목표는 단순하다.
- 추론 성능은 멀티 에이전트에 가깝게 유지한다.
- 추론 비용은 단일 모델 수준으로 낮춘다.
- 답만 모방하지 않고, 검토·비판·수정의 과정을 모델 내부에 학습시킨다.
이 논문의 핵심 메시지는 다음과 같다.
멀티 에이전트 시스템의 진짜 가치는 “여러 명이 말한다”는 구조가 아니라, 그 구조가 만들어내는 추론 동역학에 있다.

Crop 포인트: 오른쪽의 효율성·추론·강건성 아이콘은 AgentArk가 단일 모델에 옮기려는 멀티 에이전트의 핵심 이점을 압축해 보여준다.

왜 이 연구가 필요한가
멀티 에이전트 시스템은 복잡한 추론에서 강하다.
여러 모델이 서로의 답을 보고, 반박하고, 수정한다.
이 과정에서 다음 능력이 생긴다.
- 다양한 가설 탐색
- 논리 오류 발견
- 중간 계산 검증
- 최종 답의 합의
하지만 비용이 크다.
에이전트 수가 늘고, 대화 라운드가 길어질수록 추론 지연이 커진다.
GPU 사용량도 증가한다.
실시간 서비스나 온디바이스 환경에는 부담이 된다.
문제는 비용만이 아니다.
잘못된 추론이 한 에이전트에서 시작되면, 토론 과정에서 다른 에이전트에게 전파될 수 있다.
그 결과, 오류가 집단적으로 증폭될 위험도 있다.
논문은 이 질문에서 출발한다.
멀티 에이전트의 추론 이점을 단일 모델이 내부화할 수 있을까?
AgentArk의 핵심 아이디어
AgentArk는 추론 비용을 “테스트 시점”에서 “학습 시점”으로 옮긴다.
기존 멀티 에이전트 방식은 추론할 때마다 여러 모델을 호출한다.
AgentArk는 먼저 멀티 에이전트 토론 데이터를 만든다.
그다음, 그 안에 담긴 좋은 추론 흐름을 하나의 학생 모델에 학습시킨다.
즉, 배포 시점에는 단일 모델만 실행한다.
하지만 학습 과정에서 멀티 에이전트가 만든 검토와 수정 패턴을 흡수한다.
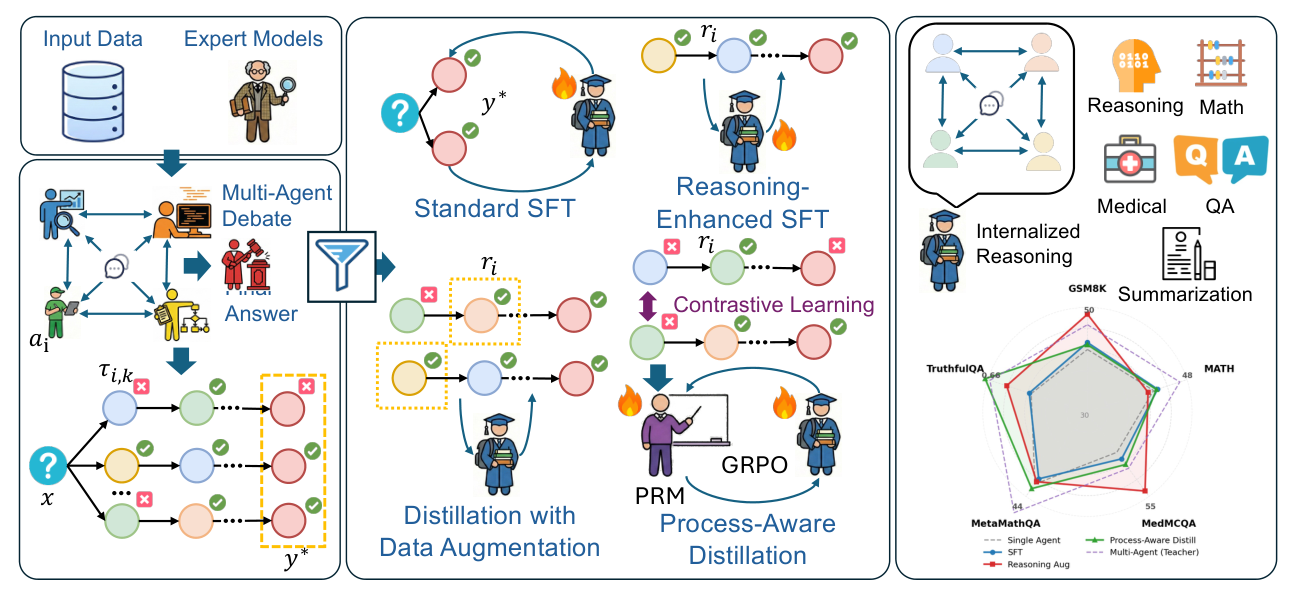
Crop 포인트: 가운데의 세 가지 증류 경로는 AgentArk가 최종 답이 아니라 추론 과정 자체를 단계적으로 학습시키는 방식을 보여준다.
AgentArk의 전체 흐름은 세 단계다.
1. 멀티 에이전트 토론 데이터 생성
하나의 문제를 여러 에이전트가 동시에 푼다.
각 에이전트는 처음에는 독립적으로 답을 낸다.
이후 라운드에서는 다른 에이전트의 추론을 참고한다.
이 과정에서 다음 데이터가 생긴다.
- 초기 추론
- 반박과 검토
- 수정된 추론
- 최종 합의 답변
2. 지식 추출
모든 토론 로그를 그대로 쓰지는 않는다.
논문은 정답에 도달한 추론 경로를 우선적으로 고른다.
특히 중요한 것은 “처음에는 틀렸지만, 비판을 받고 올바른 답으로 전환한 경로”다.
이런 경로는 단순 정답보다 더 풍부하다.
모델이 오류를 어떻게 발견하고 수정해야 하는지 보여주기 때문이다.
3. 계층적 증류
선별된 추론 데이터를 학생 모델에 학습시킨다.
논문은 세 가지 증류 전략을 비교한다.
세 가지 증류 전략
RSFT: 추론이 포함된 지도 미세조정
RSFT는 최종 답뿐 아니라 중간 추론도 함께 학습시킨다.
일반적인 지도 미세조정은 질문과 정답만 본다.
RSFT는 여기에 “정답에 이르는 설명 흐름”을 추가한다.
효과는 명확하다.
학생 모델은 정답 패턴만 외우는 대신, 답을 도출하는 구조를 따라 하게 된다.
한계도 있다.
RSFT는 기본적으로 좋은 추론을 모방한다.
하지만 추론 중 발생한 갈등, 반박, 수정의 동역학까지 깊게 학습하기는 어렵다.
DA: 다양한 정답 추론 경로 증강
DA는 같은 문제에 대해 여러 개의 올바른 추론 경로를 보존한다.
정답은 같아도 풀이 방식은 다를 수 있다.
어떤 에이전트는 직접 계산한다.
다른 에이전트는 조건을 재구성한다.
또 다른 에이전트는 중간 검산을 더 강조한다.
DA는 이런 다양성을 학습 데이터로 활용한다.
목표는 하나다.
하나의 문제를 여러 방식으로 풀 수 있는 모델을 만드는 것.
다만, 다양성이 항상 이득은 아니다.
학생 모델이 작으면 너무 많은 추론 스타일을 안정적으로 흡수하지 못할 수 있다.
PAD: 과정 인식 증류
PAD는 이 논문의 가장 중요한 전략이다.
핵심은 “어떤 답이 맞았는가”보다 “어떤 추론 단계가 타당했는가”를 학습시키는 것이다.
이를 위해 논문은 과정 보상 모델을 사용한다.
이 모델은 각 추론 단계가 얼마나 올바른지 평가한다.
그 후 학생 모델은 더 좋은 추론 단계를 선호하도록 강화 학습된다.
강화 학습 단계에서는 여러 답안을 한 묶음으로 비교한다.
같은 문제에 대해 생성된 답안들 중 더 좋은 과정을 가진 답안의 확률을 높인다.
반대로 낮은 품질의 추론은 덜 생성되도록 만든다.
직관적으로 말하면, PAD는 학생 모델에게 이런 행동을 가르친다.
- 문제를 작은 단계로 나누기
- 중간 결과를 확인하기
- 틀린 지점을 찾아내기
- 답을 내기 전에 논리 흐름을 정리하기
실험 설정
논문은 다양한 모델과 데이터셋에서 AgentArk를 평가한다.
사용한 모델 계열은 다음과 같다.
- Qwen3 계열
- Gemma 계열
- Llama3 계열
- Qwen2.5-VL 계열의 멀티모달 모델
주요 데이터셋은 다음과 같다.
- GSM8K: 수학 단어 문제
- MATH: 수학 추론
- MetaMathQA: 증강 수학 문제
- MedMCQA: 의학 객관식 문제
- HotpotQA: 다중 홉 질의응답
- QASPER: 논문 기반 장문 질의응답
- QMSum: 회의 요약
- TruthfulQA: 사실성·강건성 평가
주요 비교 대상은 단일 모델, 일반 멀티 에이전트 토론, 그리고 AgentArk의 세 증류 방식이다.
주요 결과 1: 단일 모델도 멀티 에이전트 추론 능력을 얻는다
AgentArk는 단일 에이전트의 성능을 전반적으로 끌어올렸다.
논문은 평균적으로 약 4.8%의 성능 향상을 보고한다.
성능은 일반 멀티 에이전트 토론보다 약간 낮지만, 추론 시에는 하나의 모델만 실행한다.
가장 안정적인 방법은 PAD였다.
RSFT와 DA도 일부 데이터셋에서 효과가 있었지만, 결과가 더 들쭉날쭉했다.
PAD는 내부 분포 데이터와 외부 분포 데이터 모두에서 더 일관된 향상을 보였다.

Crop 포인트: PAD 열의 막대들이 여러 모델과 데이터셋에서 비교적 안정적으로 상승하는 점이 핵심이다.
그림의 메시지는 두 가지다.
첫째, 같은 훈련 분포에서는 향상이 더 크다.
논문은 내부 분포에서 최대 30% 수준의 향상을 관찰했다.
외부 분포에서는 향상이 더 작았지만, 여전히 전이 효과가 있었다.
둘째, 모델 계열이 달라도 효과가 나타난다.
Qwen 교사 모델에서 얻은 추론 신호가 Llama와 Gemma 학생 모델에도 전달된다.
이는 AgentArk가 특정 모델 구조에만 맞춘 기법이 아님을 시사한다.
주요 결과 2: 학생 모델의 용량이 중요하다
멀티 에이전트 수를 늘리면 더 풍부한 토론 데이터가 생긴다.
하지만 항상 좋은 것은 아니다.
작은 학생 모델은 복잡한 추론 신호를 다 흡수하지 못한다.
Qwen3-0.6B에서는 에이전트 수를 늘려도 성능 향상이 제한적이었다.
일부 경우에는 오히려 성능이 떨어졌다.
반면 Qwen3-8B는 더 많은 에이전트의 신호를 어느 정도 활용했다.
다만, 에이전트 수가 계속 늘어도 증가폭은 점차 줄어들었다.
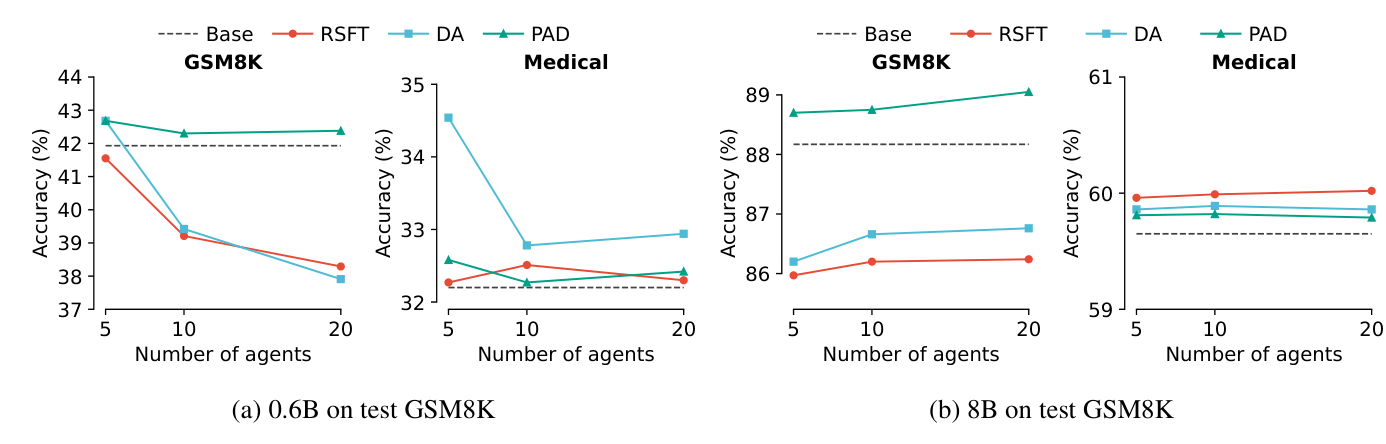
Crop 포인트: 왼쪽 0.6B 결과와 오른쪽 8B 결과의 차이는 “많은 교사 신호”가 학생 용량과 맞아야 효과적이라는 점을 보여준다.
이 결과는 실무적으로 중요하다.
작은 모델에 큰 멀티 에이전트 로그를 무작정 주입하는 것은 비효율적일 수 있다.
학생 모델 크기에 맞는 추론 난이도와 데이터 양을 조절해야 한다.
주요 결과 3: 데이터 양보다 추론 품질이 중요하다
논문은 학습 데이터 양을 늘리며 성능 변화를 확인했다.
결과는 단순하지 않았다.
RSFT와 DA는 데이터가 많아져도 성능이 꾸준히 좋아지지 않았다.
어떤 구간에서는 좋아졌지만, 다른 구간에서는 정체되거나 떨어졌다.
PAD는 더 안정적이었다.
과정 보상 모델이 고품질 추론 신호를 걸러주기 때문이다.

Crop 포인트: 학습 데이터 크기가 커져도 RSFT와 DA가 흔들리는 반면, PAD는 비교적 완만하고 안정적인 흐름을 보인다.
핵심은 다음과 같다.
작은 학생 모델에는 “많은 추론”보다 “잘 고른 추론”이 더 중요하다.
멀티 에이전트 토론 로그는 정보량이 많다.
하지만 그 안에는 중복, 장황한 설명, 불필요한 갈등도 있다.
AgentArk의 PAD는 이 중에서 학습에 유리한 과정 신호를 강조한다.
주요 결과 4: 정확도뿐 아니라 추론 행동이 바뀐다
논문은 성능 수치 외에도 추론 품질을 평가했다.
평가 기준은 네 가지다.
- 문제를 단계별로 나누는가
- 중간 결과를 검증하는가
- 오류 위치를 찾는가
- 전체 추론 흐름이 일관적인가
PAD는 특히 중간 검증과 추론 일관성에서 강했다.
DA는 다양한 풀이 경로를 학습해 오류 위치 탐지에서 일부 강점을 보였다.
RSFT는 기본 단일 모델보다 낫지만, 반성적 추론 행동을 충분히 만들지는 못했다.
이 결과는 AgentArk의 장점을 잘 보여준다.
AgentArk는 단순히 정답률만 올리는 방식이 아니다.
모델이 문제를 다루는 방식 자체를 바꾼다.
주요 결과 5: 수학 추론이 다른 작업으로 전이된다
AgentArk는 수학 데이터로 학습한 추론 능력이 다른 작업에도 전이되는지 확인했다.
평가 대상은 HotpotQA, QASPER, QMSum이다.
이 작업들은 단순 계산 문제가 아니다.
문서 이해, 다중 근거 연결, 요약 능력이 필요하다.
결과적으로 AgentArk는 특히 큰 모델에서 외부 작업 성능을 높였다.
QMSum처럼 긴 정보를 통합해야 하는 작업에서도 향상이 관찰됐다.

Crop 포인트: QASPER와 QMSum에서 모델 크기가 커질수록 AgentArk 적용 모델의 F1 상승이 더 뚜렷해진다.
부록의 추가 분석도 같은 방향을 보인다.
Qwen 계열에서는 8B 모델이 외부 분포 작업에서 더 안정적으로 이득을 얻었다.
0.6B 모델은 일부 작업에서 불안정했다.

Crop 포인트: 8B 구간에서 빨간 선이 회색 선보다 높게 유지되는 영역은 AgentArk의 전이 효과가 모델 용량과 함께 커진다는 점을 보여준다.
Llama3-8B에서도 외부 분포 성능 향상이 나타났다.
특히 QMSum의 F1 개선 폭이 크게 보고됐다.
이는 AgentArk가 한 모델 계열 안에서만 작동하는 현상이 아니라는 근거다.

Crop 포인트: QMSum-F1 셀의 큰 개선값은 AgentArk가 장문 통합형 작업에서도 추론 전이를 만들 수 있음을 보여준다.
주요 결과 6: 멀티모달 모델에도 확장된다
논문은 텍스트 LLM뿐 아니라 멀티모달 LLM에도 AgentArk를 적용했다.
교사 모델은 Qwen2.5-VL-32B-Instruct다.
학생 모델은 Qwen2.5-VL-3B-Instruct다.
훈련 데이터는 텍스트 중심 추론 데이터다.
그럼에도 멀티모달 학생 모델에서 성능 향상이 나타났다.
특히 PAD가 가장 강하거나 가장 안정적인 결과를 보였다.

Crop 포인트: PAD 막대가 두 설정에서 강하게 유지되는 점은 텍스트 기반 과정 증류가 멀티모달 모델의 내부 추론에도 영향을 줄 수 있음을 시사한다.
이 결과는 작지만 의미가 있다.
AgentArk가 학습시키는 것은 특정 입력 형식이 아니라 추론 습관에 가깝다.
따라서 텍스트에서 학습한 검토·수정 패턴이 멀티모달 모델에도 일부 재사용될 수 있다.
실무 관점에서의 의미
AgentArk는 추론 비용을 줄이는 방향의 연구다.
멀티 에이전트 토론은 강하지만 비싸다.
AgentArk는 그 비용을 학습 단계에서 한 번 지불한다.
배포 단계에서는 단일 모델만 사용한다.
논문이 보고한 학습 비용은 방법별로 차이가 있다.
- RSFT: 8B 학생 기준, H100 1장으로 약 6시간
- DA: H100 1장으로 약 8시간
- PAD: H100 8장으로 약 20시간
PAD는 학습 비용이 더 크다.
하지만 추론 시점에는 단일 모델 생성만 필요하다.
따라서 AgentArk는 다음 환경에 특히 적합하다.
- 추론 요청이 많은 서비스
- 지연 시간이 중요한 서비스
- 멀티 에이전트 호출 비용이 부담되는 환경
- 작은 모델을 더 강한 추론 모델로 만들고 싶은 환경
한계
논문도 몇 가지 한계를 인정한다.
첫째, 실험 범위가 제한적이다.
더 많은 추론 벤치마크와 멀티모달 작업에서 검증이 필요하다.
둘째, 이 논문은 주로 토론 기반 멀티 에이전트 설정을 사용한다.
도구 사용, 메모리 관리, 계획 수립형 에이전트까지 확장하려면 추가 연구가 필요하다.
셋째, 학생 모델은 교사 모델의 바람직하지 않은 행동도 배울 수 있다.
편향된 추론, 그럴듯하지만 틀린 설명, 안전하지 않은 응답이 함께 증류될 위험이 있다.
따라서 과정 보상 모델과 증류 모델 모두에 대한 검증이 필요하다.
정리
AgentArk는 멀티 에이전트 시스템의 장점을 단일 모델 안으로 옮기려는 시도다.
핵심은 답의 모방이 아니다.
토론 과정에서 생기는 검토, 비판, 수정, 합의의 패턴을 학습시키는 것이다.
실험 결과는 다음을 보여준다.
- 단일 모델도 멀티 에이전트식 추론 능력을 일부 획득할 수 있다.
- PAD가 가장 안정적인 증류 전략이다.
- 학생 모델 용량이 작으면 교사 신호가 너무 많아도 이득이 제한된다.
- 데이터 양보다 고품질 과정 신호가 중요하다.
- 수학 추론에서 배운 능력이 질의응답과 요약 작업으로 일부 전이된다.
- 멀티모달 모델에도 확장 가능성이 있다.
AgentArk의 의미는 분명하다.
강한 추론을 위해 매번 여러 에이전트를 실행할 필요는 없을 수 있다.
좋은 멀티 에이전트 추론 과정을 학습시킨 단일 모델이 더 현실적인 배포 대안이 될 수 있다.
Source
- Paper: AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent
- Authors: Yinyi Luo, Yiqiao Jin, Weichen Yu, Mengqi Zhang, Srijan Kumar, Xiaoxiao Li, Weijie Xu, Xin Chen, Jindong Wang
- arXiv: 2602.03955v1
- Date: 2026-02-03
- PDF: https://arxiv.org/pdf/2602.03955v1
- Code: https://github.com/AIFrontierLab/AgentArk
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| MemoRAG 논문 정리 (0) | 2026.04.28 |
|---|---|
| Learning and Planning Multi-Agent Tasks via an MoE-based World Model 논문 정리 (0) | 2026.04.28 |
| AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights 논문 정리 (0) | 2026.04.27 |
| BIOMINER 논문 정리 (0) | 2026.04.26 |
| RAG-Anything: All-in-One RAG Framework 논문 정리 (1) | 2026.04.22 |



