한 줄 요약
CASTER는 멀티 에이전트 시스템에서 모든 작업을 비싼 고성능 모델에 맡기는 방식을 줄이기 위한 라우터다.
핵심은 단순하다.
- 쉬운 하위 작업은 저렴한 모델로 보낸다.
- 복잡하거나 위험한 하위 작업은 강한 모델로 보낸다.
- 실패한 라우팅 사례를 다시 학습해 다음 선택을 고친다.
논문은 이 방식으로 강한 모델만 쓰는 기준선과 비슷한 품질을 유지하면서,
일부 조건에서 추론 비용을 최대 72.4% 줄였다고 보고한다.

문제의식: 멀티 에이전트는 똑똑하지만 비싸다
멀티 에이전트 시스템은 하나의 큰 목표를 여러 역할로 나눈다.
예를 들면 소프트웨어 개발에서는 다음과 같은 흐름이 생긴다.
- 기획자가 요구사항을 정리한다.
- 아키텍트가 구조를 설계한다.
- 코더가 구현한다.
- 리뷰어가 검토한다.
이 구조는 긴 작업에 강하다.
하지만 비용 문제가 크다.
모든 단계에 GPT-4o 같은 강한 모델을 쓰면 안정적이지만 비싸다.
반대로 저렴한 모델만 쓰면 초반의 작은 오류가 뒤 단계로 퍼진다.
논문은 이 상황을 비용-성능 역설로 본다.
CASTER의 핵심 아이디어
CASTER는 에이전트가 실행되기 직전에 개입한다.
현재 작업, 에이전트 역할, 누적된 문맥을 보고 이 하위 작업에 어떤 모델이 필요한지 판단한다.
그 결과에 따라 약한 모델 또는 강한 모델을 선택한다.

주목할 부분: 가운데 Router가 의미 정보와 구조 정보를 함께 받아 오른쪽의 Weak Model 또는 Strong Model로 작업을 나누는 흐름이 핵심이다.
이 접근은 단순한 비용 절감기가 아니다.
작업의 성격을 보고 모델을 고르는 단계별 오케스트레이션 장치에 가깝다.
그래서 CASTER는 전체 워크플로를 바꾸지 않고도 LangGraph 같은 그래프 기반 멀티 에이전트 구조에 붙일 수 있다.
라우터는 무엇을 보고 판단하나
CASTER는 두 종류의 신호를 함께 본다.
1. 의미 신호
작업 문장의 의미를 본다.
예를 들어 “Hello World를 출력해줘”는 짧고 단순하다.
반면 “비동기 크롤러의 교착 상태를 디버깅해줘”는 더 많은 추론과 코드 이해가 필요하다.
문장 길이만으로는 이 차이를 알기 어렵다. 짧지만 어려운 요청도 있고, 길지만 단순한 요약 요청도 있기 때문이다.
2. 구조 신호
작업이 놓인 상황을 본다.
논문에서 사용하는 구조 신호는 다음에 가깝다.
- 현재 에이전트 역할
- 누적 문맥 길이
- 위험 키워드 존재 여부
- 작업 도메인과 단계
즉, CASTER는 “무슨 말을 하는가”와 “어떤 상황에서 말하는가”를 함께 본다.
수식 없이 설명하는 라우터 구조
논문의 라우터는 두 갈래로 입력을 처리한다.
한 갈래는 텍스트 의미를 압축한다. 다른 갈래는 역할, 문맥 길이, 위험 신호 같은 메타 정보를 압축한다.
이후 두 정보를 합쳐 “이 작업에 강한 모델이 필요한가”를 확률처럼 판단한다.
쉽게 말하면 다음과 같다.
- 텍스트 갈래: 요청 자체의 난이도를 읽는다.
- 메타 갈래: 요청이 놓인 업무 맥락을 읽는다.
- 결합 단계: 둘을 합쳐 모델 선택 점수를 만든다.
이 점수가 기준보다 높으면 강한 모델을 쓴다. 낮으면 약한 모델을 쓴다.
난이도 판단은 실제로 분리되는가
논문은 네 개 도메인에서 라우터 점수를 확인한다.
소프트웨어, 데이터 분석, 과학 탐구, 사이버보안 모두에서 단순 작업은 낮은 점수를 받고,
복잡하거나 위험한 작업은 높은 점수를 받는다.

주목할 부분: 점선 기준 위로 올라간 막대들은 복잡한 작업이며, CASTER가 강한 모델을 써야 할 상황을 비교적 명확하게 구분한다.
이 결과의 의미는 중요하다.
CASTER는 “문장이 길면 어렵다” 같은 규칙만 쓰지 않는다. 논문은 라우터가 논리 의존성, 운영 위험, 전문성 요구 같은 잠재 난이도를 포착한다고 해석한다.
왜 그래프 기반 멀티 에이전트에 더 중요하나
멀티 에이전트 시스템은 선형 질의응답이 아니다.
한 단계의 결과가 다음 단계의 입력이 된다. 리뷰어가 거절하면 다시 실행한다.
일정 횟수 이상 실패하면 강제 종료하거나 실패 경험으로 기록한다.

주목할 부분: 각 도메인의 하늘색 반복 구간은 실행-검토-재시도 루프를 나타내며, 이 구간에서 잘못된 모델 선택이 비용과 품질 모두에 영향을 준다.
이 구조에서는 라우팅 실패가 더 비싸다.
약한 모델이 초기에 틀린 코드를 만들면 리뷰어가 이를 다시 돌려보낸다. 재시도 비용이 생긴다. 더 나쁘게는 틀린 중간 결과가 공유 문맥에 남아 뒤 에이전트를 혼란스럽게 할 수 있다.
그래서 논문은 “일단 싼 모델로 해보고 실패하면 강한 모델로 간다”는 방식이 멀티 에이전트에는 적합하지 않다고 본다.
학습 전략: Cold Start에서 실패 피드백까지
CASTER의 학습은 크게 세 단계다.
첫째, 작은 시드 데이터로 시작한다. 쉬운 작업, 중간 작업, 어려운 작업을 나누고 문장 표현을 다양하게 바꿔 초기 학습 데이터를 만든다.
둘째, GPT-4o를 활용해 동적 작업을 생성한다. 소프트웨어, 데이터 분석, 과학, 보안 도메인에서 쉬운 문제와 어려운 문제를 만든다.
셋째, 실제 라우팅 결과를 보고 다시 학습한다.
여기서 가장 중요한 부분은 Negative Feedback이다.
약한 모델을 골랐는데 실패했다면, 그 사례는 “다음에는 강한 모델을 써야 하는 작업”으로 다시 표시된다. 반대로 약한 모델로 성공했다면 저렴한 경로를 유지하도록 학습한다.

주목할 부분: 하단의 Re-labeling Logic은 실패한 약한 모델 선택을 강한 모델 선택 사례로 고쳐, 라우터가 같은 실수를 줄이게 만든다.
논문은 무작위 탐색을 피한다.
무작위로 강한 모델을 너무 자주 쓰면 쉬운 작업도 “강한 모델이 필요하다”는 잘못된 신호가 생길 수 있다. CASTER는 현재 라우터가 만든 실제 경계 사례를 중심으로 개선한다.
실험 설정
논문은 네 개 도메인에서 CASTER를 평가한다.
- Software Engineering
- Data Analysis
- Scientific Discovery
- Cybersecurity
비교 대상은 세 가지다.
- Force Strong: 모든 작업에 강한 모델 사용
- Force Weak: 모든 작업에 약한 모델 사용
- CASTER: 작업별로 모델을 동적 선택
추가로 FrugalGPT식 캐스케이드 전략과도 비교한다. 이 전략은 먼저 약한 모델을 쓰고, 부족하면 강한 모델로 넘어가는 방식이다.
평가는 LLM-as-a-Judge 방식으로 수행한다. 소프트웨어는 기능 정확성, 보안성, 코드 품질을 본다. 데이터 분석은 코드, CSV, 시각화 결과를 함께 본다. 과학 도메인은 수치 정확성과 과학적 타당성을 본다. 보안 도메인은 기능뿐 아니라 안전성과 윤리적 준수도 본다.
비용 결과: 강한 모델만 쓰는 것보다 완만한 비용 곡선
CASTER의 가장 직접적인 효과는 비용 곡선에서 보인다.
강한 모델만 쓰면 작업이 누적될수록 비용이 가파르게 증가한다. 약한 모델만 쓰면 싸지만 품질이 불안정하다. CASTER는 중간에 위치하면서도 필요한 순간에는 강한 모델을 쓴다.
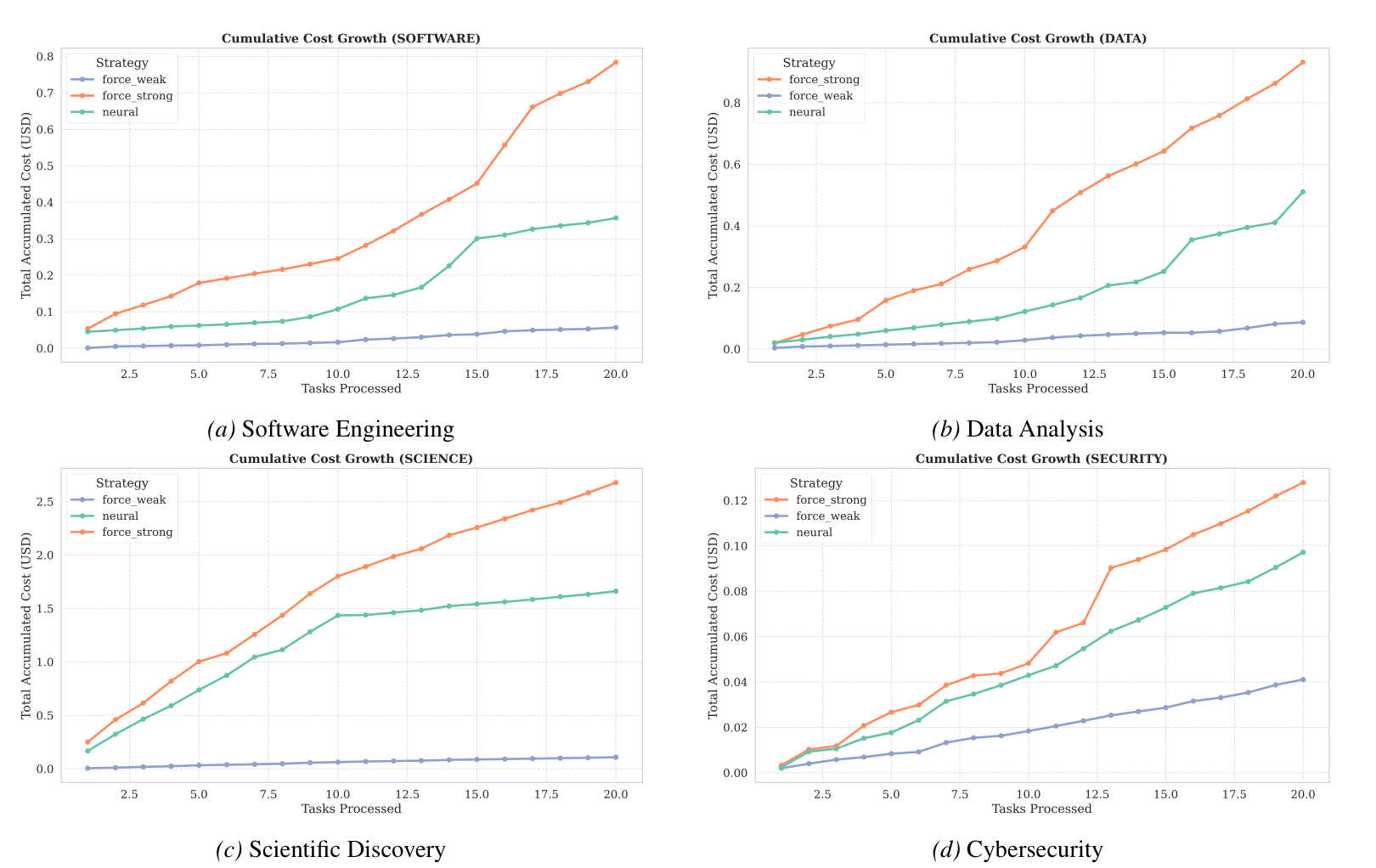
주목할 부분: 초록색 CASTER 선은 주황색 Force Strong보다 낮게 유지되면서도, 파란색 Force Weak처럼 무조건 저비용으로만 고정되지 않는다.
논문이 보고한 평균 작업당 비용 절감은 다음과 같다.
- 소프트웨어: 54.3% 절감
- 데이터 분석: 45.3% 절감
- 과학 탐구: 37.9% 절감
- 사이버보안: 23.4% 절감
OpenAI 계열의 소프트웨어 실험에서는 비용 절감 폭이 최대 72.4%까지 보고된다.
품질 결과: 비용을 줄이면서도 성능을 크게 잃지 않는다
비용 절감만으로는 충분하지 않다.
멀티 에이전트 시스템에서는 품질 저하가 누적될 수 있기 때문이다.
논문은 전체 점수에서 CASTER가 강한 모델 기준선에 가깝거나 일부 도메인에서는 더 높은 점수를 얻었다고 보고한다.
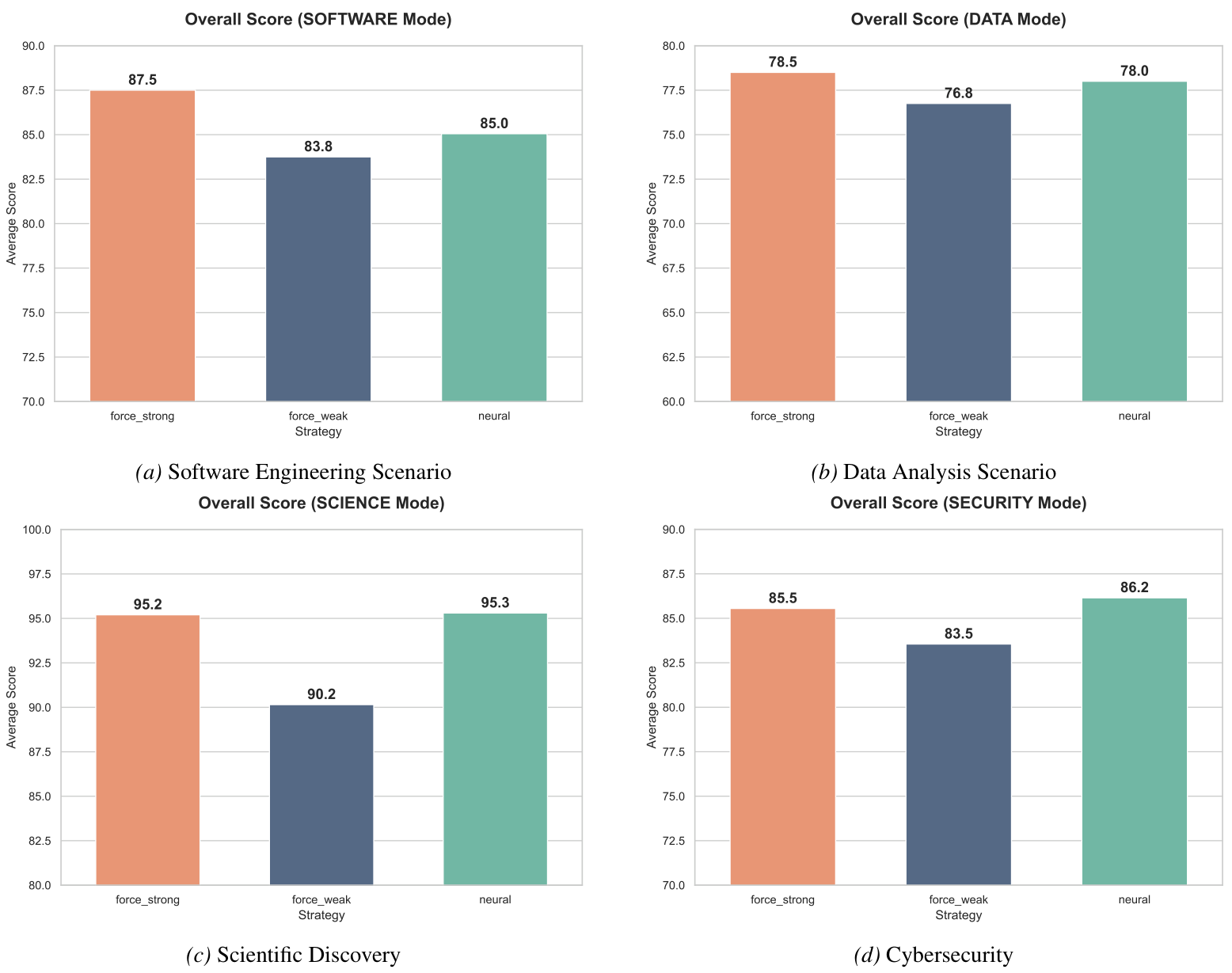
주목할 부분: Science와 Security에서는 CASTER 막대가 Force Strong과 같거나 약간 높아, 동적 라우팅이 단순 비용 절감 이상의 효과를 냈음을 보여준다.
전체 점수는 다음과 같다.
- 소프트웨어: CASTER 85.0, Force Strong 87.5
- 데이터 분석: CASTER 78.0, Force Strong 78.5
- 과학 탐구: CASTER 95.3, Force Strong 95.2
- 사이버보안: CASTER 86.2, Force Strong 85.5
논문은 이를 강한 모델의 과도한 추론 또는 단순 작업에서의 과적합적 응답을 줄인 효과로 해석한다.
FrugalGPT와의 차이: 실패 후 재시도보다 사전 판단
FrugalGPT식 캐스케이드는 비용 절감 아이디어가 명확하다.
먼저 싼 모델을 시도한다. 결과가 부족하면 강한 모델로 넘어간다.
하지만 멀티 에이전트에서는 이 방식이 문제를 만든다.
어려운 작업에서 약한 모델이 실패하면 이미 한 번 비용을 냈고, 다시 강한 모델 비용을 내야 한다.
논문은 이를 Double-Billing Penalty로 설명한다.
CASTER는 작업 전에 난이도를 예측한다. 그래서 어려운 작업은 처음부터 강한 모델로 보낸다.
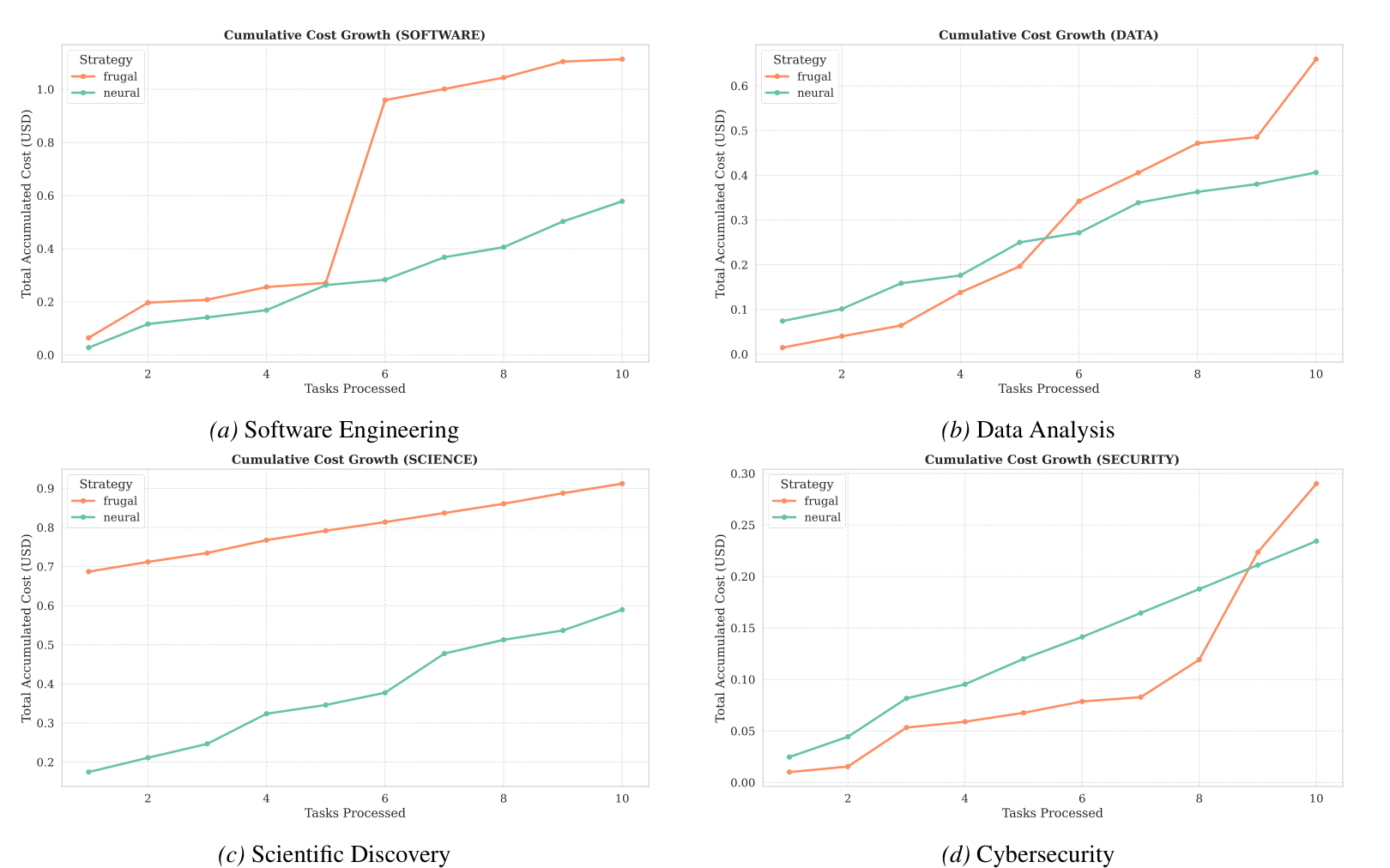
주목할 부분: 복잡한 작업 시퀀스에서 FrugalGPT의 비용선은 실패 후 재시도 때문에 급격히 상승하지만, CASTER는 사전 라우팅으로 더 완만하게 증가한다.
FrugalGPT 대비 CASTER의 비용 절감은 다음과 같이 보고된다.
- 소프트웨어: 48.0% 절감
- 데이터 분석: 38.4% 절감
- 과학 탐구: 35.3% 절감
- 사이버보안: 20.7% 절감
품질도 CASTER가 모든 도메인에서 더 높다. 상승 폭은 작지만 일관적이다.
여러 모델 제공자에서도 작동하는가
논문은 OpenAI만 보지 않는다.
Claude, Gemini, DeepSeek, Qwen 계열에서도 일반화 실험을 수행한다. 가격 구조가 다른 모델군에서도 CASTER는 대체로 강한 모델 기준선에 가까운 품질을 유지하면서 비용을 낮춘다.
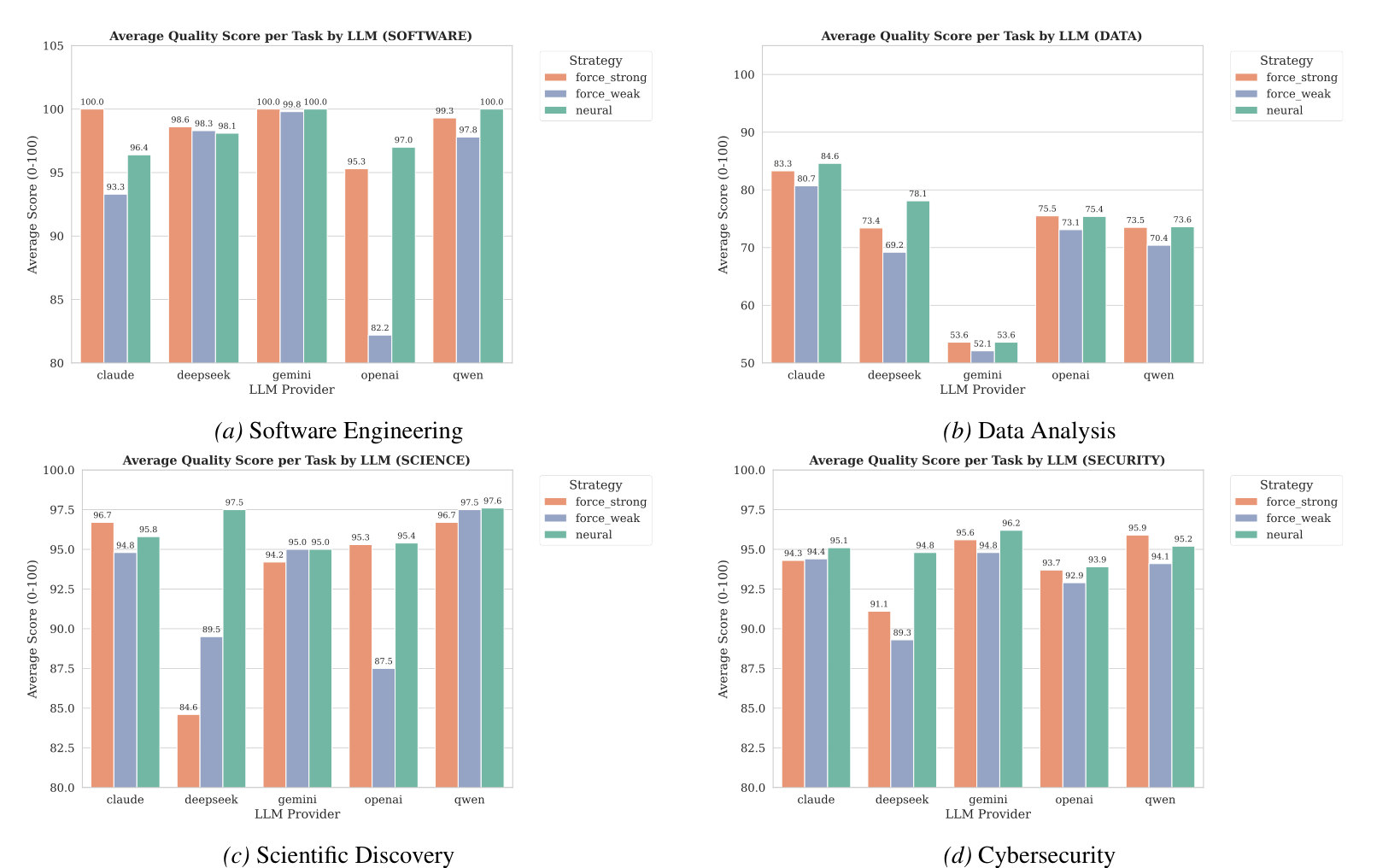
주목할 부분: 여러 제공자에서 초록색 CASTER 막대가 주황색 Force Strong에 가깝게 유지되며, 약한 모델 기준선의 큰 품질 하락을 보완한다.
흥미로운 예외도 있다.
DeepSeek처럼 강한 모델과 약한 모델의 가격 차이가 작거나 토큰 사용량 구조가 다르면 비용 절감 효과가 작아지거나 반대로 보일 수 있다. 즉, CASTER의 경제적 효과는 모델 가격 차이가 클수록 더 커진다.
이 논문의 기여
CASTER의 기여는 세 가지로 정리할 수 있다.
1. 멀티 에이전트용 라우팅 문제를 정면으로 다룬다
기존 라우팅은 단일 질의나 일반 챗봇 선호도에 가까웠다. CASTER는 에이전트 역할, 누적 문맥, 반복 루프를 고려한다.
2. 사전 예측 방식으로 캐스케이드 비용을 줄인다
실패 후 강한 모델로 넘어가는 방식은 단순해 보이지만, 멀티 단계 작업에서는 중간 오류와 재시도 비용을 만든다. CASTER는 실행 전에 난이도를 판단한다.
3. 실패 사례를 학습 신호로 쓴다
약한 모델 선택이 실패하면 그 사례를 강한 모델 필요 사례로 다시 학습한다. 이 방식은 라우터가 비용 절감에만 치우치지 않도록 만든다.
한계와 읽을 때의 주의점
이 논문은 실용적인 방향을 제시하지만, 몇 가지 점은 조심해서 봐야 한다.
첫째, 평가는 LLM-as-a-Judge에 크게 의존한다. 논문은 자기선호 편향을 줄이기 위해 여러 모델 제공자를 포함하지만, 자동 평가 자체의 한계는 남는다.
둘째, 작업 생성에 합성 데이터와 동적 생성 파이프라인을 사용한다. 실제 기업 환경의 장기 운영 로그와는 분포가 다를 수 있다.
셋째, 라우팅 선택은 기본적으로 약한 모델과 강한 모델의 이분법에 가깝다. 실제 운영에서는 중간 성능 모델, 도메인 특화 모델, 도구 호출 비용까지 함께 고려해야 한다.
넷째, 보안 도메인의 경우 모델 선택 최적화가 안전한 실행 환경을 대체하지는 않는다. 샌드박스, 권한 제한, 감사 로그는 별도로 필요하다.
실무적으로 중요한 시사점
CASTER가 말하는 방향은 명확하다.
앞으로의 멀티 에이전트 시스템은 “어떤 모델이 가장 똑똑한가”보다 “어떤 단계에 어떤 모델을 쓸 것인가”가 더 중요해진다.
특히 다음 환경에서 가치가 크다.
- 작업 단계가 많다.
- 리뷰와 재시도 루프가 있다.
- 모델 비용 차이가 크다.
- 쉬운 작업과 어려운 작업이 섞여 있다.
- 한 번의 오류가 뒤 단계에 영향을 준다.
CASTER는 강한 모델을 덜 쓰자는 주장이 아니다.
강한 모델을 정말 필요한 순간에 쓰자는 주장에 가깝다.
결론
CASTER는 멀티 에이전트 시스템의 비용 문제를 모델 선택 문제로 재정의한다.
고정적으로 강한 모델을 쓰는 방식은 비싸다. 고정적으로 약한 모델을 쓰는 방식은 불안정하다.
실패 후 재시도하는 캐스케이드는 중간 오류와 이중 비용을 만든다.
CASTER는 작업 전 난이도 판단, 문맥 기반 라우팅, 실패 피드백 학습을 결합해 이 균형을 맞춘다.
논문의 핵심 메시지는 간단하다.
멀티 에이전트의 효율성은 에이전트 수를 줄이는 것만으로 해결되지 않는다.
각 단계에 맞는 모델을 고르는 지능형 라우터가 필요하다.
Source
- Paper: CASTER: Breaking the Cost-Performance Barrier in Multi-Agent Orchestration via Context-Aware Strategy for Task Efficient Routing
- Authors: Shanyv Liu, Xuyang Yuan, Tao Chen, Zijun Zhan, Zhu Han, Danyang Zheng, Weishan Zhang, Shaohua Cao
- arXiv: 2601.19793v1 [cs.AI]
- Preprint: January 28, 2026
- Link: https://arxiv.org/abs/2601.19793
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| Chain-of-Agents 논문 정리 (0) | 2026.04.28 |
|---|---|
| O-Researcher 논문 정리 (0) | 2026.04.28 |
| Beyond Pipelines: A Survey of the Paradigm Shift toward Model-native Agentic AI 논문 정리 (0) | 2026.04.28 |
| MemOS 논문 정리 (0) | 2026.04.28 |
| MemoRAG 논문 정리 (0) | 2026.04.28 |



