분석 시점: 2026-05-27 KST. 대상 저장소는
Doorman11991/smallcode의 공개 GitHub 문서와 주요 소스 파일 구조다. 저장소의 README,ARCHITECTURE.md,COMPARISON.md,package.json,bench/,knowledge/,bin/,src/구조를 중심으로 분석했다.
Wiki는 별도 문서로 구성되어 있지 않았고, Discussions는 접근 가능한 공개 토론 페이지가 확인되지 않았다.
SmallCode는 8B–35B급 소형 로컬 LLM을 대상으로 설계된 코딩 에이전트다.
핵심은 “더 큰 모델을 쓰는 것”이 아니라, 작은 모델이 흔히 실패하는 지점인 좁은 컨텍스트, 불안정한 도구 호출, 긴 작업 기억 상실, 멀티파일 편집 오류를 에이전트 아키텍처로 보완하는 데 있다.
이 저장소에서 별도 아키텍처 다이어그램, 실행 GIF, UI 스크린샷 같은 정식 이미지 자산은 확인되지 않았다. 따라서 본 리포트의 이미지는 저장소의 README/문서/소스 구조를 기반으로 직접 재구성한 분석용 도식이다.

Quick Links
| 구분 | 링크 | 비고 |
|---|---|---|
| 공식 저장소 | GitHub Repository | 프로젝트 루트 및 README |
| README | README.md | 설치, 기능, 도구, API, 관찰성 설명 |
| 아키텍처 문서 | ARCHITECTURE.md | 라우팅, 계획, 편집, 메모리, escalation 설계 |
| 비교 문서 | COMPARISON.md | 다른 코드 에이전트와의 기능 비교 및 자체 벤치마크 주장 |
| 벤치마크 | bench/README.md | smoke, polyglot-mini, tool-use suite 설명 |
| 지식 주입 | knowledge/README.md | 프로젝트 지식 노트 작성 및 주입 방식 |
| 데모 | 확인되지 않음 | 저장소 문서에서 별도 라이브 데모 링크는 확인되지 않음 |
| 논문 | 확인되지 않음 | 저장소 문서에서 별도 논문 링크는 확인되지 않음 |
Key Features
1. 소형 로컬 LLM 최적화: 8B–35B 모델을 실전 개발에 맞춘다
SmallCode는 README에서 권장 모델 크기를 8B–35B로 제시한다.
4B 이하 모델은 안정적인 코딩 작업에 부족할 수 있고, 35B 이상 모델은 일반적인 frontier-oriented 도구에서도 잘 동작한다는 전제를 둔다.
즉 이 프로젝트의 차별점은 “작은 모델을 위한 보정 장치”다.
핵심 설계는 다음과 같다.
- 로컬 LLM 서버: Ollama, LM Studio, OpenAI-compatible endpoint
- 터미널 네이티브 실행:
smallcodeCLI/TUI - 작은 컨텍스트 대응: context budget, tool schema pruning, compression
- 작은 모델의 불안정한 JSON 대응: forgiving parser, repair prompt, multi-format parsing
- 로컬 우선 설계: 클라우드 escalation은 API key가 있을 때만 선택적으로 사용
2. 2단계 도구 라우팅: 모든 도구를 모델에 한 번에 보여주지 않는다
작은 모델은 도구 스키마가 많아질수록 호출 형식을 틀리거나, 문제와 무관한 도구를 선택할 가능성이 커진다.
SmallCode는 이를 피하기 위해 도구 카테고리를 먼저 분류하고, 이후 해당 카테고리에 맞는 도구만 모델에 노출한다.

그림 1. SmallCode의 도구 라우팅은 사용자 요청을 read, write, run, search, plan, web, code-intel, respond 같은 카테고리로 분류한 뒤 필요한 도구 스키마만 노출한다. 단순 응답이면 도구를 아예 주입하지 않아 토큰을 절약한다.
bin/tools.js의 도구 목록은 read_file, write_file, patch, bash, search, find_files, memory_*, bone_compile, web_search, web_fetch 등으로 구성된다.
여기에 compound tools, plugin tools, MCP tools가 결합된다.
중요한 점은 도구가 “많다”보다, 언제 어떤 도구만 보여줄지를 별도 라우터가 제어한다는 점이다.
3. Patch-first 편집: 전체 파일 재작성보다 작은 변경을 우선한다
SmallCode는 파일 편집에서 write_file보다 patch를 우선하도록 설계되어 있다.
작은 모델은 큰 파일을 통째로 재생성할 때 누락, 포맷 붕괴, 중복 삽입을 만들기 쉽다.
patch 방식은 old_str와 new_str를 통해 변경 범위를 좁혀 오류 표면을 줄인다.

그림 2. SmallCode의 편집 루프는 파일을 먼저 읽고, 작은 patch를 적용한 뒤 검증한다. 문자열 매칭이 실패하면 semantic merge를 시도하고, 반복 실패 시 rollback, retry, decompose, escalation으로 이어진다.
이 방식은 다음 안전장치와 연결된다.
- read-before-write guard: 쓰기 전에 파일을 읽도록 유도
- path safety: 작업 디렉터리 밖 접근 방지
- snapshot/rollback: 위험한 편집 전 상태 저장
- validation: Python, JS, TS, Go, JSON, BoneScript 등의 구문/빌드 검증
- semantic merge fallback:
old_str가 정확히 맞지 않아도 의미적으로 변경점을 병합
4. 컨텍스트 예산 엔진: 작은 창을 “아껴 쓰는” 구조
작은 LLM은 8k–16k급 컨텍스트에서 긴 파일, 많은 도구, 장기 대화를 동시에 처리하기 어렵다.
SmallCode는 context budget을 둬서 tool result, working memory, knowledge notes, tool schema를 제한한다.
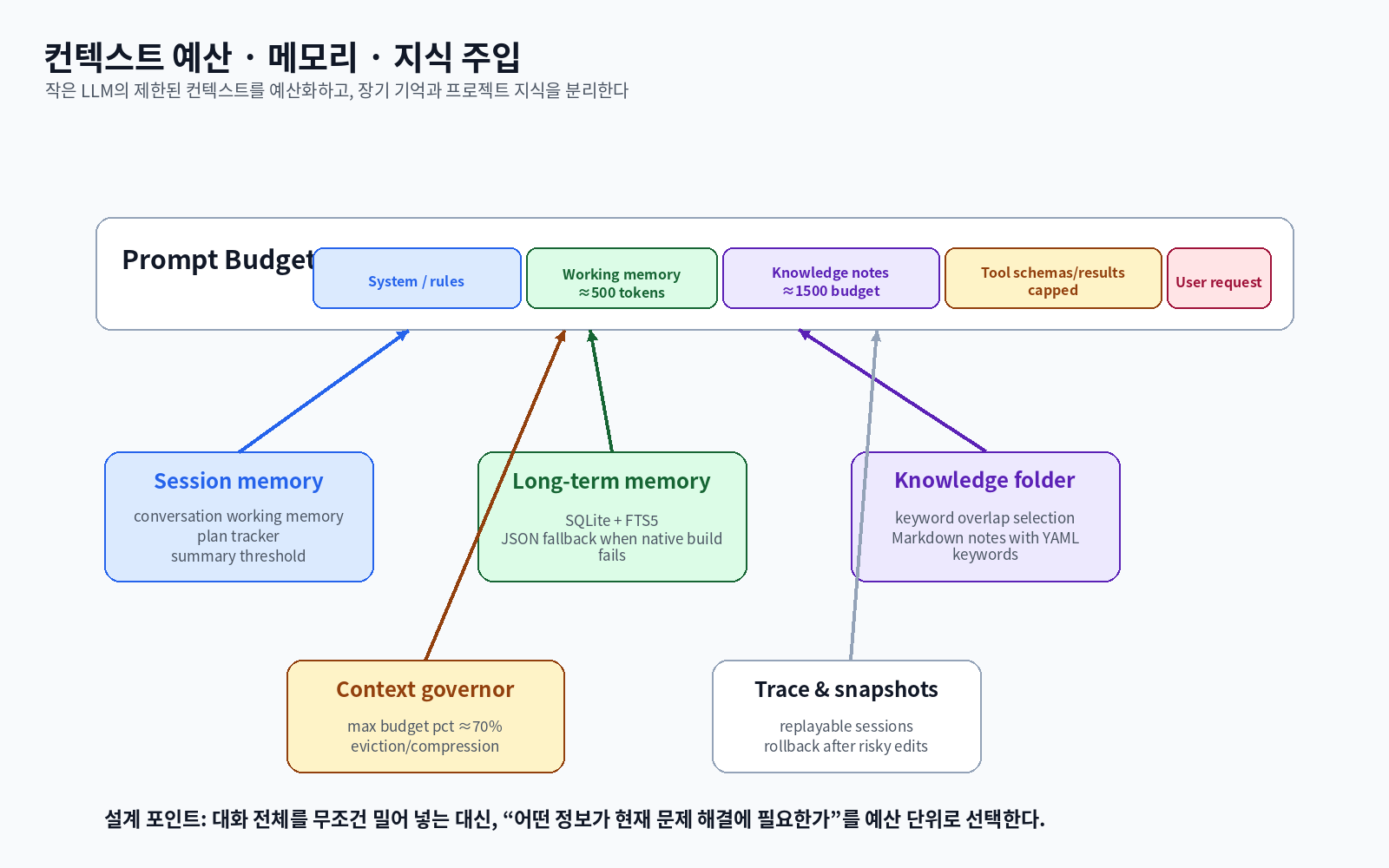
그림 3. SmallCode는 대화, 작업 메모리, 지식 노트, 도구 결과, 도구 스키마를 예산 단위로 다룬다. 저장소의 smallcode.toml은 context budget, working memory, summary threshold 같은 값을 설정할 수 있게 한다.
특히 knowledge/ 디렉터리는 Markdown 기반 프로젝트 지식 저장소 역할을 한다.
문서에 YAML front matter로 keywords를 달면, 현재 요청과의 키워드 겹침을 기준으로 관련 노트가 프롬프트에 주입된다.
이는 RAG 전체 시스템이라기보다, 개발 프로젝트 안에서 반복적으로 필요한 규칙과 컨텍스트를 작은 모델에 제공하는 경량 지식 주입 방식에 가깝다.
5. TODO 기반 계획 추적: 긴 작업을 작은 실행 단위로 유지한다
작은 모델은 멀티스텝 작업에서 중간 목표를 잊기 쉽다.
SmallCode는 numbered plan, TODO, active plan injection을 사용해 현재 단계가 무엇인지 모델에게 계속 상기시킨다.
ARCHITECTURE.md는 plan tracker가 응답에서 번호가 붙은 계획을 캡처하고, 이후 루프에 active plan으로 주입한다고 설명한다.
이 설계는 단순해 보이지만 에이전트 안정성에는 중요하다.
코딩 에이전트의 실패는 대부분 “처음엔 맞게 시작했지만, 3~5번째 도구 호출 뒤 목적을 잃는” 형태로 발생한다.
SmallCode는 이를 별도 메모리/계획 레이어로 완화한다.
6. Governor: 검증, 재시도, 작업 분해, escalation을 담당하는 안전 레이어
bin/governor.js는 SmallCode의 복구 전략을 담당한다.
코드 검증, 도구 신뢰도 점수, hard-fail enforcement, retry/decompose 전략이 여기에 들어간다.
대표적인 흐름은 다음과 같다.
- 모델이 파일을 수정하거나 명령을 실행한다.
- Governor가 언어별 검증을 수행한다.
- 실패가 반복되면 동일한 작업을 무한 재시도하지 않고 작업을 더 작은 문제로 분해한다.
- 설정된 API key가 있고 조건을 만족하면 더 강한 모델로 escalation한다.
이는 작은 모델 기반 에이전트에서 매우 중요한 장치다.
“모델이 알아서 고치겠지”가 아니라, 실패를 구조적으로 감지하고 다음 행동을 제한한다.
7. 선택적 클라우드 escalation: 로컬 우선, 필요 시 강한 모델 호출
SmallCode는 기본적으로 로컬 모델을 전제로 하지만, API key가 설정된 경우 Anthropic, OpenAI, DeepSeek 계열 모델로 escalation할 수 있다.
README와 bin/escalation.js는 이 기능이 opt-in임을 명시한다.
블로그 관점에서 이 설계는 현실적이다.
모든 작업을 로컬 8B–20B 모델로 해결하려 하면 복잡한 리팩터링이나 장기 추론에서 실패율이 높아진다.
반대로 모든 작업을 frontier 모델로 보내면 비용과 프라이버시 문제가 생긴다.
SmallCode는 “대부분은 로컬, 실패한 일부만 escalation”이라는 하이브리드 운영 방식을 채택한다.
8. MCP, code graph, plugin, skill 지원
SmallCode는 MCP 서버 모드와 plugin/skill 구조를 제공한다.
README의 도구 목록에는 code graph, retrieval, memory, web browsing, BoneScript 도구가 포함되어 있고, .smallcode/plugins/hello-plugin 예시 디렉터리도 있다.
이 구조는 단일 CLI 도구를 넘어, 프로젝트별 개발 환경에 맞춰 확장할 수 있는 에이전트 플랫폼에 가깝다.
특히 MCP code graph는 단순 grep보다 높은 수준의 코드 이해 작업에 유리할 수 있다.
9. BoneScript 통합: 작은 모델에게 구조화된 백엔드 생성을 맡긴다
README는 BoneScript와 bundled skills를 포함한다고 설명한다.
BoneScript는 Node.js/TypeScript 백엔드 생성에 특화된 DSL 성격의 레이어로 보이며, bone_compile, bone_check 같은 도구가 포함되어 있다.
작은 모델에게 일반 코드를 직접 길게 쓰게 하는 대신, 더 구조화된 중간 언어를 사용해 결과를 안정화하려는 접근이다.
이는 bioinformatics workflow DSL, clinical rule DSL 같은 영역에도 적용 가능한 설계 아이디어다.
10. 벤치마크 하네스와 관찰성: 에이전트 루프를 측정 가능하게 만든다
SmallCode는 bench/ 디렉터리에 smoke, polyglot-mini, tool-use suite를 제공한다.
실행 결과는 .smallcode/benchmarks/<run-id>.json에 저장되고, bench:diff로 baseline과 feature branch를 비교할 수 있다.

그림 4. SmallCode 벤치마크 하네스는 단일 모델 점수가 아니라, 에이전트 루프가 다양한 작업에서 얼마나 안정적으로 도구를 호출하고 결과를 검증하는지 확인하는 데 초점이 있다.
COMPARISON.md에는 Gemma 4 E4B 계열 모델에서의 자체 비교 결과가 제시되어 있다.
다만 이 수치는 저장소 작성자가 제시한 내부/문서상 주장으로 보는 것이 안전하며, 독립 재현 결과로 간주해서는 안 된다.
Tech Stack
Runtime & Language
| 항목 | 내용 |
|---|---|
| 런타임 | Node.js >=18.0.0 |
| 패키지 버전 | smallcode@1.2.3 |
| 주요 언어 비율 | JavaScript 67.5%, MAXScript 21.8%, TypeScript 10.2%, Other 0.5% |
| CLI entry | bin/smallcode.js |
| API entry | src/api/index.js |
| package bin | smallcode, smallcode-init |
Main Dependencies
| 패키지 | 버전 | 역할 |
|---|---|---|
bonescript-compiler |
0.14.0 |
BoneScript compile/check |
chalk |
4.1.2 |
터미널 출력 스타일링 |
cli-highlight |
2.1.11 |
코드/CLI 하이라이팅 |
express |
^5.2.1 |
API/server 계층 |
marked |
15.0.12 |
Markdown parsing |
marked-terminal |
7.3.0 |
Markdown terminal rendering |
budget-aware-mcp |
0.6.1 optional |
MCP/context-aware tool bridge |
Optional / Peer Dependencies
| 패키지 | 버전 | 역할 |
|---|---|---|
playwright-extra |
^4.3.0 |
선택적 web browsing |
puppeteer-extra-plugin-stealth |
^2.11.0 |
선택적 stealth browsing 플러그인 |
Development Dependencies
| 패키지 | 버전 |
|---|---|
@types/node |
^25.9.0 |
jest |
^30.4.2 |
ts-node |
^10.9.2 |
typescript |
^6.0.3 |
Architecture
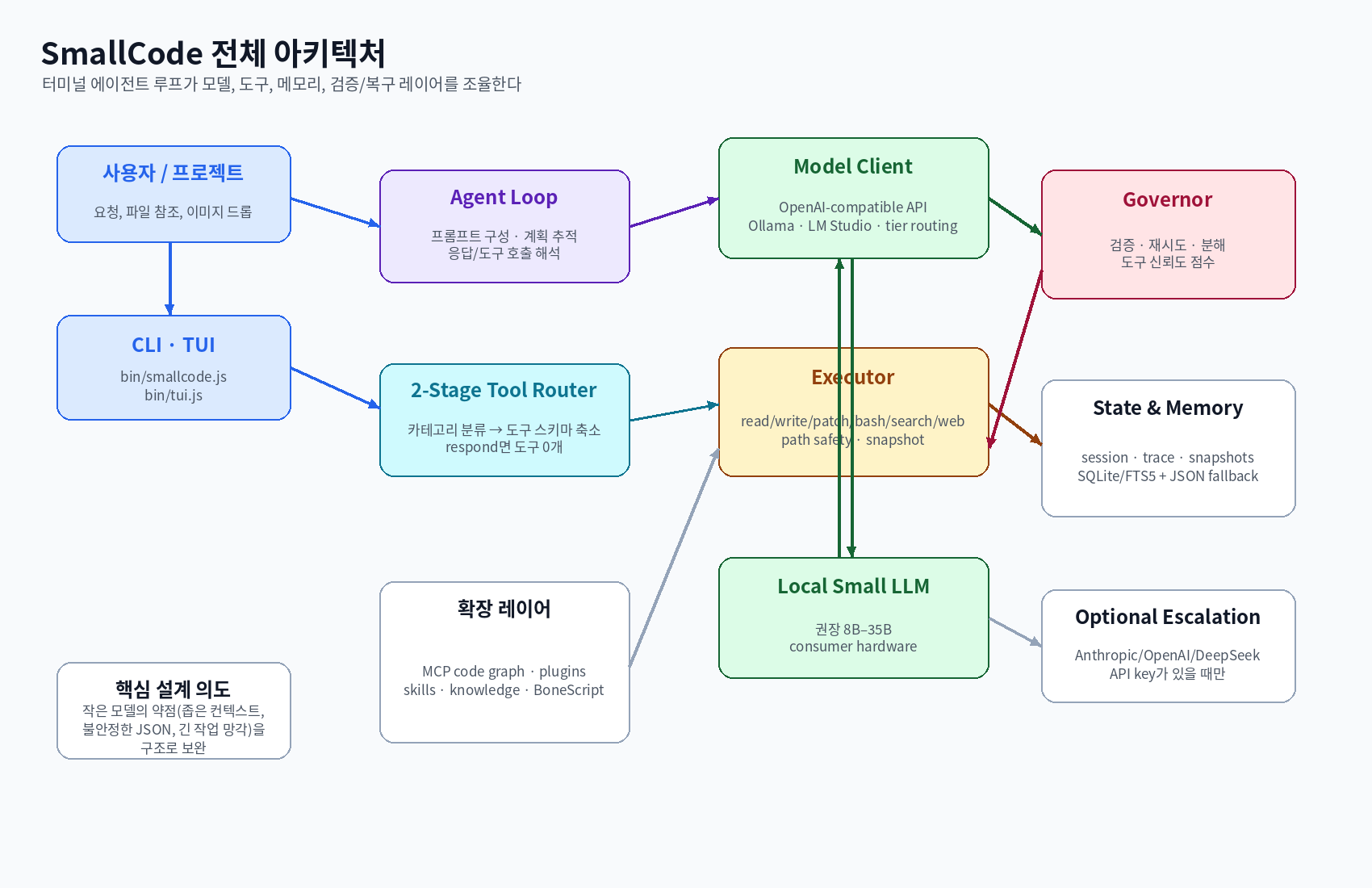
그림 5. SmallCode의 전체 구조. 터미널 사용자 입력은 CLI/TUI를 거쳐 agent loop로 들어가고, 모델 클라이언트·도구 라우터·executor·governor·메모리 계층이 협력해 작은 모델의 약점을 보완한다.
SmallCode의 구조는 크게 여섯 레이어로 나눌 수 있다.
1. Interface Layer: CLI/TUI
bin/smallcode.js가 CLI 진입점이고, TUI 관련 로직은 bin/tui.js, src/tui/에 나뉘어 있다.
사용자는 프로젝트 루트에서 smallcode를 실행하고, 터미널에서 요청을 입력한다.
README는 programmatic API도 제공한다고 설명하므로, CLI만이 아니라 외부 코드에서 SmallCode를 에이전트 런타임처럼 호출하는 흐름도 가능하다.
2. Prompt & Agent Loop Layer
Agent loop는 사용자 요청, 시스템 프롬프트, working memory, 현재 plan, tool routing 결과를 조합한다.
이 계층에서 작은 모델에게 “무엇을 해야 하는지”와 “어떤 도구만 사용할 수 있는지”가 결정된다.
중요한 포인트는 SmallCode가 모델을 단순 채팅 모델로 쓰지 않는다는 점이다.
모델은 agent loop 안에서 제한된 행동 공간을 받는다. 이 제한 자체가 작은 모델의 안정성을 높인다.
3. Model Client Layer
bin/model_client.js는 OpenAI-compatible chat completion 요청을 구성한다.
smallcode.toml과 .env.example은 SMALLCODE_MODEL, SMALLCODE_BASE_URL, SMALLCODE_PROVIDER 같은 설정을 제공한다.
기본 예시는 Ollama의 http://localhost:11434/v1 또는 LM Studio류의 OpenAI-compatible endpoint를 전제로 한다.
또한 tier별 endpoint를 나눠 약한 모델, 일반 모델, 강한 모델을 구분할 수 있다.
4. Tool Routing & Tool Schema Layer
도구 라우팅은 SmallCode의 핵심이다.
ARCHITECTURE.md는 요청 카테고리 분류와 우선순위(write > run > code-intelligence > search > plan > read > web > respond)를 설명한다.
이 구조가 중요한 이유는 다음과 같다.
- 작은 모델은 긴 tool schema를 읽는 것만으로도 컨텍스트를 많이 소모한다.
- 많은 도구가 있으면 잘못된 도구를 호출할 가능성이 커진다.
respond요청에는 도구가 필요 없으므로 tool schema를 넣지 않아도 된다.- 쓰기 요청에서는
write_file보다patch중심으로 행동 공간을 제한할 수 있다.
5. Executor & Validation Layer
bin/executor.js는 실제 파일 읽기, 쓰기, patch, shell 실행, 검색, web fetch, BoneScript compile 등을 수행한다.
이 계층은 모델의 텍스트 출력을 실제 시스템 행동으로 바꾸는 곳이므로, 안전장치가 필요하다.
SmallCode의 executor는 다음 흐름을 따른다.
- 경로 정규화 및 safe path 처리
- 읽기 전 쓰기 방지
- 파일 크기/내용 길이 제한
- patch 적용 전 snapshot 생성
old_str불일치 시 semantic merge fallback- 실행 결과를 다시 모델/검증 루프에 전달
6. Memory, Session, Trace Layer
SmallCode는 working memory와 long-term memory를 구분한다.
README와 아키텍처 문서는 SQLite + FTS5 기반 장기 메모리, JSON fallback, session trace, snapshot/rollback을 언급한다.
이는 단순 “대화 기록 저장”과 다르다.
코딩 에이전트에게 중요한 것은 이전 메시지 전체가 아니라, 현재 작업을 끝내는 데 필요한 사실, 결정, 파일 상태, 실패 기록이다.
SmallCode는 이를 별도 상태 계층으로 분리한다.

그림 6. 저장소의 주요 디렉터리 역할. bin/은 CLI와 실행 로직, src/는 API/TUI/compiled/tool 패키지, bench/는 평가 하네스, knowledge/는 프롬프트 지식 주입, extensions/와 marrow/는 생성/컴파일 기반 기능 확장과 관련된다.
Architecture Takeaway
SmallCode의 아키텍처는 “모델 하나가 모든 것을 잘해야 한다”는 가정에서 벗어난다.
대신 다음과 같은 보조 시스템을 붙인다.
- 도구 선택은 deterministic router가 돕는다.
- 긴 작업은 plan tracker가 유지한다.
- 파일 수정은 patch-first로 제한한다.
- 실패는 governor가 분해/재시도/escalation한다.
- 컨텍스트는 budget engine이 관리한다.
- 프로젝트 지식은
knowledge/와 memory 계층이 제공한다.
이 구조는 작은 모델을 “독립 개발자”처럼 다루지 않고, 제약된 실행 환경 안의 작업자로 다루는 방식이다.
Usage & Setup

그림 7. SmallCode 설치·실행·벤치마크 명령 요약. 로컬 LLM endpoint와 Node.js 18+가 기본 전제이며, 웹 브라우징과 클라우드 escalation은 선택 기능이다.
1. npm으로 설치
npm install -g smallcode
또는 설치 없이 실행할 수 있다.
npx smallcode
프로젝트 루트에서 실행한다.
cd my-project
smallcode2. Prebuilt Binary 설치
Linux/macOS:
bash <(curl -fsSL https://raw.githubusercontent.com/Doorman11991/smallcode/master/install.sh)Windows PowerShell:
iwr -Uri https://raw.githubusercontent.com/Doorman11991/smallcode/master/install.ps1 -UseBasicParsing | iex
README에 따르면 prebuilt binary는 Node 런타임과 native addon을 포함하므로 별도 Node 설치 없이 사용할 수 있다.
3. 로컬 모델 설정
.env 예시:
SMALLCODE_MODEL=your-model-name
SMALLCODE_BASE_URL=http://localhost:1234/v1
SMALLCODE_PROVIDER=openaiOllama 예시:
SMALLCODE_MODEL=gpt-oss:20b \
SMALLCODE_BASE_URL=http://localhost:11434/v1 \
smallcode
smallcode.toml 예시는 기본 provider를 openai, 모델을 gpt-oss:20b, base URL을 http://localhost:11434/v1로 둔다. 이는 OpenAI-compatible API 형식을 사용하는 로컬 서버와 연결하기 위한 구성이다.
4. 벤치마크 실행
npm run bench:smoke
npm run bench:polyglot
npm run bench:tools
결과는 다음 경로에 저장된다.
.smallcode/benchmarks/<run-id>.json
비교 실행:
npm run bench:diff bench/baselines/main bench/baselines/feature5. 선택적 Web Browsing
README는 web browsing 기능을 선택 기능으로 둔다.
활성화하려면 다음과 같은 설정과 peer dependency가 필요하다.
SMALLCODE_WEB_BROWSE=true
npm install -g playwright-extra puppeteer-extra-plugin-stealth
npx playwright install chromium
작은 모델에서는 브라우징이 오히려 불안정할 수 있으므로, README는 20B 이상 모델을 더 적합하게 본다.
Personal Insights
의료 AI 관점: Local-first agent는 PHI-adjacent 개발 환경에 유리하지만, 임상 자동화와는 다르다
의료 AI 개발에서는 환자 정보, 내부 임상 워크플로, 병원별 규칙, 검증되지 않은 모델 출력이 모두 민감하다.
SmallCode의 local-first 설계는 이런 환경에서 장점이 있다.
특히 다음 작업에 적합하다.
- 병원 내부 분석 파이프라인 코드 정리
- FHIR/HL7 변환 스크립트 작성 보조
- 임상 데이터 전처리 코드의 테스트 케이스 생성
- 연구용 모델 학습 코드의 반복 리팩터링
- 내부 문서 기반 개발 규칙을
knowledge/에 넣고 agent에 주입
다만 SmallCode를 임상 의사결정 자동화 에이전트로 바로 사용하는 것은 부적절하다.
이 프로젝트는 코딩 에이전트이지 의료기기 소프트웨어 검증 체계가 아니다.
의료 AI 환경에서 사용하려면 egress 차단, audit log, human-in-the-loop review, test fixture, PHI masking, 승인된 tool allowlist가 필요하다.
Bioinformatics 관점: 파이프라인 유지보수와 재현성 작업에 잘 맞는다
Bioinformatics 프로젝트는 Snakemake, Nextflow, Python/R 스크립트, Bash glue code, reference data config가 뒤섞이는 경우가 많다.
이때 SmallCode의 강점은 대규모 추론보다 반복적인 로컬 개발 루프에 있다.
예를 들어 다음 작업에서 유용할 수 있다.
- FASTQ/BAM/VCF 처리 스크립트의 경로 버그 수정
- Snakemake rule의 입력/출력 파일명 정합성 점검
- 작은 테스트 fixture를 이용한 pipeline dry-run 자동화
config.yaml,params.json, shell wrapper 간 불일치 탐지- 논문 재현 코드의 의존성/실행 순서 정리
특히 patch-first 편집, validation, benchmark harness는 생물정보학 파이프라인의 “조금 고쳤는데 전체가 깨지는” 문제를 줄이는 데 유용하다.
다만 대용량 데이터 자체를 모델에 넣는 방식은 맞지 않다.
파일 샘플, 로그, manifest, config 중심으로 작은 컨텍스트를 설계해야 한다.
Autonomous Agent 개발 관점: 모델 성능보다 agent harness가 중요하다는 사례
SmallCode는 autonomous coding agent 설계에서 중요한 교훈을 준다.
작은 모델을 강하게 만드는 것은 단순 prompt engineering이 아니라, 다음과 같은 harness engineering이다.
- 도구를 줄여 보여주는 라우팅
- 작업 계획을 외부 상태로 유지하는 plan tracker
- 파일 수정 행위를 patch-first로 제한하는 executor
- 실패를 무한 반복하지 않는 governor
- 컨텍스트를 예산으로 다루는 memory layer
- 최후 수단으로만 호출되는 opt-in escalation
이는 autonomous agent가 실제 제품이 되려면 “생각을 잘하는 모델”만으로는 부족하다는 점을 보여준다.
안정적인 agent는 모델 주변에 정책, 상태, 검증, 복구, 관찰성 레이어를 갖는다.
기술적 한계와 주의점
- 저장소 문서의 벤치마크 수치는 유용한 참고 자료지만, 독립 재현 결과는 아니다.
- 별도 데모/논문/공식 스크린샷이 확인되지 않아, 실제 UX는 로컬 실행으로 검증해야 한다.
- web browsing, cloud escalation, MCP 도구는 편리하지만, 보안 환경에서는 명시적 allowlist와 egress 정책이 필요하다.
- 작은 모델 대상 설계인 만큼, 복잡한 대규모 리팩터링은 여전히 실패할 수 있다.
- 로컬 LLM endpoint 품질, context length, tool-call 형식 호환성이 실제 성능을 크게 좌우한다.
결론
SmallCode는 “또 하나의 코딩 챗봇”이라기보다, 작은 로컬 LLM을 개발 작업에 투입하기 위한 제약 기반 에이전트 런타임에 가깝다.
README가 강조하는 local-first, budget-managed context, forgiving parser, TODO-driven planning, patch-first editing은 모두 작은 모델의 약점을 전제로 한 설계다.
기술 블로그 관점에서 가장 흥미로운 부분은 SmallCode가 모델을 더 똑똑하게 만들려 하지 않는다는 점이다.
대신 모델이 실패하기 쉬운 행동을 구조적으로 줄인다.
이는 의료 AI, bioinformatics, autonomous agent처럼 비용·프라이버시·재현성이 중요한 분야에서 특히 참고할 만한 접근이다.
참고한 주요 저장소 파일
README.md: 프로젝트 개요, quick start, 기능, 도구 목록, API, web browsing, release/language 정보ARCHITECTURE.md: small-model 보정 전략, routing, planning, editing, memory, escalationpackage.json: 버전, runtime, dependencies, scripts, binary entryCOMPARISON.md: 기능 비교 및 저장소 자체 벤치마크 주장bench/README.md: benchmark suite와 실행 방식knowledge/README.md: keyword 기반 지식 주입 방식smallcode.toml: 기본 모델, endpoint, context budget, tools, planner 설정.env.example: 환경변수 기반 모델 설정mcp.json: MCP server mode 구성bin/tools.js: base tools, compound tools, plugin/MCP tool 결합, two-stage routingbin/executor.js: read/write/patch/bash/web/BoneScript 실행 및 안전장치bin/governor.js: verification, retry, decomposition, tool scoringbin/model_client.js: OpenAI-compatible model request와 validation helperbin/escalation.js: opt-in cloud escalation provider 구성
'AI 생성 글 정리 > tech_github' 카테고리의 다른 글
| CodeGraph — AI 코딩 에이전트를 위한 로컬 코드 지식 그래프 (0) | 2026.05.27 |
|---|---|
| Beszel — 가벼운 self-hosted 서버 모니터링 허브와 에이전트 (0) | 2026.05.27 |
| AnythingLLM — 문서 RAG, AI Agent, 모델 라우팅을 하나로 묶은 프라이버시 우선 AI 워크스페이스 (0) | 2026.05.27 |
| Open Design — 로컬 코드 에이전트를 디자인 엔진으로 바꾸는 오픈소스 Design Agent Workbench (0) | 2026.05.21 |
| ViMax — 아이디어·대본·소설을 멀티샷 영상으로 확장하는 Agentic Video Generation 프레임워크 (0) | 2026.05.21 |



