한 줄 요약
이 논문은 임상 노트만 읽고 인지 저하 우려를 찾아내는 LLM 에이전트 워크플로우를 제안합니다.
핵심은 단순 분류가 아닙니다.
LLM이 오답을 분석하고, 민감도와 특이도를 개선하는 방향으로 스스로 프롬프트를 고치는 구조입니다.

왜 중요한가
인지 저하의 조기 발견은 어렵습니다.
기존 선별 검사는 다음 한계가 있습니다.
- 대면 검사가 필요한 경우가 많습니다.
- 교육 수준과 언어 배경의 영향을 받을 수 있습니다.
- 시간과 인력이 많이 듭니다.
- 초기 징후는 진료 기록 속에 흩어져 있습니다.
반면 임상 노트에는 작은 단서가 남습니다.
예를 들면 다음과 같습니다.
- 가족이 기억 저하를 걱정했다는 기록
- 단어 찾기 어려움
- 진료 중 혼란
- 병력 설명의 불일치
- 인지 검사 결과 언급
이 논문은 이런 단서를 LLM이 체계적으로 읽어낼 수 있는지 묻습니다.
연구 질문
저자들이 던진 질문은 명확합니다.
사람이 매번 프롬프트를 고치지 않아도, LLM 에이전트들이 협업해 임상적으로 쓸 만한 인지 우려 탐지 프롬프트를 만들 수 있는가?
비교 대상은 두 가지입니다.
- 전문가 주도 워크플로우: 임상 전문가가 오답을 보고 프롬프트를 수정합니다.
- 자율 에이전트 워크플로우: 여러 LLM 에이전트가 오답을 분석하고 프롬프트를 스스로 개선합니다.
데이터 구성
연구에는 총 200명 환자와 3,338개 임상 노트가 사용됐습니다.
데이터는 두 묶음으로 나뉩니다.
| 데이터셋 | 환자 수 | 노트 수 | 인지 우려 비율 | 목적 |
|---|---|---|---|---|
| Refinement dataset | 100명 | 2,228개 | 50% | 프롬프트 개선 |
| Validation dataset | 100명 | 1,110개 | 33% | 실제 환경 일반화 평가 |
중요한 점은 두 데이터셋의 성격이 다르다는 것입니다.
Refinement dataset은 의도적으로 균형을 맞췄습니다.
Validation dataset은 더 현실적인 비율을 유지했습니다.
즉, 개발 환경과 실제 배포 환경 사이의 차이를 실험에 포함했습니다.
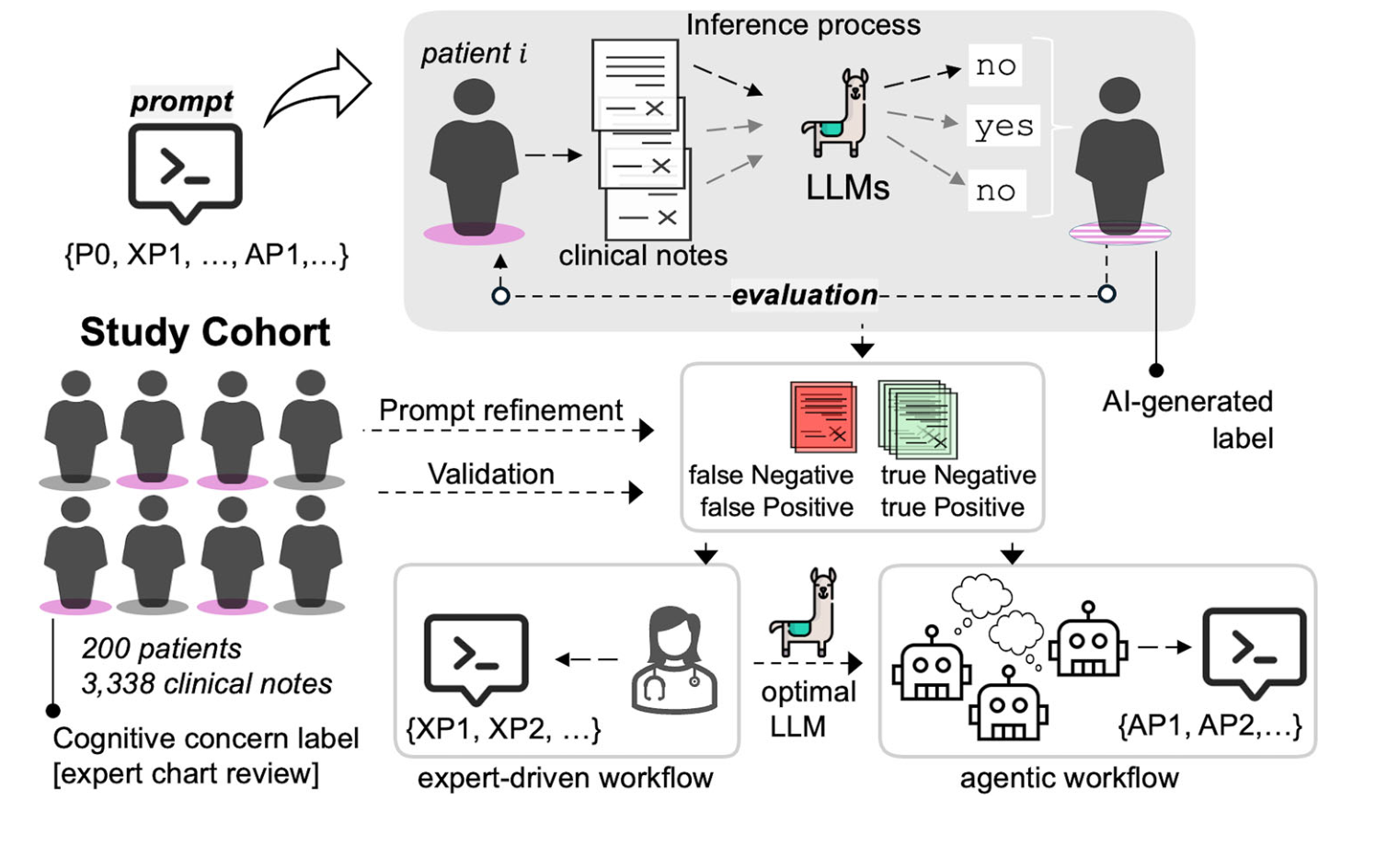
Crop 포인트: 위쪽의 임상 노트 분류 흐름과 아래쪽의 두 개선 경로가, 이 연구가 단순 예측이 아니라 프롬프트 개선 방식 자체를 비교한다는 점을 보여줍니다.
성능 지표를 쉽게 읽는 법
논문은 여러 성능 지표를 사용합니다.
수식 없이 직관적으로 보면 다음과 같습니다.
- 민감도: 실제로 인지 우려가 있는 환자를 놓치지 않는 능력입니다.
- 특이도: 인지 우려가 없는 환자를 잘못 양성으로 만들지 않는 능력입니다.
- F1 점수: 놓침과 과잉 경보 사이의 균형을 한 숫자로 요약한 값입니다.
- 정확도: 전체 환자 중 맞춘 비율입니다. 단, 양성과 음성 비율이 불균형하면 실제보다 좋아 보일 수 있습니다.
임상 선별에서는 민감도가 특히 중요합니다.
놓치면 조기 개입 기회를 잃을 수 있기 때문입니다.
하지만 특이도도 중요합니다.
특이도가 낮으면 불필요한 추가 평가와 경보가 늘어납니다.
전문가 주도 워크플로우
전문가 주도 방식은 익숙한 접근입니다.
처음에는 단순한 질문으로 시작합니다.
이 노트가 인지 우려를 시사하는가?
이후 전문가가 오답을 봅니다.
그리고 프롬프트를 고칩니다.
- 민감도가 낮으면 더 미묘한 단서를 포함하도록 지시를 추가합니다.
- 특이도가 낮으면 비인지적 문제를 배제하도록 조건을 강화합니다.
- 가족 우려, 단어 찾기, 간병인 관찰 같은 신호를 반영합니다.
이 방식은 임상 지식을 직접 반영할 수 있습니다.
단점은 확장성입니다.
새 기관, 새 질환, 새 문서 양식마다 전문가의 반복 작업이 필요합니다.
Crop 포인트: 오답이 다시 전문가에게 돌아가 프롬프트로 반영되는 폐루프 구조가, 전문가 주도 방식의 강점과 비용을 동시에 드러냅니다.
자율 에이전트 워크플로우
논문의 핵심은 자율 에이전트 구조입니다.
이 시스템은 다섯 종류의 에이전트를 사용합니다.
| 에이전트 | 역할 |
|---|---|
| Specialist | 임상 노트를 읽고 인지 우려 여부를 판단합니다. |
| Sensitivity Improver | 놓친 양성 사례를 분석해 더 잘 잡도록 프롬프트를 고칩니다. |
| Specificity Improver | 잘못 양성으로 분류한 사례를 분석해 과잉 탐지를 줄입니다. |
| Sensitivity Summarizer | 민감도 개선 제안을 하나의 프롬프트 개선안으로 정리합니다. |
| Specificity Summarizer | 특이도 개선 제안을 하나의 프롬프트 개선안으로 정리합니다. |
작동 방식은 순차적입니다.
먼저 민감도가 충분하지 않으면, 민감도 개선 경로를 탑니다.
민감도가 충분해진 뒤에는 특이도 개선 경로를 탑니다.
이렇게 한 번에 하나의 목표만 고치도록 설계했습니다.
상충되는 프롬프트 수정이 동시에 들어가는 일을 줄이기 위해서입니다.

Crop 포인트: 가운데의 성능 평가 분기와 오른쪽의 개선·요약 에이전트들이, 자율 시스템이 어떤 기준으로 스스로 수정 방향을 선택하는지 보여줍니다.
사용한 LLM
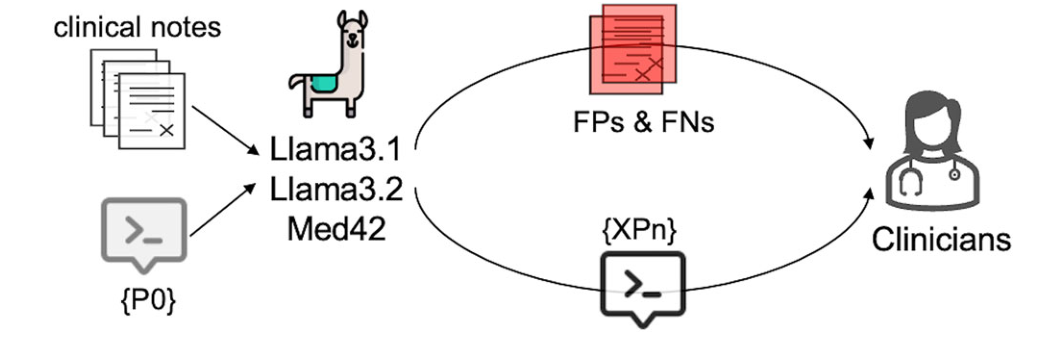
저자들은 세 모델을 비교했습니다.
- Llama 3.1 8B Instruct
- Llama 3.2 3B Instruct
- Med42 v2 8B
최종 자율 에이전트 워크플로우에는 Llama 3.1이 사용됐습니다.
이 모델이 성능과 배포 가능성 사이에서 가장 균형이 좋았기 때문입니다.
흥미로운 점은 의료 특화 모델인 Med42가 항상 우수하지 않았다는 것입니다.
이 연구에서는 중간 규모의 범용 모델이 더 안정적인 결과를 보였습니다.
주요 결과 1: 균형 데이터에서는 에이전트가 더 강했다
재판정 후 기준으로 보면, 균형 잡힌 refinement dataset에서는 자율 에이전트가 전문가 주도 방식보다 좋았습니다.
| 데이터셋 | 방식 | 민감도 | 특이도 | F1 점수 | 정확도 |
|---|---|---|---|---|---|
| Refinement | Agentic workflow | 0.91 | 0.95 | 0.93 | 0.93 |
| Refinement | Expert-driven workflow | 0.84 | 0.91 | 0.87 | 0.88 |
의미는 분명합니다.
양성과 음성이 균형 잡힌 조건에서는 에이전트 워크플로우가 두 방향을 모두 잘 맞췄습니다.
즉, 자율 프롬프트 개선이 단순한 실험적 장식이 아니라 실제 성능 향상으로 이어졌습니다.
주요 결과 2: 실제 환경에서는 민감도가 떨어졌다
현실에 가까운 validation dataset에서는 양상이 달라졌습니다.
| 데이터셋 | 방식 | 민감도 | 특이도 | F1 점수 | 정확도 |
|---|---|---|---|---|---|
| Validation | Agentic workflow | 0.62 | 0.98 | 0.74 | 0.88 |
| Validation | Expert-driven workflow | 0.82 | 0.93 | 0.81 | 0.90 |
자율 에이전트는 특이도가 매우 높았습니다.
인지 우려가 없는 환자를 불필요하게 양성으로 분류하는 일은 적었습니다.
하지만 민감도는 낮아졌습니다.
즉, 일부 실제 인지 우려 사례를 놓쳤습니다.
전문가 주도 방식은 더 균형적이었습니다.
민감도와 F1 점수에서 더 나은 일반화 성능을 보였습니다.
왜 이런 차이가 생겼나
핵심은 유병률 변화입니다.
프롬프트를 다듬은 데이터에서는 인지 우려 비율이 50%였습니다.
검증 데이터에서는 33%였습니다.
개발 환경에서는 양성과 음성이 비슷했습니다.
실제 환경에서는 음성이 더 많았습니다.
이 차이가 자율 에이전트를 더 보수적으로 만들었습니다.
결과적으로 false positive를 줄이는 데는 강했지만, subtle positive를 놓치는 경향이 생겼습니다.
이 논문이 중요한 이유는 여기에 있습니다.
성능 저하를 숨기지 않고, 실제 배포 조건에서 어떤 문제가 생기는지 드러냈습니다.
재판정 결과: AI가 틀린 것처럼 보였지만, 일부는 아니었다
저자들은 LLM 예측과 기존 인간 라벨이 어긋난 사례를 다시 검토했습니다.
그 결과 일부 “오답”은 실제로는 AI의 판단이 임상적으로 타당했습니다.
특히 validation dataset에서 apparent false negative 16건 중 7건은 재판정 결과 자율 에이전트 판단이 맞는 것으로 평가됐습니다.
이는 약 44%입니다.
의미는 큽니다.
임상 AI 평가에서 기존 인간 라벨이 항상 완전한 정답은 아닐 수 있습니다.
특히 차트 리뷰 기반 라벨은 리뷰 당시 접근한 정보, 판단 기준, 문서 구조에 영향을 받습니다.
자율 에이전트가 노트에 근거가 부족한 경우를 보수적으로 음성 처리한 것이 오히려 타당한 사례도 있었습니다.
진짜 오류는 어디서 나왔나
재판정 후에도 남은 오류에는 패턴이 있었습니다.
주요 원인은 세 가지였습니다.
- 문서 구조 문제
인지 우려가 문제 목록에는 있었지만, 본문 서술에는 충분한 근거가 없었습니다. - 도메인 지식 공백
실어증이나 제한된 건강 인식 같은 단서를 인지 우려로 충분히 연결하지 못했습니다. - 출력 모호성
에이전트 출력 안에 서로 충돌하는 판단 신호가 남아 있었습니다.
이 패턴은 향후 개선 방향을 보여줍니다.
단순히 모델을 더 크게 만드는 것보다, 문서 구조 이해와 결정 프로토콜을 더 정교하게 만드는 일이 중요합니다.
Lexicon NLP와의 비교
저자들은 규칙 기반 NLP도 비교했습니다.
이 방식은 정해진 단어 목록을 찾습니다.
예를 들면 다음 범주입니다.
- 인지 관련 약물
- 진단명
- 기억 문제
- 인지 평가
- 정신 상태 변화
- 행동 증상
이 접근은 투명합니다.
하지만 문맥 이해가 약합니다.
Validation dataset에서 성능이 떨어졌고, LLM 기반 반복 개선 방식보다 일반화가 제한적이었습니다.
임상 노트에는 단어 자체보다 문맥이 중요합니다.
예를 들어 “기억 저하 없음”과 “가족이 기억 저하를 걱정함”은 완전히 다릅니다.
규칙 기반 방식은 이런 차이를 충분히 다루기 어렵습니다.
이 논문의 기여
이 연구의 기여는 세 가지입니다.
1. 자율 에이전트 기반 프롬프트 개선을 임상 과제에 적용
시스템은 사람의 개입 없이 오답을 보고 프롬프트를 개선했습니다.
이는 프롬프트 엔지니어링을 수작업에서 반자동·자동 구조로 옮기는 시도입니다.
2. 해석 가능한 구조 유지
블랙박스 최적화가 아닙니다.
각 에이전트의 역할이 분리돼 있습니다.
어떤 오답이 어떤 개선 제안으로 이어졌는지 추적할 수 있습니다.
임상 AI에서는 이 점이 중요합니다.
3. 실제 배포 조건의 위험을 드러냄
균형 데이터에서 좋은 모델이 현실적 유병률에서는 민감도를 잃을 수 있습니다.
이 논문은 그 차이를 실험적으로 보여줍니다.
한계
이 연구는 가능성을 보여주지만, 바로 임상 배포할 수 있는 수준은 아닙니다.
주요 한계는 다음과 같습니다.
- 단일 의료기관 데이터에 기반합니다.
- 환자군이 주로 White, non-Hispanic으로 구성됐습니다.
- 외부 기관 검증이 없습니다.
- 임상 노트만 사용했습니다.
- 진단 코드, 약물, 영상, 검사 결과는 통합하지 않았습니다.
- 재판정은 한 명의 전문가가 수행했습니다.
- 실제 유병률에 맞춘 재보정이 필요합니다.
특히 선별 도구라면 민감도 저하는 중요한 문제입니다.
인지 우려 환자를 놓치는 비용이 크기 때문입니다.
실무적 해석
이 시스템은 “의사를 대체하는 진단기”라기보다 임상 노트 기반 사전 선별 보조 도구에 가깝습니다.
강점은 다음입니다.
- 대량의 비정형 노트를 빠르게 검토할 수 있습니다.
- 고특이도 설정에서는 불필요한 경보를 줄일 수 있습니다.
- 에이전트별 역할이 분리돼 감사 가능성이 있습니다.
- 상대적으로 작은 LLM으로도 구현 가능성을 보였습니다.
하지만 실제 적용 전에는 다음이 필요합니다.
- 병원별 문서 양식에 맞춘 보정
- 목표 유병률에 맞춘 threshold 조정
- 더 다양한 인구집단에서 검증
- 여러 전문가가 참여하는 재판정
- 진단 코드, 약물, 검사 결과와의 결합
핵심 메시지
이 논문은 “LLM이 임상 노트를 읽을 수 있다”는 단순한 주장을 넘습니다.
더 중요한 메시지는 이것입니다.
임상 AI는 좋은 평균 성능만으로 충분하지 않다. 실제 유병률, 라벨 품질, 문서 구조, 민감도와 특이도의 균형까지 함께 검증해야 한다.
자율 에이전트 워크플로우는 유망합니다.
특히 전문가 자원이 부족한 환경에서 확장 가능한 프롬프트 개선 방식이 될 수 있습니다.
다만 선별 도구로 쓰기 위해서는 더 높은 민감도와 외부 검증이 필요합니다.
Source
- Jiazi Tian et al. “An autonomous agentic workflow for clinical detection of cognitive concerns using large language models.” npj Digital Medicine, 2026, 9:51.
- DOI: https://doi.org/10.1038/s41746-025-02324-4
- Code: https://github.com/clai-group/Pythia
- 원문은 Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License로 공개되어 있습니다.
'AI 생성 글 정리 > medical' 카테고리의 다른 글
| A multi-agent system for automating scientific discovery 논문 정리 (0) | 2026.05.29 |
|---|---|
| [An agentic system for rare disease diagnosis with traceable reasoning] 논문 정리 (0) | 2026.05.29 |
| SleepFM 논문 정리 (0) | 2026.05.18 |
| AI agent in healthcare 논문 정리 (0) | 2026.05.18 |
| Accurate discharge summary generation using fine tuned large language models with self evaluation 논문 핵심 정리 (0) | 2026.04.07 |



