핵심 요약
이 논문은 ERA(Empirical Research Assistance) 를 소개한다.
ERA는 과학자가 직접 오래 작성하던 실험용 소프트웨어를 자동으로 만들고 개선하는 시스템이다.
핵심은 단순 코드 생성이 아니다.
- 문제를 점수로 평가 가능한 과제로 정의한다.
- LLM이 기존 코드를 다시 쓴다.
- 샌드박스가 코드를 실행하고 점수를 낸다.
- 트리 탐색이 다음에 고칠 후보를 고른다.
- 논문, 기존 방법, 이전 후보를 재조합해 새 아이디어를 만든다.
결과는 넓다.
- 단일세포 RNA 데이터 통합
- COVID-19 입원 예측
- 일반 시계열 예측
- 위성 이미지 분석
- 제브라피시 뇌 활동 예측
- 어려운 적분 문제
논문의 주장도 명확하다.
기계가 점수를 매길 수 있는 과학 문제에서는, 소프트웨어 개발 자체가 대규모 탐색 문제로 바뀔 수 있다.

왜 중요한가
많은 과학 연구는 소프트웨어에 막힌다.
모델을 만들고, 실험하고, 고치고, 다시 평가해야 한다.
이 과정은 보통 느리다.
특히 다음 조건이 겹치면 더 느려진다.
- 데이터가 복잡하다.
- 평가 지표가 여러 개다.
- 기존 논문 아이디어가 많다.
- 구현 선택지가 너무 많다.
- 어떤 조합이 좋은지 미리 알 수 없다.
ERA는 이 병목을 다룬다.
사람처럼 “아이디어를 떠올리고 코드를 고치는” 방식이 아니라, 후보 코드를 많이 만들고 점수로 밀어붙이는 방식을 쓴다.
ERA의 기본 구조
ERA의 입력은 두 가지다.
- 점수로 평가할 수 있는 과학 문제
- 그 문제를 풀기 위한 연구 아이디어
그다음 시스템은 반복한다.
- LLM이 후보 코드를 작성하거나 수정한다.
- 코드를 샌드박스에서 실행한다.
- 평가 점수를 얻는다.
- 트리 탐색이 다음 후보를 고른다.
- 점수가 좋아지면 그 방향을 더 파고든다.
- 막히면 과거 후보로 돌아가 다른 가지를 탐색한다.

Crop 포인트: 아래쪽 막대그래프는 단발 생성보다 후보 트리를 유지하는 탐색이 더 높은 성능을 만든다는 점을 보여준다.
트리 탐색의 직관은 단순하다.
좋은 후보는 더 깊게 본다.
하지만 아직 충분히 보지 않은 후보도 버리지 않는다.
그래서 한 코드 변형이 막혀도, 다른 과거 후보에서 다시 출발할 수 있다.
이 차이가 “best-of-1000” 방식과 ERA를 가른다.
best-of-1000은 많은 답을 한 번에 뽑는다.
ERA는 좋아 보이는 답을 바탕으로 다음 실험을 설계한다.
연구 아이디어를 코드로 바꾸는 방식
ERA는 프롬프트에 연구 아이디어를 넣는다.
아이디어의 출처는 다양하다.
- 전문가 설명
- 논문 요약
- 기존 방법 설명
- 이전에 나온 좋은 코드
- 두 방법의 재조합
- Deep Research류 도구의 제안
- AI co-scientist의 제안
중요한 점은 이 아이디어가 그대로 최종 답이 되지는 않는다는 것이다.
아이디어는 코드 변형의 방향이 된다.
실제로 좋은지는 실행 점수가 판단한다.
결과 1: 단일세포 RNA 데이터 통합
첫 번째 핵심 실험은 scRNA-seq batch integration이다.
단일세포 RNA 데이터는 여러 실험실, 장비, 샘플에서 나온다.
그래서 데이터에는 두 종류의 차이가 섞인다.
- 실제 생물학적 차이
- 실험 환경에서 생긴 배치 효과
좋은 통합 방법은 배치 효과를 줄이면서도 생물학적 차이를 보존해야 한다.
ERA는 OpenProblems v2.0.0 벤치마크에서 평가됐다.
논문 기준 핵심 결과는 다음과 같다.
- 별도 조언 없이도 강한 성능을 냈다.
- 기존 9개 방법 중 8개에서, ERA 구현이 해당 공개 방법보다 높은 전체 점수를 냈다.
- BBKNN 기반 ERA 구현은 당시 최고 공개 방법보다 전체 점수를 14% 개선했다.
- 전체 87개 생성 방법 중 40개가 공개 리더보드의 모든 비제어 방법을 앞섰다.

Crop 포인트: 오른쪽 성능 표와 아래쪽 막대열은 ERA가 기존 방법을 단순 복제한 것이 아니라, 여러 아이디어 조합에서 더 높은 점수를 찾았다는 점을 보여준다.
가장 흥미로운 부분은 BBKNN 사례다.
ERA는 BBKNN을 그대로 구현하는 데서 멈추지 않았다.
ComBat 방식으로 먼저 배치 차이를 줄인 임베딩을 만들고, 그 위에서 BBKNN식 이웃 그래프를 구성했다.
즉, 전역적인 배치 보정과 지역적인 이웃 보정을 결합했다.
이 조합이 성능 향상의 핵심이었다.
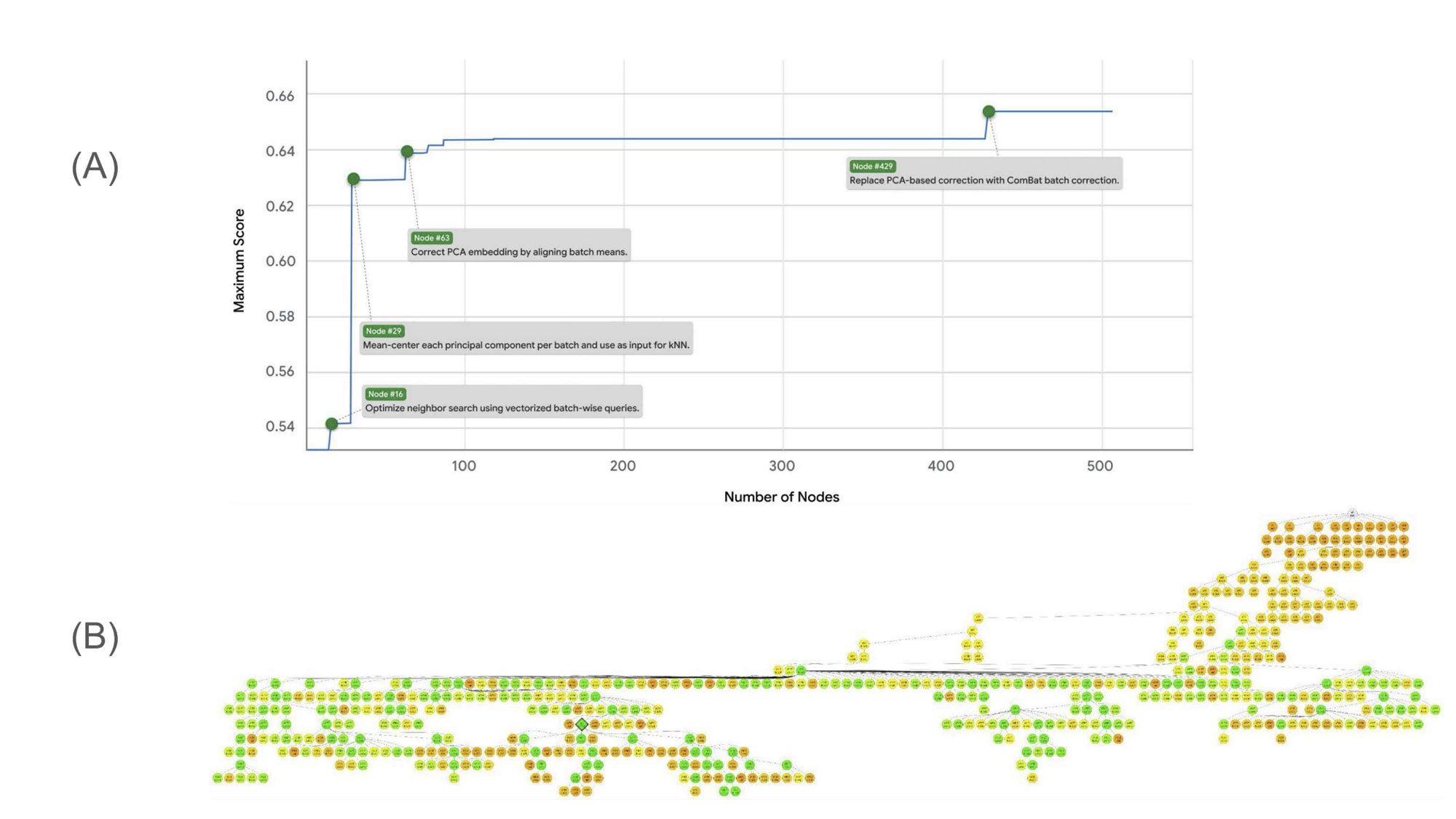
Crop 포인트: 위쪽 계단형 곡선의 급격한 점프는 특정 코드 수정이 점수를 한 번에 끌어올리는 “돌파 지점”을 나타낸다.
추가 분석도 이 해석을 뒷받침한다.
BBKNN 구성요소를 하나씩 제거했을 때, ComBat 기반 임베딩과 BBKNN 결합이 특히 중요했다.
ERA의 강점은 하이퍼파라미터 조정만이 아니었다.
좋은 전처리, 임베딩, 그래프 구성 방식을 함께 찾았다.

Crop 포인트: 막대 비교는 성능 향상이 단일 구성요소가 아니라 ComBat 기반 임베딩과 BBKNN 조합에서 크게 나온다는 점을 보여준다.
결과 2: COVID-19 입원 예측
두 번째 핵심 실험은 미국 COVID-19 입원 예측이다.
비교 대상은 CovidHub다.
CovidHub는 CDC와 연결된 예측 허브로, 여러 전문가 팀의 예측을 모은다.
예측은 다음을 요구한다.
- 52개 주와 관할권
- 현재 주와 이후 3주
- 여러 분위수 기반 불확실성 예측
평가는 WIS로 이뤄진다.
WIS는 낮을수록 좋다.
정확한 예측과 적절한 불확실성 표현을 함께 본다.
ERA는 2024-2025 시즌을 대상으로 후향 평가를 수행했다.
핵심 결과는 다음과 같다.
- ERA의 Google Retrospective 모델 평균 WIS는 26이었다.
- 공식 CovidHub Ensemble의 평균 WIS는 29였다.
- ERA는 다수 주에서 ensemble보다 낮은 오류를 냈다.
- 총 14개 전략이 공식 ensemble보다 좋은 성능을 보였다.
- 그중 다수는 기존 모델 두 개를 재조합한 전략이었다.

Crop 포인트: 하단 막대그래프는 공식 ensemble보다 낮은 오류를 낸 ERA 생성 전략들이 재조합에서 많이 나왔다는 점을 보여준다.
여기서도 핵심은 재조합이다.
예를 들어 안정적인 과거 평균 기반 모델과 최근 추세에 민감한 자기회귀 모델을 결합한다.
또는 역학 모델의 구조와 머신러닝 모델의 단기 적응력을 함께 쓴다.
ERA는 이런 조합을 사람이 하나씩 실험하는 대신, 후보 코드로 만들어 점수로 검증했다.

Crop 포인트: 초록 막대가 있는 패널들은 두 부모 모델보다 나은 재조합 전략이 실제로 발견됐음을 보여준다.
결과 3: 일반 시계열 예측
세 번째 축은 GIFT-Eval이다.
GIFT-Eval은 여러 분야의 시계열 데이터를 포함한 일반 예측 벤치마크다.
ERA는 두 방식으로 평가됐다.
첫째, 데이터셋별 전용 해법을 찾았다.
이 경우 다양한 Python 라이브러리를 사용할 수 있었다.
논문은 이 방식이 2025년 5월 18일 기준 공개 리더보드 전체를 앞섰다고 보고한다.
둘째, 하나의 통합 예측 라이브러리를 만들었다.
이 방식에서는 기본 라이브러리만 허용했다.
최종 해법은 시계열을 여러 성분으로 나눠 다뤘다.
- 기본 수준
- 추세
- 계절성
- 날짜 특성
- 휴일 효과
- 최근 잔차 보정
이 접근은 화려한 블랙박스 모델보다 해석하기 쉽다.
또한 데이터셋마다 8개 설정 중 하나를 검증 데이터로 선택하게 해 범용성을 확보했다.

Crop 포인트: 위쪽 돌파 곡선은 날짜·휴일·성분 분해 같은 구조적 아이디어가 성능 개선의 계기가 됐음을 보여준다.
다른 과학 문제에서도 같은 패턴이 보였다
논문은 세 가지 추가 영역도 다룬다.
- 위성 이미지의 의미론적 분할
- 제브라피시 전체 뇌 활동 예측
- 표준 수치 알고리즘이 어려워하는 적분 문제
공통점은 같다.
정답을 사람이 직접 쓰기보다, 점수로 평가 가능한 후보 프로그램을 반복적으로 개선한다.
ERA는 이 방식으로 각 영역에서 전문가 수준 성능을 냈다고 보고한다.
왜 트리 탐색이 중요한가
논문은 ERA와 best-of-N 방식을 비교했다.
best-of-N은 많은 후보를 한꺼번에 뽑고, 가장 좋은 것을 고른다.
ERA는 좋은 후보를 바탕으로 다시 변형한다.
실험 결과는 대체로 ERA 쪽이 좋았다.
- 여러 LLM에서 ERA가 best-of-1000보다 좋은 성능을 냈다.
- 예외는 GPT-5의 단일세포 batch integration 결과였다.
- 논문은 프론티어 모델이 강해질수록 쉬운 과제는 포화될 수 있다고 본다.
- 그래도 어려운 과제에서는 탐색이 성능을 더 밀어 올린다.
직관적으로 보면 이렇다.
많은 후보를 뽑는 것만으로는 “다음 실험”이 없다.
ERA는 점수, 로그, 이전 코드 차이를 이용해 다음 실험의 출발점을 고른다.
그래서 탐색은 더 누적된다.
이 논문의 핵심 기여
1. 과학 소프트웨어 작성을 탐색 문제로 바꿨다
ERA는 코드를 완성품으로 보지 않는다.
코드는 점수를 얻기 위한 후보 실험이다.
실패한 코드도 다음 탐색의 정보가 된다.
2. LLM을 단발 생성기가 아니라 변이 생성기로 썼다
LLM은 새 코드를 “한 번에” 쓰는 역할이 아니다.
기존 코드를 읽고, 문제 설명과 연구 아이디어를 반영해 다시 쓴다.
3. 기존 논문 아이디어를 실행 가능한 후보로 바꿨다
논문 요약은 지식 저장이 아니다.
프롬프트에 들어가고, 코드가 되고, 점수로 검증된다.
4. 재조합의 효과를 실험적으로 보였다
좋은 과학 아이디어는 종종 기존 방법의 결합에서 나온다.
ERA는 이 과정을 자동화했다.
단일세포 분석과 COVID-19 예측 모두에서 재조합 전략이 강한 성능을 냈다.
한계와 주의점
ERA가 모든 과학을 자동화한다는 뜻은 아니다.
논문도 이 점을 구분한다.
ERA가 강한 영역은 다음 조건을 갖는다.
- 입력 데이터가 있다.
- 품질 점수를 자동으로 계산할 수 있다.
- 코드 실행 비용을 감당할 수 있다.
- 검증 데이터와 테스트 데이터가 분리된다.
반대로 다음 문제는 더 어렵다.
- 원인과 메커니즘을 설명해야 하는 문제
- 새로운 이론을 세워야 하는 문제
- 평가 지표 자체가 논쟁적인 문제
- 안전 영향이 큰 민감한 도메인
또한 자동화된 고성능 소프트웨어 생성은 위험도 만든다.
전문 지식 없이도 강력한 모델을 만들 수 있기 때문이다.
생명과학, 공중보건, 보안처럼 민감한 영역에서는 평가와 접근 통제가 중요하다.
읽고 나서 남는 질문
ERA의 성능은 인상적이다.
하지만 더 중요한 질문은 따로 있다.
앞으로 과학자는 무엇을 직접 설계해야 하는가?
이 논문이 암시하는 답은 다음에 가깝다.
- 문제를 점수화하는 방식
- 안전한 데이터 분리
- 의미 있는 평가 지표
- 탐색할 아이디어 공간
- 결과의 해석과 검증
코드는 점점 더 자동화될 수 있다.
하지만 어떤 문제를 풀지, 무엇을 좋은 해법으로 볼지, 결과를 어떻게 믿을지는 여전히 핵심 연구 판단이다.
정리
ERA는 과학 소프트웨어 개발을 다음 방식으로 바꾼다.
- 사람이 코드를 한 줄씩 완성한다.
- 시스템이 후보 코드를 대량 생성한다.
- 점수가 좋은 후보를 중심으로 탐색한다.
- 논문과 기존 방법을 재조합한다.
- 실험 가능한 아이디어를 빠르게 검증한다.
이 논문의 가장 큰 메시지는 단순하다.
점수로 평가 가능한 과학에서는, 시행착오 자체를 자동화할 수 있다.
그 결과 연구 속도는 “코드를 얼마나 빨리 쓰는가”가 아니라, “좋은 평가 문제를 얼마나 잘 정의하는가”에 더 크게 좌우될 수 있다.
Source
- Aygün, E. et al. “An AI system to help scientists write expert-level empirical software.” Nature, Accelerated Article Preview, 2026.
- DOI: https://doi.org/10.1038/s41586-026-10658-6
- Reference implementation: https://github.com/google-research/era
- Generated candidate solutions and tree-search viewer: https://google-research.github.io/era
'AI 생성 글 정리 > bio' 카테고리의 다른 글
| GSFM 논문 정리 (0) | 2026.05.29 |
|---|---|
| Nucleotide Transformer 논문 정리 (0) | 2026.05.29 |
| RFdiffusion3 논문 정리 (0) | 2026.05.18 |
| RFdiffusion2 논문 정리 (0) | 2026.05.18 |
| Latent-Y: A Lab-Validated Autonomous Agent for De Novo Drug Design 논문 정리 (0) | 2026.04.27 |



