title: "MEDOPENCLAW 논문 정리: 정적 2D를 넘어 전체 검사를 읽는 의료영상 에이전트"
description: "MEDOPENCLAW와 MEDFLOW-BENCH가 제안한 full-study reasoning, auditability, 그리고 tool-use paradox를 정리한 글"
tags:
- medical imaging
- radiology
- VLM
- agent
- benchmark
paper: "MEDOPENCLAW: Auditable Medical Imaging Agents Reasoning over Uncurated Full Studies"
paper_type: "arXiv preprint"
date: "2026-03-25"
MEDOPENCLAW 논문 정리
한 줄 요약
이 논문은 새로운 의료 진단 모델 자체를 제안하는 논문이라기보다, 의료영상 에이전트가 미리 골라진 2D 이미지가 아니라 전체 3D 검사(full study)를 실제 뷰어에서 탐색하도록 만드는 감사 가능한 런타임(MEDOPENCLAW)과, 이를 평가하는 인터랙티브 벤치마크(MEDFLOW-BENCH)를 제안한 논문이다. 그리고 가장 중요한 결과는, 뷰어를 직접 탐색하는 수준의 study-level reasoning은 이미 가능해 보이지만, 전문 툴을 추가한다고 자동으로 성능이 좋아지지는 않는다는 점이다.
이 논문을 30초 안에 이해하기
- 문제의식: 기존 의료 VQA/멀티모달 벤치마크는 대부분 이미 골라진 2D 이미지를 입력으로 준다. 하지만 실제 영상의학 판독은 전체 3D 검사, 여러 시퀀스/모달리티, 연속 슬라이스 탐색, 윈도우 조절, 퓨전, 측정 등으로 이루어진다.
- 제안 1:
MEDOPENCLAW라는 bounded runtime을 만들어 3D Slicer 같은 의료영상 뷰어를 에이전트가 안전하고 감사 가능하게 조작하도록 한다. - 제안 2:
MEDFLOW-BENCH라는 benchmark를 만들어, 전체 study를 탐색하며 답을 내는 과정을 평가한다. - 핵심 결과: frontier VLM은 viewer-only 환경에서는 꽤 쓸 만하지만, segmentation toolpack을 쥐여주면 오히려 성능이 떨어질 수 있다.
- 핵심 병목: 논문은 그 이유를 정밀한 spatial grounding 부족으로 본다. 즉, 툴을 잘 쓰려면 ‘어디를 어떻게 찍어야 하는지’를 밀리미터 수준으로 제어해야 하는데, 현재 모델은 아직 거기까지는 약하다는 것이다.
왜 이 논문이 중요한가
이 논문이 던지는 메시지는 단순하다.
의료영상 AI를 실제 워크플로에 가깝게 평가하려면, 정적인 이미지 문제풀이가 아니라 전체 검사 탐색 + 근거 수집 + 감사 가능한 실행 흔적까지 봐야 한다.
기존 벤치마크는 정답 여부만 보기에 좋았지만, 모델이 어디를 봤는지, 어떤 근거로 판단했는지, 그 과정이 재현 가능한지는 잘 드러나지 않았다. 반면 실제 임상에서는 결과만 맞는 것보다도 판독 과정이 해석 가능하고 검증 가능해야 한다. 이 논문은 그 간극을 정면으로 건드린다.
블로그 포인트
이 논문의 진짜 기여는 “의료영상용 GPT가 더 똑똑해졌다”가 아니다. 오히려 의료영상 에이전트를 어떻게 안전하게 실행하고, 어떻게 현실적인 방식으로 평가할 것인가에 가깝다.
Figure 1. 기존 정적 벤치마크 vs 제안된 감사 가능한 워크플로

Figure 1이 보여주는 것
왼쪽은 익숙한 구조다. 미리 선택된 2D 이미지를 넣고, 블랙박스 모델이 답을 낸다. 여기서는 모델이 왜 그 답을 냈는지 잘 보이지 않는다.
오른쪽은 MEDOPENCLAW 기반 구조다. 백본 모델이 3D Slicer 뷰어를 bounded action으로 조작하고, 그 과정에서 visible trace, evidence objects, grounded answer가 남는다. 즉, 단순히 “맞췄다”가 아니라 어떤 시리즈를 골랐고, 어떤 슬라이스를 보고, 어떤 시각적 근거를 모았는가까지 남는다.
여기서 읽어야 할 포인트
- MEDOPENCLAW는 모델이 아니다.
- 논문이 제안하는 핵심은 새로운 backbone이 아니라, backbone 위에서 동작하는 runtime/API layer다.
- 감사 가능성(auditability)이 설계의 중심이다.
- 실행 흔적이 남는다는 것은 단순 로그 수집이 아니라, 임상 신뢰성과 규제 관점에서 매우 중요하다.
- 이 구조는 벤치마크이면서 동시에 코파일럿 구조다.
- 논문은 이 런타임 위에
MEDCOPILOT같은 human-in-the-loop assistant가 올라갈 수 있다고 본다.
- 논문은 이 런타임 위에
제안 1: MEDOPENCLAW는 무엇인가
논문에서 MEDOPENCLAW는 다음처럼 이해하면 쉽다.
정의
의료영상 뷰어를 외부에서 bounded하게 조작하게 해주는 실행 계층이다.
즉, 모델이 직접 파이썬 콘솔에 임의 코드를 날리는 것이 아니라, 미리 정의된 함수 집합만 호출하게 만든다. 이 점이 중요하다. 논문은 3D Slicer의 내장 Python 콘솔에 임의 코드를 실행하게 두면 공격 표면이 커지고, 감사 가능성이 약해지며, 배포가 복잡해진다고 본다. 그래서 raw Python 실행을 막고, 명시적으로 정의된 조작만 허용한다.
MEDOPENCLAW의 3개 계층
- Primitive viewer actions
- 시리즈 선택
- 슬라이스 스크롤
- window/level 조절
- zoom 등
- Evidence operations
- 북마크된 뷰 저장
- 마스크/증거 객체 내보내기
- 측정 로그 저장
- Optional expert tools
- segmentation
- quantitative analysis
- 예: MONAI 기반 tool pack
왜 bounded interface가 중요한가
이 논문에서 bounded interface는 단순한 엔지니어링 취향이 아니다. 오히려 다음 세 가지를 동시에 만족시키는 장치다.
- 안전성: 모델이 임의 스크립트를 실행하지 못함
- 감사 가능성: 어떤 호출이 있었는지 명확히 남음
- 평가 가능성: primitive action만 허용한 경우와 expert tool까지 허용한 경우를 분리해서 비교할 수 있음
블로그 포인트
많은 agent 논문이 “툴을 연결했다”에서 멈추는데, 이 논문은 한 걸음 더 들어가 툴 호출 공간 자체를 임상 친화적으로 제한했다는 점이 차별점이다.
제안 2: MEDFLOW-BENCH는 무엇인가
MEDFLOW-BENCH는 image-level이 아니라 study-level로 정의된 benchmark다.
즉, 한 장의 그림을 보고 답하는 것이 아니라, 하나의 episode가 아래 요소로 구성된다.
- 전체 volumetric exam과 study metadata
- case-level 또는 study-level question prompt
- track별로 허용된 action space
- canonical answer schema
현재 포함된 두 개의 clinical module
1) Brain MRI module
- 데이터셋: UCSF-PDGM
- 목표: 다중 시퀀스 뇌종양 MRI를 이용한 case-level diagnosis
2) Lung CT/PET module
- 데이터셋: NSCLC radiogenomics dataset
- 목표: 다음 5개 structured prediction
- 종양 위치 (tumor location)
- 병리학적 T stage
- 병리학적 N stage
- histology
- histopathological grade
정답 프로토콜
- MCQ track: 보기 제공
- Open-ended track: 보기 없이 답변, canonical answer와 LLM judge로 robustness 평가
왜 MEDFLOW-BENCH가 기존 벤치마크와 다른가
논문이 강조하는 차이는 아래 다섯 가지다.
| 항목 | 기존 정적 의료영상 QA 벤치마크 | MEDFLOW-BENCH |
|---|---|---|
| 입력 형태 | 미리 선택된 2D 이미지 | 전체 study에 대한 interactive access |
| 교차 모달/시퀀스 reasoning | 제한적 | 가능 |
| 능동적 탐색(active exploration) | 거의 없음 | 있음 |
| differential diagnosis | 제한적 | 포함 |
| agentic execution 필요성 | 낮음 | 높음 |
논문은 특히 MEDFLOW-BENCH가 full-study interactive access, cross-modality case, active exploration, differential diagnosis, agentic execution을 동시에 갖춘 benchmark라고 주장한다.
블로그 포인트
이 benchmark의 핵심은 “더 어려운 문제를 냈다”가 아니라, 문제의 형태를 실제 판독 절차에 더 가깝게 바꿨다는 데 있다.
세 가지 평가 트랙: 이 설계가 꽤 영리하다
논문에서 MEDFLOW-BENCH는 모든 방법을 한 리더보드에 섞지 않고 세 개의 트랙으로 나눈다.
Track A: Viewer-Only
primitive viewer action만 사용한다. 즉, 스크롤하고 시리즈 바꾸고 window 조정하는 수준만 허용한다.
- 평가 포인트: 순수한 full-study visual perception
- 관심사: 시각 탐색, slice-to-slice synthesis, sequence-level reasoning
Track B: Tool-Use
expert tool과 evidence tool까지 허용한다.
- 평가 포인트: 툴을 언제, 어떻게, 얼마나 정확하게 써야 하는가
- 관심사: parameter 설정, 반환 artifact 해석, 진단 흐름에 통합
Track C: Open-Method
MEDOPENCLAW를 우회해 raw case를 직접 소비하는 다른 파이프라인도 허용한다.
- 평가 포인트: benchmark를 특정 시스템에만 묶지 않음
- 의미: 향후 native 3D foundation model, study compression encoder, non-Slicer pipeline도 참가 가능
왜 이 설계가 좋은가
이 구조 덕분에 논문은 두 가지를 동시에 얻는다.
- 런타임 자체의 기여를 분리해서 볼 수 있다.
- benchmark를 특정 구현에 종속시키지 않는다.
즉, 이 논문은 “우리 시스템을 써야만 하는 벤치마크”가 아니라, 나중에 더 좋은 3D 모델이 나와도 그대로 쓸 수 있는 평가 틀을 지향한다.
Figure 2. 감사 가능한 실행 trace가 실제로 어떻게 생겼는가
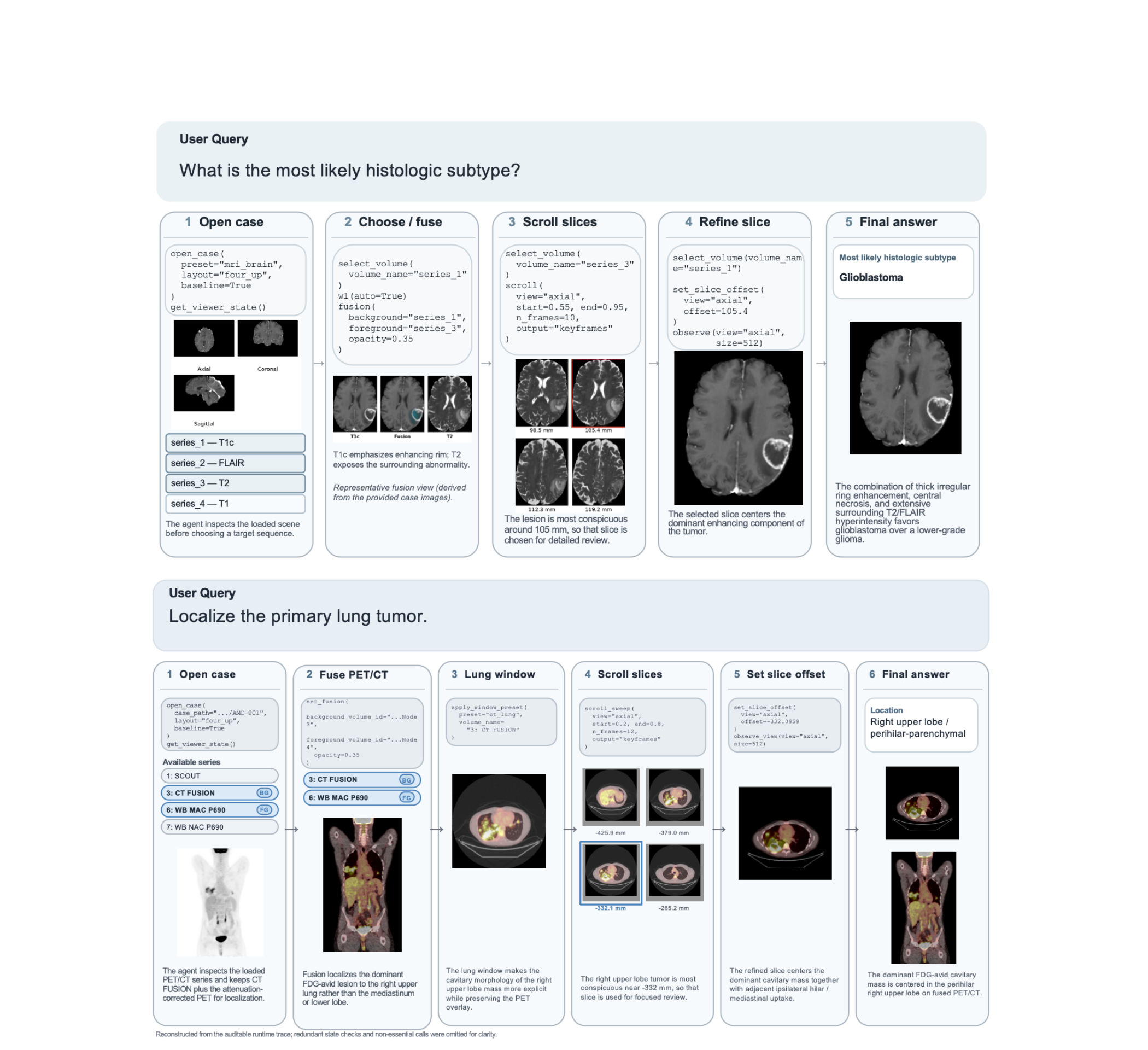
이 그림은 논문의 핵심을 가장 잘 보여준다.
위쪽 Brain MRI 예시에서는 대략 이런 흐름이 보인다.
- case 열기
- 주요 MRI 시퀀스 확인
- 필요한 시퀀스/퓨전 보기 선택
- 슬라이스를 훑으며 suspicious slice 찾기
- target slice를 정교하게 맞추기
- 최종 subtype 답변 제시
아래쪽 Lung CT/PET 예시도 비슷하다.
- PET/CT case 열기
- PET/CT fusion
- lung window 적용
- axial slice scroll
- 위치 refinement
- 최종 종양 위치 답변
Figure 2에서 꼭 봐야 할 점
이 그림은 단순 데모가 아니다. 논문이 말하는 auditability를 시각적으로 구현한 예시다.
즉,
- 어떤 명령을 내렸는지
- 어떤 이미지가 intermediate evidence였는지
- 최종 답이 어떤 흐름으로 나왔는지
를 나중에 재구성할 수 있다.
블로그 포인트
실제 의료영상 에이전트 평가에서 중요한 것은 “최종 답변 텍스트”보다도, 답을 만들기까지의 관찰 경로가 재생 가능한가일 수 있다. Figure 2는 바로 그 점을 가장 잘 보여준다.
실험 결과: 무엇이 보였나
1) Viewer-Only에서도 이미 꽤 된다
논문은 GPT-5.4, GPT-5-mini, gemini-3.1-flash-preview, gemini-3.1-pro-preview를 Track A에서 비교한다.
핵심 숫자만 먼저 보면
| 모델 | Brain MRI 정확도 | Lung CT/PET 전체 정확도 | 해석 |
|---|---|---|---|
| GPT-5.4 | 0.61 | 0.32 | Brain MRI에서 강함 |
| GPT-5-mini | 0.43 | 0.20 | 상대적으로 낮음 |
| gemini-3.1-flash-preview | 0.56 | 0.52 | Lung CT/PET 전체 최고 |
| gemini-3.1-pro-preview | 0.63 | 0.31 | Brain MRI 최고 |
결과 해석
- Brain MRI에서는
gemini-3.1-pro-preview가 0.63으로 최고,GPT-5.4가 0.61로 근접하다. - Lung CT/PET overall에서는
gemini-3.1-flash-preview가 0.52로 가장 높다. - 즉, 적어도 뷰어를 조작하며 전체 검사를 읽는 수준의 reasoning 자체는 frontier 모델에게 이미 어느 정도 가능해 보인다.
그런데 세부 task로 내려가면 어렵다
논문은 Lung CT/PET 세부 task에서 특히 Histopathological Grade 같은 fine-grained prediction이 어렵다고 지적한다. 즉, “어디에 종양이 있는가” 같은 거시적 문제와 “세밀한 병리 등급” 같은 문제 사이에는 난이도 차이가 매우 크다.
Viewer-Only 세부 성능 정리 (논문 Table 2 기반)
| Model | Brain MRI | Lung Overall | Tumor Location | T Stage | Pathological N Stage | Histology | Histopath. Grade |
|---|---|---|---|---|---|---|---|
| GPT-5.4 | 0.61 | 0.32 | 0.46 | 0.32 | 0.38 | 0.36 | 0.07 |
| GPT-5-mini | 0.43 | 0.20 | 0.14 | 0.17 | 0.09 | 0.06 | 0.04 |
| gemini-3.1-flash-preview | 0.56 | 0.52 | 0.42 | 0.21 | 0.83 | 0.72 | 0.44 |
| gemini-3.1-pro-preview | 0.63 | 0.31 | 0.43 | 0.31 | 0.35 | 0.34 | 0.11 |
읽는 팁
gemini-3.1-flash-preview는 Lung CT/PET에서 surprisingly strong하다.GPT-5.4는 Brain MRI와 종양 위치 같은 비교적 거시적인 판단에서 나쁘지 않다.- Grade prediction은 전반적으로 매우 어렵다.
2) 이 논문의 진짜 핵심 결과: Tool-Use Paradox
가장 인상적인 결과는 여기다.
직관적으로는 segmentation toolpack 같은 expert tool을 더 주면 성능이 올라가야 할 것 같다. 그런데 논문 결과는 꼭 그렇지 않다. 오히려 성능이 떨어진다.
Tool-Use ablation (논문 Table 3 기반)
| Backbone | 설정 | Brain MRI | Lung CT/PET |
|---|---|---|---|
| GPT-5-mini | primitive tools only | 0.43 | 0.20 |
| GPT-5-mini | + segmentation toolpacks | 0.45 | 0.14 |
| GPT-5.4 | primitive tools only | 0.61 | 0.32 |
| GPT-5.4 | + segmentation toolpacks | 0.57 | 0.27 |
어떻게 해석해야 하나
GPT-5.4는 segmentation toolpack을 추가하자 Brain MRI 0.61 → 0.57, Lung CT/PET 0.32 → 0.27로 떨어졌다.GPT-5-mini는 Brain MRI에서는 아주 소폭 올라갔지만, Lung CT/PET는 0.20 → 0.14로 떨어졌다.
즉, 전문 툴 접근권을 준다고 해서 agentic execution이 좋아지는 것은 아니다.
논문이 제시한 원인
논문은 그 이유를 precise spatial grounding의 부족으로 설명한다.
예를 들어 Local Threshold Segmentation Tool을 쓴다고 하자. 이때 모델은 segmentation 알고리즘이 시작할 정확한 공간 좌표를 제시해야 한다. 그런데 현재 VLM은 이 좌표를 밀리미터 단위로 안정적으로 찍는 데 약하다. 그러면 segmentation mask가 틀어지고, 모델은 잘못 생성된 evidence를 다시 근거로 삼게 되어 후속 reasoning까지 무너질 수 있다.
블로그 포인트
이건 꽤 중요한 메시지다.
앞으로 의료 AI의 병목은 “지식이 부족해서”가 아니라, 툴을 정밀하게 조작할 수 있을 만큼 공간적으로 정확하지 않아서일 수 있다.
즉, reasoning benchmark를 잘 풀더라도, 실제 임상 도구를 안정적으로 쓰려면 정교한 spatial control이 별도의 난제로 남아 있다는 뜻이다.
이 논문에서 꼭 기억할 핵심 메시지 5가지
1) 이건 ‘모델 논문’보다 ‘워크플로 논문’이다
핵심은 더 큰 백본이 아니라, full-study 탐색을 감사 가능하게 만드는 실행 구조와 평가 틀이다.
2) 의료영상 평가의 중심을 2D 정답 맞히기에서 study-level exploration으로 옮긴다
실제 판독처럼 시리즈를 고르고, 슬라이스를 넘기고, 근거를 모으는 과정을 평가 대상으로 만든다.
3) auditability는 옵션이 아니라 전제다
의료에서는 black-box가 특히 문제가 된다. 이 논문은 실행 trace를 남기는 것을 후처리가 아니라 시스템 설계 원리로 둔다.
4) viewer-native reasoning은 이미 가능성이 보인다
적어도 Track A 결과만 보면, frontier 모델은 실제 뷰어를 탐색하면서 꽤 의미 있는 비율로 study-level task를 풀 수 있다.
5) 하지만 tool-augmented execution은 아직 어렵다
전문 툴 사용은 오히려 성능을 떨어뜨릴 수 있다. 병목은 세밀한 spatial grounding이다.
논문의 한계
논문 자체도 현재 버전을 foundational first release라고 본다. 즉, 아직은 시작점이다.
주요 한계
- 현재 모듈이 Brain MRI와 Lung CT/PET 두 축에 집중되어 있다.
- 초기 버전 실험은 MCQ 중심이다.
- Open-ended 설정은 LLM judge를 사용하므로 향후 judge robustness 이슈가 더 논의될 수 있다.
- 실제 임상 배치 수준의 end-to-end workflow에는 아직 이르다.
- segmentation toolpack 성능 자체보다, tool control 문제 때문에 결과가 제한된다.
앞으로 볼 포인트
논문이 제시하는 roadmap도 꽤 명확하다.
1) 더 많은 모달리티
- ultrasound
- mammography
- longitudinal study (과거/현재 비교)
2) 더 풍부한 평가 설정
- multi-turn conversational evaluation
- EHR와 영상의 결합 추론
3) 더 넓은 툴 생태계
- MONAI 기반 전문 알고리즘 추가
- spatial grounding이 좋아질수록 더 정교한 tool-use 평가 가능
4) Open-Method의 확장성
- native 3D foundation model
- study compression encoder
- non-Slicer pipeline
블로그 포인트
이 benchmark는 단순히 “지금 누가 1등인가”보다도, 앞으로 어떤 방식의 의료영상 foundation model이 등장해도 비교 가능한 판을 만든다는 점에서 의미가 있다.
개인적인 해석 포인트
이 논문을 읽을 때는 성능표 자체보다도 아래 질문을 중심에 두는 편이 좋다.
- 의료영상 에이전트를 실제 임상처럼 평가하려면 무엇이 필요한가?
- 에이전트가 보는 것과 하는 것을 어떻게 감사 가능하게 만들 수 있는가?
- 툴을 더 주는 것이 왜 항상 성능 향상으로 이어지지 않는가?
이 세 질문에 대해 이 논문은 꽤 선명한 답을 준다.
- 전체 study를 직접 탐색하게 해야 한다.
- bounded action space와 visible trace가 필요하다.
- 현재 병목은 reasoning이 아니라 precise spatial grounding일 수 있다.
마무리 문단
MEDOPENCLAW는 의료영상 VLM을 정적인 2D 문제풀이에서 꺼내어, 실제 판독처럼 전체 3D 검사를 탐색하고 근거를 남기는 agent로 옮기려는 시도다. MEDFLOW-BENCH는 그 과정을 평가하기 위한 benchmark이고, 여기서 드러난 가장 중요한 메시지는 viewer-only full-study reasoning은 이미 현실적인 수준에 다가가고 있지만, 전문 tool을 안정적으로 다루는 능력은 아직 spatial grounding의 벽에 막혀 있다는 점이다. 의료 AI가 임상 워크플로로 더 깊게 들어가려면, 앞으로는 “더 많이 아는 모델” 못지않게 “더 정확하게 보고, 더 안전하게 조작하는 모델”이 중요해질 것이다.
짧은 요약
MEDOPENCLAW는 의료영상 AI를 실제 뷰어(3D Slicer) 위에서 전체 study 단위로 탐색하게 만드는 감사 가능한 runtime이고, MEDFLOW-BENCH는 그 과정을 평가하는 benchmark다. 흥미로운 점은 viewer-only setting에서는 frontier 모델이 꽤 괜찮지만, segmentation toolpack을 추가하면 오히려 성능이 떨어질 수 있다는 것. 핵심 병목은 reasoning 그 자체보다 precise spatial grounding에 가깝다.
참고 정보
- 논문명: MEDOPENCLAW: Auditable Medical Imaging Agents Reasoning over Uncurated Full Studies
- 형태: arXiv preprint
- 핵심 구성요소: MEDOPENCLAW, MEDFLOW-BENCH, MEDCOPILOT
- 문서에 포함된 Figure: 제공된 PDF의 page 3, page 4 figure를 정리용으로 포함
'AI 생성 글 정리 > medical' 카테고리의 다른 글
| AI agent in healthcare 논문 정리 (0) | 2026.05.18 |
|---|---|
| Accurate discharge summary generation using fine tuned large language models with self evaluation 논문 핵심 정리 (0) | 2026.04.07 |
| Automated generation of discharge summaries 정리 (0) | 2026.04.06 |
| EHRNoteQA 논문 핵심 정리 (0) | 2026.04.06 |
| MIMIC-IV 임상노트 요약용 LLM 벤치마크 논문 정리 (0) | 2026.04.06 |



