딥러닝 기반 생물학 인과발견, 정말 준비됐을까?
논문 정보
- 제목: Are we ready for causal discovery in biological systems using deep learning?
- 저자: Hock Chuan Yeo, Kumar Selvarajoo
- 저널: Briefings in Bioinformatics (2026)
- 성격: Opinion article / 관점 논문
- DOI: 10.1093/bib/bbag127
한눈에 보는 결론
이 논문의 결론은 단순하다.
딥러닝 덕분에 생물학 인과발견의 돌파구는 보이기 시작했지만, 아직 “실전 준비 완료”라고 말하기에는 이르다.
특히 저자들은 최근의 딥러닝 기반 방법들이
1) 피드백 루프가 있는 생물학 시스템을 다루기 시작했고,
2) 더 큰 규모의 변수 공간으로 확장되고 있다는 점을 높게 평가한다.
하지만 동시에, 생물학적으로 의미 있는 인과 네트워크를 실제로 구축하려면 아직 해결해야 할 기술적 병목이 많다고 본다.
이 논문이 중요한 이유
이 글은 새로운 알고리즘 하나를 소개하는 논문이라기보다,
“지금 인과발견 연구가 어디까지 왔고, 생물학에서는 왜 아직 어려운가?”를 정리해 주는 로드맵 성격의 글이다.
특히 생물학에서는 다음 문제가 동시에 존재한다.
- 변수 수가 매우 많다
- 샘플 수는 상대적으로 적다
- 관측 데이터만으로는 인과를 구분하기 어렵다
- 실제 생물학 네트워크는 피드백 루프를 많이 가진다
- 다중오믹스, 시간축, 잡음, 이질성까지 함께 고려해야 한다
즉, 일반적인 인과발견 문제보다 훨씬 더 어렵고 현실적인 조건을 가진다.
이 논문은 바로 이 지점에서, 기존 방법과 최신 딥러닝 접근을 비교하며 “무엇이 바뀌고 있고, 무엇이 아직 부족한지”를 짚는다.
핵심 주장
저자들의 메시지는 크게 두 줄기로 정리할 수 있다.
1) 기존의 고전적 인과발견 방법은 생물학에 그대로 쓰기 어렵다
전통적인 Bayesian network / DAG 기반 접근은 전체 네트워크 구조를 탐색해야 하므로 계산량이 매우 크고, 대부분 전역적 비순환성(global acyclicity) 을 가정한다.
문제는 생물학 시스템에는 피드백 루프가 흔하다는 점이다.
즉, 현실의 세포 시스템은 “사이클 없는 DAG”로 보기 어려운 경우가 많다.
2) 딥러닝 기반의 새로운 접근은 “전체 그래프 찾기”보다 “엣지 판별”에 집중한다
최근에는 전체 구조를 한 번에 맞추기보다,
변수 쌍 사이에 방향성 있는 인과 엣지가 있는지를 분류하는 방식이 주목받는다.
이 접근의 장점은 분명하다.
- 전체 그래프 탐색보다 계산이 단순하다
- supervision(부분적인 정답 지식)을 활용할 수 있다
- 고차원·저샘플 환경에서 더 실용적일 수 있다
- 생물학처럼 부분 지식이 이미 있는 분야와 잘 맞는다
즉, 논문은 인과발견의 무게중심이
“베이지안 전체 구조 탐색”에서 “신경망 기반 엣지 수준 추론”으로 이동 중이라고 본다.
방법론 흐름: 두 진영으로 보면 이해가 쉽다
1. 고전적 Bayesian / DAG 계열
이 계열의 장점은 인과 구조를 비교적 정교하게 모델링하려 한다는 점이다.
하지만 단점도 크다.
- 전체 네트워크 탐색 비용이 매우 크다
- 변수 수가 커질수록 탐색 공간이 폭증한다
- score-equivalent 구조 문제도 있다
- 무엇보다 대부분 피드백 루프를 허용하지 않는다
NO TEARS 이후처럼 acyclicity 제약을 연속 최적화 문제로 바꾼 발전은 분명 의미가 있다.
하지만 저자들은 이런 계열이 여전히 자기조절적인 biological systems에는 구조적으로 한계가 있다고 본다.
2. 딥러닝 기반 분류형 인과발견
이 계열은 질문을 더 단순하게 바꾼다.
“전체 그래프가 무엇인가?”
보다
“A가 B의 원인인가?”
를 더 잘 맞히자.
논문에서 대표적으로 언급하는 방법은 D2CL과 CSIvA다.
D2CL: 생물학적 데이터 조건에 맞춘 실용적 접근
무엇이 강점인가
D2CL(Deep Discriminative Causal Learning)은
고차원(low sample, high dimension) + 부분적 인과 지식 존재라는 생물학의 전형적인 조건에 맞춰 설계된 방법으로 소개된다.
저자들이 강조하는 포인트는 다음과 같다.
- 인공 시스템에서 최대 50,000 변수까지 확장성 보고
- 비교적 적은 수의 샘플로도 동작
- 기존 방법보다 direct effect, ancestral effect 추론에서 더 좋은 성능 사례 제시
- 생물학처럼 이미 일부 인과관계가 알려진 상황에서 supervision을 활용할 수 있음
왜 의미가 큰가
생명과학 데이터는 흔히 p >> n 구조다.
즉, 변수는 수천~수만 개인데 샘플은 매우 적다.
이때 전체 생성모형을 정교하게 맞추려는 접근보다,
알려진 일부 관계를 발판 삼아 새로운 관계를 예측하는 방식이 더 현실적일 수 있다.
하지만 남는 한계
논문은 D2CL의 강점을 인정하면서도, 생물학적으로 다음 가정을 경계한다.
- 각 causal factor가 어느 정도 독립적으로 작동한다
- 한 요인을 바꾸면 타깃에서 관측 가능한 변화가 나온다
- 서로 다른 causal factor들 사이에 학습 가능한 공통성이 있다
이 가정들은 실제 세포 시스템에서 항상 성립하지 않을 수 있다.
즉, 성능은 좋지만 생물학적 정합성은 더 검증이 필요하다는 게 이 논문의 균형 잡힌 평가다.
CSIvA: attention / transformer 기반의 메타러닝형 접근
아이디어
CSIvA(Causal Structure Induction via Attention)는
다양한 synthetic system에서 학습한 뒤, 보지 못한 시스템이나 자연계 데이터로 일반화하려는 접근이다.
여기서 핵심은 attention mechanism이다.
저자들이 보는 장점은 다음과 같다.
- 샘플 간 variation
- factor 간 variation
- 나아가 시간축이나 modality 간 variation까지
이런 구조적 변화를 attention으로 포착할 가능성이 있다는 점이다.
왜 흥미로운가
이 논문은 CSIvA를 단순히 “좋은 성능의 모델”로만 보지 않는다.
오히려 향후 multi-omics, time-series, heterogeneous biological data를 연결할 수 있는 단서로 본다.
결정적 한계
다만 현실적인 제약도 매우 크다.
- intervention data 의존
- 충분히 풍부한 intervention이 있어야 identifiability 확보 가능
- synthetic training distribution을 잘 설계해야 함
- 더 크고 더 촘촘한 그래프에서는 일반화가 어려움
- 데이터 요구량이 상당히 큼
즉, CSIvA는 개념적으로는 매우 매력적이지만, 실제 생물학에 바로 투입하기에는 데이터 비용이 크다는 것이 논문의 시각이다.
이 논문의 진짜 포인트: “누가 더 좋냐”보다 “어떤 문제에 맞느냐”
이 논문을 읽을 때 중요한 점은
단순히 “D2CL이 좋다 / Bayesian은 나쁘다”로 읽으면 안 된다는 것이다.
저자들의 메시지는 오히려 다음에 가깝다.
- Bayesian 계열은 샘플이 충분하고 생성모형까지 보고 싶을 때 강하다
- 딥러닝 분류형 계열은 고차원·저샘플·부분 지식 활용 환경에서 강하다
- 생물학은 후자의 조건에 더 가까운 경우가 많다
즉, 방법론 우열의 문제가 아니라
문제 설정과 데이터 조건에 맞는 도구를 써야 한다는 이야기다.
Figure 1 설명
Figure 1 전체

이 그림은 논문의 메시지를 거의 그대로 압축한 핵심 그림이다.
크게 (a) 앞으로 해결해야 할 병목과 (b) 인과 추론에 활용할 수 있는 variation의 종류를 보여준다.
Figure 1a: 지금까지의 진전과 앞으로의 병목
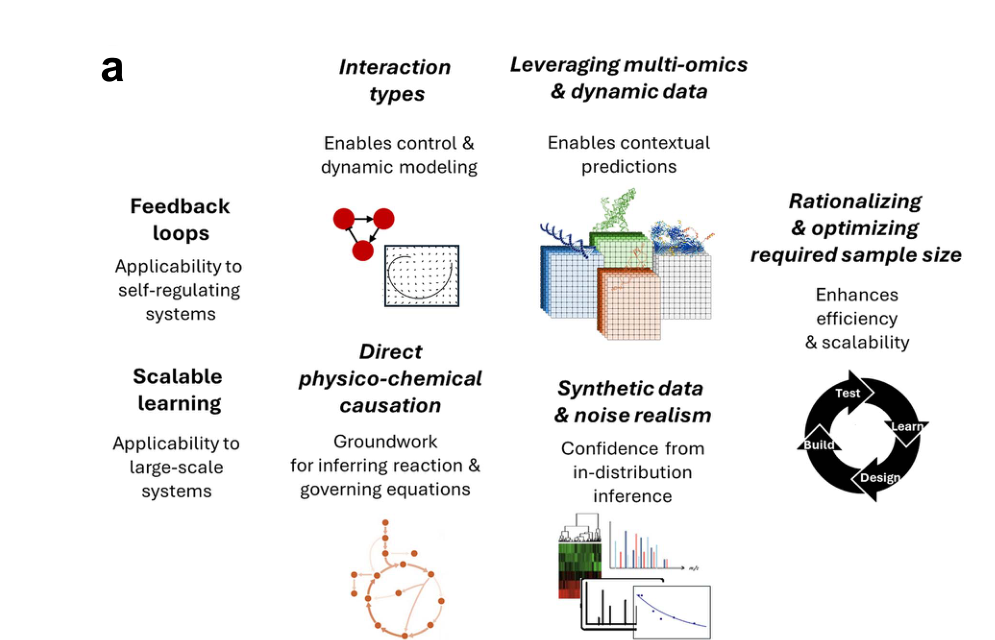
Figure 1a는 일종의 연구 로드맵이다.
이미 진전이 있었던 축
- Feedback loops
생물학 시스템은 자기조절적이기 때문에, 피드백 루프를 다룰 수 있어야 한다. - Scalable learning
실제 biological system은 변수 수가 방대하므로 확장성이 필요하다.
즉, 최근 딥러닝 기반 접근은 최소한
“사이클이 있는 시스템을 조금 더 현실적으로 다루려는 방향”과
“대규모 시스템으로 가려는 방향”에서 진전이 있었다는 뜻이다.
앞으로 넘어야 할 다섯 가지 과제
- Interaction types 구분
활성화인지 억제인지까지 알아야 control / dynamics 분석이 가능하다. - Direct physico-chemical causation
통계적 연관이 아니라, 더 직접적인 물리·화학적 메커니즘까지 가야 한다. - Leveraging multi-omics & dynamic data
transcript-protein-metabolite-time 정보를 함께 써야 한다. - Synthetic data & noise realism
학습용 synthetic data가 실제 생물학의 noise와 법칙을 더 잘 닮아야 한다. - Rationalizing & optimizing required sample size
지금 방법들은 여전히 많은 샘플을 요구하며, 대부분의 생물학 연구는 이를 감당하기 어렵다.
블로그용 한 줄 해석
“계산 가능성은 열렸지만, 생물학적 의미를 확보하는 문제는 아직 남아 있다.”
Figure 1b: 인과를 알려주는 variation의 네 가지 유형

Figure 1b는 인과발견이 활용할 수 있는 variation을 네 가지로 정리한다.
Type I — 단일 modality 내 변수 간 variation
예: transcript들끼리의 관계
가장 전통적인 형태다.
하나의 데이터 층 안에서 변수 간 상호작용을 본다.
Type II — 서로 다른 modality 간 variation
예: transcript ↔ protein ↔ metabolite
생물학적으로는 이 축이 특히 중요하다.
중앙원리(Central Dogma)와 조절 방향성을 반영할 수 있기 때문이다.
Type III — 샘플 간 variation
예: 서로 다른 세포/조건/개체에서 같은 변수의 변화
모델이 개체 간 차이를 활용해 인과 힌트를 얻는 방식이다.
Type IV — 시간축 variation
예: timepoint 1, 2, 3, ... 에 따른 변화
진짜 동적 인과를 이해하려면 매우 중요하지만, 다루기가 어렵다.
이 그림의 핵심 메시지
논문에 따르면 현재 구현된 것은 주로 Type I과 Type III 쪽이다.
하지만 생물학적으로 더 깊은 이해를 위해서는
Type II(다중오믹스)와 Type IV(시간축) 까지 본격적으로 들어가야 한다.
블로그용 한 줄 해석
“생물학 인과발견의 다음 단계는 단일 테이블 학습이 아니라, 오믹스 간 연결과 시간 변화까지 포함하는 방향이다.”
저자들이 제시한 5대 기술적 허들
논문이 강조하는 핵심은 아래 다섯 가지다.
1. 활성화와 억제의 구분
현재 많은 방법은 “연결이 있다/없다”를 중심으로 본다.
하지만 생물학에서는 어떻게 연결되는지가 더 중요할 수 있다.
- 활성화인가?
- 억제인가?
- 조건 의존적인가?
이 정보가 있어야 동역학 모델링과 제어 분석까지 갈 수 있다.
2. 직접적 물리·화학적 인과의 추론
단순한 statistical causation을 넘어,
실제로 어떤 반응과 메커니즘이 있는지를 추론해야
궁극적으로는 governing equations와 digital twin 수준의 모델로 발전할 수 있다.
3. 멀티오믹스와 시간정보의 통합
세포는 transcript만으로 설명되지 않는다.
protein, metabolite, chromatin state, time dynamics를 함께 봐야 한다.
즉, 미래의 causal discovery는 single modality inference를 넘어야 한다.
4. 더 현실적인 synthetic data와 noise model
많은 딥러닝 방법은 synthetic data로 학습되고 평가된다.
그런데 synthetic world가 실제 biology의 법칙과 noise를 충분히 반영하지 못하면,
현실 문제에서 성능이 무너질 수 있다.
5. 샘플 수 최적화
현재 유의미한 인과 예측에 필요한 샘플 수는 여전히 높다.
하지만 대부분의 생물학 연구는 그렇게 많은 intervention 데이터를 제공하지 못한다.
이 문제를 해결하지 못하면, 임상이나 실제 가설 생성으로 이어지기 어렵다.
이 논문을 읽고 얻어야 할 핵심 인사이트
인사이트 1
생물학에서 인과발견의 핵심 장애물은 단순한 계산량이 아니라, 생물학적 현실성과 데이터 조건이다.
인사이트 2
딥러닝은 인과발견을 더 확장 가능하게 만들고 있지만, 아직 충분한 이론적 보증과 현실 검증은 부족하다.
인사이트 3
앞으로 중요한 것은 “더 큰 모델”이 아니라 “더 생물학적인 모델”이다.
- 피드백 허용
- 다중오믹스 통합
- 시간축 반영
- 메커니즘 수준 해석
- 현실적 noise 반영
인사이트 4
이 분야는 결국 systems biology와 machine learning의 결합이 필요하다.
논문 마지막 메시지도 여기에 가깝다.
생물학적 구조를 모르는 채 데이터만 늘리는 방식으로는 한계가 있고,
반대로 계산적 확장성을 무시한 순수 기계론적 접근도 충분하지 않다.
요약
이 논문은 딥러닝 기반 인과발견이 생물학에서 어디까지 왔는지를 정리한 관점 논문이다.
저자들은 최근 방법들이 기존 DAG 중심 접근의 한계를 넘어서, 피드백 루프와 대규모 시스템을 조금씩 다루기 시작했다고 본다.
특히 D2CL이나 CSIvA 같은 신경망 기반 접근은 고차원 생물학 데이터에서 새로운 가능성을 보여준다.
하지만 아직은 활성/억제 구분, 직접적 메커니즘 추론, 멀티오믹스 통합, 현실적인 synthetic data, 샘플 수 최적화 같은 핵심 병목이 남아 있다.
따라서 이 논문의 결론은 “이제 준비가 끝났다”가 아니라, “유망한 전환점에 도달했지만 아직 넘어야 할 생물학적·기술적 장벽이 많다”는 것이다.
마지막 한 줄 정리
이 논문은 “딥러닝이 인과발견을 가능하게 만들고 있다”는 희망과, “생물학적으로 쓸 만한 수준까지는 아직 멀었다”는 현실을 동시에 보여주는 로드맵이다.
'AI 생성 글 정리 > bio' 카테고리의 다른 글
| RFdiffusion 논문 핵심 정리 (0) | 2026.04.01 |
|---|---|
| Chai-1 논문 정리: 공개형 biomolecular structure model이 어디까지 왔는가 (0) | 2026.04.01 |
| Protein interactions in human pathogens revealed through deep learning 정리 (1) | 2026.04.01 |
| A generative AI-discovered TNIK inhibitor for idiopathic pulmonary fibrosis: a randomized phase 2a trial 정리 (0) | 2026.04.01 |
| CrisprPr 논문 정리 (0) | 2026.04.01 |



