장문 PDF/Markdown을 계층형 트리(PageIndex tree) 로 변환하고, 그 구조 위에서 LLM/에이전트가 reasoning-based retrieval 을 수행하도록 설계된 오픈소스 프로젝트다. 공개 저장소의 실제 범위는 “완성형 문서 QA 서비스” 전체보다 문서 구조화 엔진 + agent-friendly retrieval primitive 에 더 가깝다.
분석 스냅샷: 2026-04-08 (Asia/Seoul 기준)

Quick Links
- GitHub 저장소: https://github.com/VectifyAI/PageIndex
- 공식 문서: https://docs.pageindex.ai
- 개발자 문서 / MCP / API: https://pageindex.ai/developer
- 데모 성격의 Chat Platform: https://chat.pageindex.ai
- Framework 소개 블로그: https://pageindex.ai/blog/pageindex-intro
- Vectorless RAG Cookbook: https://docs.pageindex.ai/cookbook/vectorless-rag-pageindex
- Tree Search 문서 (LLM): https://docs.pageindex.ai/tutorials/tree-search/llm
- Tree Search 문서 (Hybrid): https://docs.pageindex.ai/tutorials/tree-search/hybrid
- 다문서 검색 전략 문서: https://docs.pageindex.ai/tutorials/doc-search
- 에이전트 예제: https://github.com/VectifyAI/PageIndex/blob/main/examples/agentic_vectorless_rag_demo.py
- 관련 벤치마크 리포지토리: https://github.com/VectifyAI/Mafin2.5-FinanceBench
- 관련 논문(벤치마크): FinanceBench — https://arxiv.org/abs/2311.11944
참고: README 말미의 인용 형식은 블로그 citation 기준이며, 공개 저장소 README에서 별도의 독립 학술 논문 링크는 명시하지 않는다.
Key Features
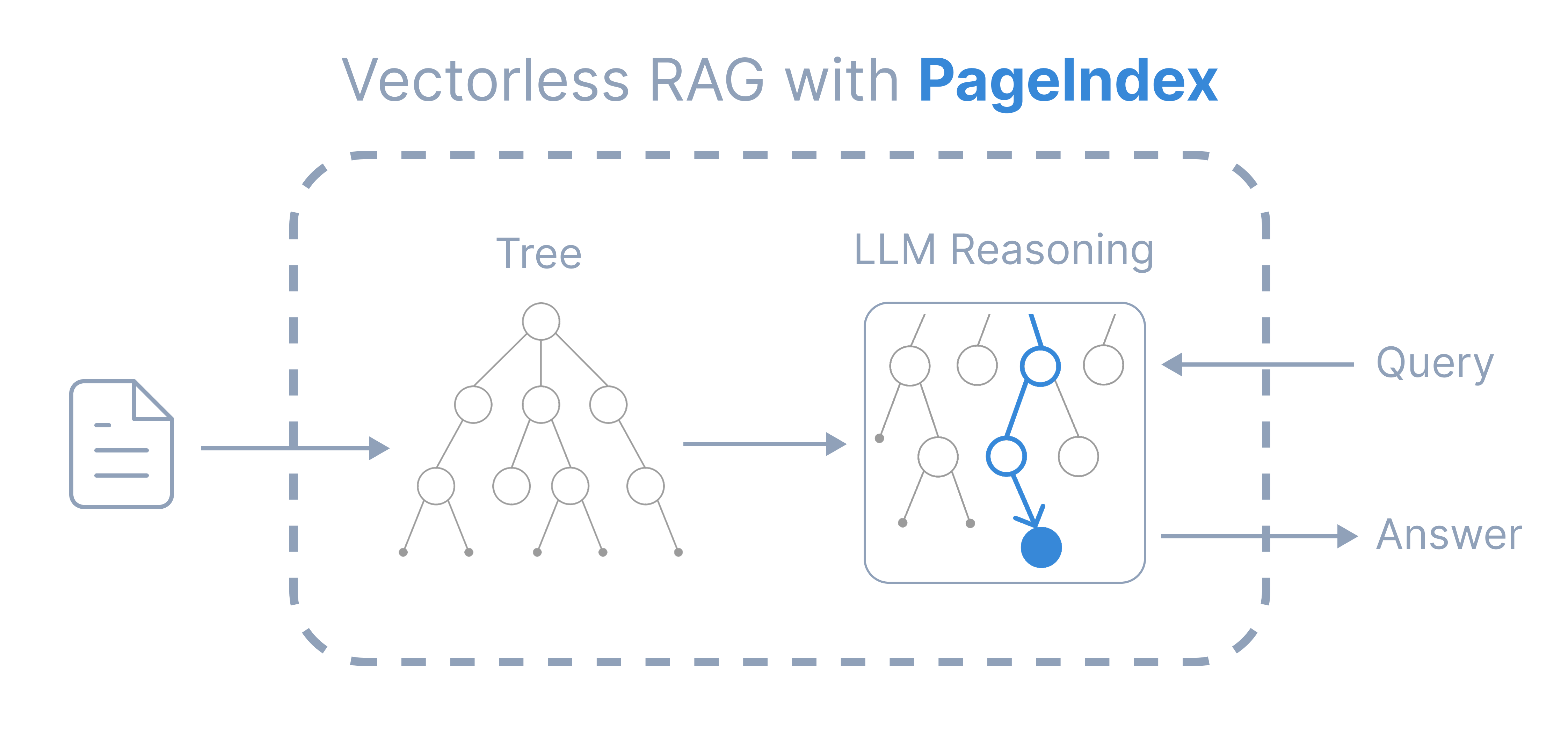
- Vectorless retrieval: 벡터 DB 없이 문서 구조와 LLM 추론으로 검색한다.
- No chunking: 임의 chunk 대신 문서의 자연스러운 section / subsection 단위로 구조를 만든다.
- TOC-aware parsing: 문서 앞부분의 목차(TOC)를 감지하고, 목차가 있으면 이를 기반으로 section tree를 만든다.
- No-TOC fallback generation: 목차가 없거나 불완전하면 LLM이 페이지 묶음을 읽고 계층형 TOC를 직접 생성한다.
- Recursive large-node splitting: 페이지 수와 토큰 수가 큰 노드는 재귀적으로 다시 쪼개 더 세밀한 하위 트리로 만든다.
- Explainable retrieval: page/section 기준으로 추적 가능한 검색 경로를 제공해, 왜 그 부분을 봤는지 설명하기 쉽다.
- PDF + Markdown 지원: PDF는 페이지 기반, Markdown은 heading/line 기반으로 tree를 생성한다.
- Optional enrichment:
node_id,summary,text,doc_description을 선택적으로 붙일 수 있다. - Agent-ready tool surface:
get_document,get_document_structure,get_page_content의 3단계 도구 인터페이스가 에이전트 설계에 잘 맞는다. - Workspace persistence:
PageIndexClient가_meta.json+ 문서별 JSON 저장소를 사용해 캐시/재사용 경로를 제공한다. - LiteLLM 기반 멀티-프로바이더 가능성: 코드상으로는 LiteLLM을 사용해 여러 모델 공급자를 붙일 수 있게 설계되어 있다.
- 공식 생태계 확장성: 공개 OSS 저장소 바깥의 공식 docs에서는 다문서 검색, hybrid tree search, Chat/API 운영 패턴까지 제시한다.
Tech Stack
| 영역 | 내용 |
|---|---|
| 언어 | Python |
| LLM abstraction | litellm==1.82.0 |
| PDF 파싱 | pymupdf==1.26.4, PyPDF2==3.0.1 |
| 환경변수/설정 | python-dotenv==1.1.0, pyyaml==6.0.2 |
| 선택적 agent 런타임 | openai-agents (requirements에 버전 미고정, 예제에서 사용) |
| 예제 추가 의존성 | requests (에이전트 데모에서 import하지만 requirements.txt에는 없음) |
| 기본 index model | gpt-4o-2024-11-20 (pageindex/config.yaml) |
| 기본 retrieve model | gpt-5.4 (pageindex/config.yaml, 미설정 시 model fallback) |
| 라이선스 | MIT |
구현 레벨에서 보이는 기술 포인트
litellm.drop_params = True로 provider 간 파라미터 차이에 조금 더 유연하게 대응한다.OPENAI_API_KEY가 없고CHATGPT_API_KEY만 있으면 alias로 받아준다.ConfigLoader가 YAML 기본값과 사용자 override를 merge하고, 알 수 없는 키는 예외 처리 한다.PageIndexClient는 retrieval model 명을 Agents SDK 친화적으로 normalize하며, 비-openai provider path는litellm/...경유로 맞춘다.
Collected Figures
공개 저장소 스냅샷과 공식 문서에서 핵심 구조/아키텍처 figure 3개를 확보했다. OSS 공개 저장소 자체에는 제품 UI screenshot/GIF는 두드러지지 않았고, 수집 가능한 핵심 시각 자료는 주로 README/공식 docs 연결 이미지였다.
| 로컬 경로 | 원본 | 의미 |
|---|---|---|
figures/01_pageindex_banner.png |
README 배너 | 프로젝트 포지셔닝 요약 |
figures/02_vectorless_rag_architecture.png |
Framework / Cookbook 이미지 | PageIndex의 핵심 vectorless RAG 개념도 |
figures/03_hybrid_tree_search_pipeline.png |
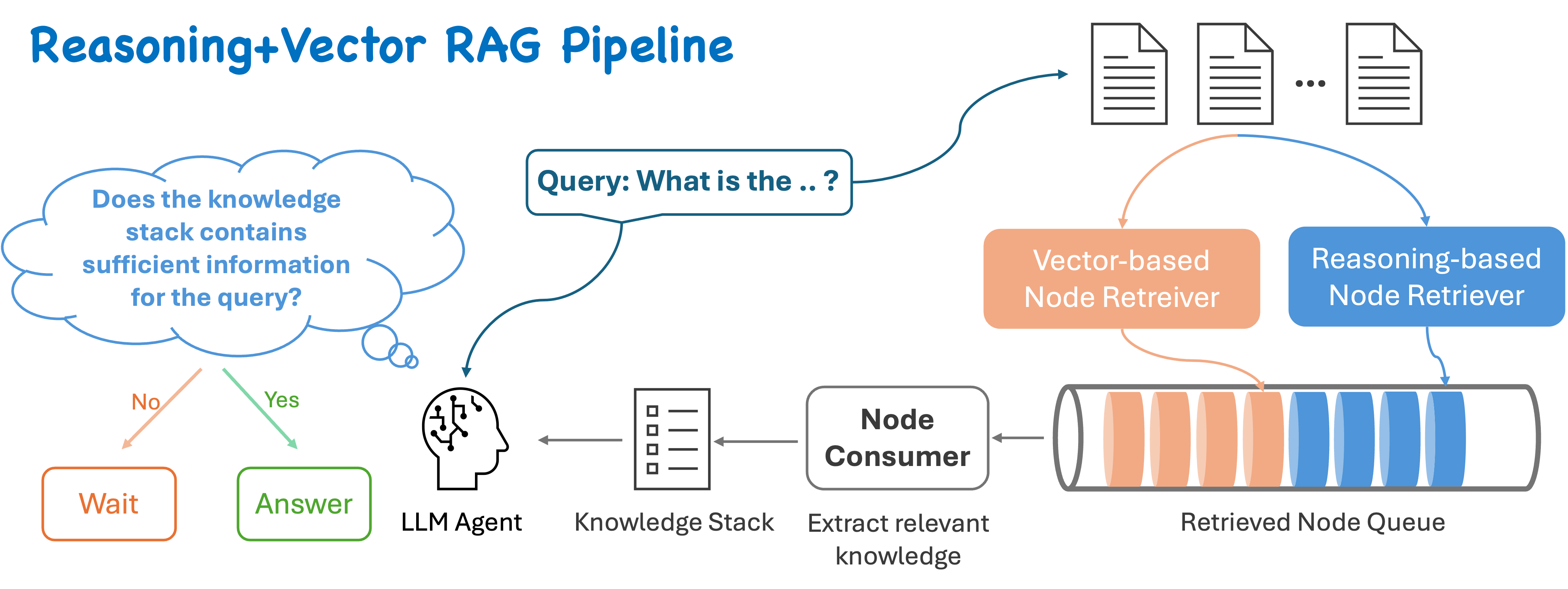
Hybrid Tree Search 문서 | 공식 hosted retrieval 방향성(LLM + value prediction 병렬 탐색) |
1) Vectorless RAG 개념도

2) Hybrid Tree Search 파이프라인

Architecture
저장소 구조
PageIndex/
├── run_pageindex.py # CLI 진입점
├── requirements.txt
├── pageindex/
│ ├── __init__.py # public API export
│ ├── client.py # PageIndexClient, workspace persistence
│ ├── config.yaml # 기본 모델/토큰/노드 옵션
│ ├── page_index.py # PDF -> PageIndex tree 생성 핵심 로직
│ ├── page_index_md.py # Markdown -> tree 생성
│ ├── retrieve.py # metadata/tree/page access helper
│ └── utils.py # LLM 호출, PDF 추출, 로깅, post-processing
├── examples/
│ ├── agentic_vectorless_rag_demo.py
│ ├── documents/
│ ├── tutorials/
│ └── workspace/
└── cookbook/
├── pageindex_RAG_simple.ipynb
├── vision_RAG_pageindex.ipynb
├── agentic_retrieval.ipynb
└── pageIndex_chat_quickstart.ipynb핵심 데이터 플로우
PDF / Markdown 입력
↓
텍스트/헤더 추출
↓
TOC 존재 여부 판단
├─ TOC 있음
│ ├─ TOC 텍스트 추출
│ ├─ LLM으로 TOC JSON 변환
│ └─ 논리 page 번호와 실제 physical page offset 정렬
└─ TOC 없음
└─ 페이지 묶음에 physical_index 태그를 붙여 LLM이 TOC를 직접 생성
↓
flat section list 생성
↓
start_index / end_index 계산 + flat list → tree 변환
↓
큰 노드 재귀 분할 (page/token threshold 기준)
↓
선택적으로 node_id / text / summary / doc_description 부여
↓
get_document / get_document_structure / get_page_content
↓
Agent 또는 앱 레이어가 tree 위에서 reasoning-based retrieval 수행코드 기준으로 본 구조 해설
1) pageindex/page_index.py: PDF → tree 생성 엔진
이 파일이 핵심이다. 전체 흐름은 대략 다음과 같다.
- PDF에서 페이지 텍스트와 토큰 수를 추출한다.
- 앞부분 몇 페이지를 검사해 TOC가 있는지 판단한다 (
toc_check_page_num기본 20). - TOC가 있으면:
- TOC 텍스트를 뽑고,
- page number가 명시되어 있는지 확인하고,
- LLM으로 TOC를 JSON 형태로 바꾸고,
- TOC에 적힌 page와 실제 PDF physical page 사이의 offset을 추정해 맞춘다.
- TOC가 없으면:
- 페이지 텍스트에
<physical_index_X>태그를 넣어, - LLM이 직접 계층형 TOC를 생성하게 한다.
- 페이지 텍스트에
- 이후
post_processing()으로start_index/end_index를 계산하고 flat list를 tree로 바꾼다. - 마지막으로 너무 큰 노드는 재귀적으로 다시 처리해서 더 세밀한 하위 트리를 만든다.
2) pageindex/page_index_md.py: Markdown → tree 생성
Markdown 모드는 heading(#, ##, ### ...)을 트리 구조의 기준으로 사용한다.
- fenced code block는 heading으로 오인하지 않도록 무시한다.
- 각 heading 구간의 텍스트를 잘라 node별
text로 붙인다. - 선택적으로 token 수가 작은 child들을 parent에 합치는 tree thinning 이 있다.
- Markdown에서는 retrieval 시 “page” 대신 line number 가 사실상의 locator 역할을 한다.
3) pageindex/retrieve.py: retrieval primitive
중요한 해석 포인트는 이 파일이 완성형 retriever 라기보다 도구형 accessor 라는 점이다.
get_document()→ 문서 메타데이터get_document_structure()→text제거된 tree JSONget_page_content()→'5-7','3,8','12'같은 범위 문법으로 실제 본문 조회
즉, “어떤 노드를 볼지”에 대한 reasoning은 보통 에이전트 프롬프트/정책 쪽이 담당하고, 이 파일은 그 결과를 실행하는 tool layer 역할을 한다.
4) pageindex/client.py: 앱 통합 포인트
PageIndexClient 는 실제로 이 프로젝트를 앱에 붙일 때 가장 중요한 진입점이다.
index()로 PDF/Markdown을 색인한다.workspace를 쓰면_meta.json+ 문서별 JSON 파일로 캐시한다.- PDF는 workspace에 저장할 때 node
text를 제거하고, page-level text를 별도로 저장해 용량을 줄인다. - 필요한 시점에 lazy-load 하도록 설계돼 있다.
이 패턴은 production에서 꽤 유용하다. 즉, tree는 가볍게 유지하고, 상세 본문은 필요할 때만 읽는 구조 다.
5) examples/agentic_vectorless_rag_demo.py: 에이전트 사용 패턴의 정수
에이전트 데모는 이 프로젝트의 설계 의도를 가장 잘 보여준다.
- 먼저
get_document()로 문서 상태/메타를 확인한다. - 그 다음
get_document_structure()로 어떤 섹션이 관련 있을지 좁힌다. - 마지막으로
get_page_content()로 딱 필요한 페이지 범위만 가져온다.
이 3단계는 “전체 문서를 한 번에 벡터 검색” 하는 방식보다, 문서 구조를 state space로 보고 탐색 하는 접근에 가깝다.
OSS 저장소 범위 vs 공식 hosted/docs 범위
이 구분이 중요하다.
- OSS 저장소가 잘하는 것
- single long document를 tree로 구조화
- agent/tool-friendly accessor 제공
- 로컬 실험, custom app embedding, self-hosted indexing
- 공식 docs에서 추가로 안내하는 것
- multi-document search 전략(메타데이터/의미/설명 기반 라우팅)
- LLM tree search, hybrid tree search
- hosted Chat/API/MCP 운영 패턴
즉, 공개 저장소는 “PageIndex의 핵심 엔진” 이고, 공식 서비스/문서는 그 위의 검색 정책과 운영 계층 을 더 보여준다.
Usage & Setup
가장 빠른 로컬 시작
git clone https://github.com/VectifyAI/PageIndex.git
cd PageIndex
pip3 install --upgrade -r requirements.txt
# 에이전트 예제를 돌릴 경우 권장
pip3 install openai-agents requests
# OPENAI_API_KEY 또는 CHATGPT_API_KEY 사용 가능
cat > .env <<'EOF'
OPENAI_API_KEY=your_openai_key_here
EOFPDF를 tree로 변환
python3 run_pageindex.py --pdf_path /path/to/your/document.pdf결과는 기본적으로 아래에 저장된다.
./results/<document_name>_structure.jsonMarkdown를 tree로 변환
python3 run_pageindex.py --md_path /path/to/your/document.md자주 볼 옵션
| 옵션 | 의미 | 관찰된 기본값 |
|---|---|---|
--model |
색인용 LLM | gpt-4o-2024-11-20 |
--toc-check-pages |
TOC 탐지 페이지 수 | 20 |
--max-pages-per-node |
노드 최대 페이지 수 | 10 |
--max-tokens-per-node |
노드 최대 토큰 수 | 20000 |
--if-add-node-id |
node_id 추가 | yes |
--if-add-node-summary |
요약 추가 | yes |
--if-add-doc-description |
문서 설명 추가 | 코드 기본값은 no |
--if-add-node-text |
원문 text 추가 | no |
주의: README 설명부에는
--if-add-doc-description의 기본값이yes처럼 적혀 있지만, 실제pageindex/config.yaml기본값은no다. CLI 실동작은 config 쪽을 따르는 편으로 보는 것이 안전하다.
프로그램에서 직접 붙일 때
import json
from pageindex import PageIndexClient
client = PageIndexClient(workspace="./workspace")
doc_id = client.index("./my_document.pdf")
meta = json.loads(client.get_document(doc_id))
tree = json.loads(client.get_document_structure(doc_id))
pages = json.loads(client.get_page_content(doc_id, "5-7"))에이전트 데모 실행
python3 examples/agentic_vectorless_rag_demo.py이 예제는 OpenAI Agents SDK 기반이며, 문서 검색을 아래 순서로 수행한다.
- 문서 메타 확인
- 구조 tree 확인
- 좁은 page range만 본문 fetch
실제 구현 시 추천 사용 시나리오
- 단일 장문 PDF QA: 이 저장소만으로도 충분히 실험 가능
- 여러 문서에서 먼저 후보 문서 선택: 메타데이터/description/별도 semantic router를 앞단에 추가
- 에이전트형 문서 분석: 이 repo의 3개 tool 인터페이스를 그대로 agent tool로 노출
Wiki / Discussions / Community Signals
Wiki
- 현재 공개 Wiki URL은 실질적으로 저장소 루트로 redirect되어, 공개 위키 문서는 없는 상태로 보인다.
Discussions에서 읽히는 시그널
저장소 Discussions는 꽤 활발하며, 공개적으로 확인되는 카테고리는 Announcements, General, Ideas, Polls, Q&A, Show and tell 이다. 내용상 중요한 시그널은 아래와 같다.
- #171 — Metadata / Storage / Tree Retrieval 질문
- 사용자 메타데이터 저장과 필터링(SQL/NoSQL, 권한 등)은 외부에서 관리하는 쪽으로 이해하는 것이 맞다.
- 공개 OSS는 scanned PDF에서 실패할 수 있으며, hosted/API 쪽은 더 강한 OCR/layout-aware path가 있을 가능성이 크다.
- tree는 JSON-like hierarchy, raw 문서는 외부 저장소에 두는 운영 모델을 상정하면 자연스럽다.
- #111 — OpenAI-compatible API key 질문
- 커뮤니티 답변 기준으로는 OpenAI-compatible provider도 사용할 수 있다는 시그널이 있다.
- 다만 이는 Discussion/PR 기반의 커뮤니티 정보라서, 공식 제품 보장 범위와 동일시하면 안 된다.
- #56 — 성능 한계 질문
- 공개 Discussion에서는 10K+ 문서 규모에 대한 정식 공개 benchmark를 확인하기 어렵다.
- 즉, “이론상 hierarchical search가 유리하다” 와 “공개 수치로 입증되었다” 는 구분해서 받아들이는 편이 맞다.
- #22, #159 — Show and tell
- 커뮤니티가 FastAPI 서버, Web UI, 완성형 QA 시스템 등 상위 레이어를 붙여 확장하고 있다.
- 이는 곧 PageIndex가 핵심 engine 역할 에 적합하고, 상위 API/UI는 외부에서 붙이는 패턴이 자연스럽다는 뜻이다.
프로젝트 성숙도 관점 메모
- MIT 라이선스라서 실험/통합은 유연한 편이다.
- 공개 repo 기준 GitHub release가 없다. 재현성이 중요하면 tag보다 commit SHA pinning 이 낫다.
- README, 코드, docs 간에 기능 범위가 완전히 1:1 대응되지는 않는다. 구현 전에는 OSS 범위와 hosted 기능 범위 를 분리해서 보는 것이 좋다.
Limitations & Practical Notes
- Scanned / layout-heavy PDF 약점
- 공개 OSS는 born-digital PDF 쪽이 더 적합하다.
- 복잡한 레이아웃이나 스캔 문서는 OCR/layout-aware 전처리가 필요할 수 있다.
- 다문서 검색은 자동으로 해결되지 않음
- 공식 docs도 single-document reasoning을 기본으로 설명한다.
- 여러 문서에 대해선 메타데이터/설명/semantic router를 앞단에 둬야 한다.
retrieve.py는 완성형 검색 정책이 아님- 실제 reasoning search policy는 agent prompt, 별도 tree-search 로직, 혹은 hosted retrieval 계층이 담당한다.
- 예제 의존성 누락
examples/agentic_vectorless_rag_demo.py는requests를 import하지만requirements.txt에 없다.- 따라서 데모를 그대로 돌리려면
pip install requests openai-agents를 추가하는 편이 안전하다.
- CLI와 Client의 기본 동작 차이
PageIndexClient.index()는 PDF/Markdown 모두에 대해summary/text/id/doc_description를 적극적으로 켜는 편이다.- 반면 CLI는
config.yaml기본값에 더 가깝게 동작한다.
- Markdown mode의 전제
- heading 품질이 좋아야 한다.
- 일반 PDF→Markdown 변환물은 계층이 깨질 수 있어, README도 이런 경우엔 단순 MD mode를 권장하지 않는다.
- 지연/비용 trade-off
- vector search처럼 단순 근사 검색이 아니라 LLM reasoning을 포함하므로, 정확도/설명력 대신 latency와 비용이 늘 수 있다.
Personal Insights
1) 의료 AI에 주는 영감
이 프로젝트가 의료 AI에 주는 가장 큰 시사점은, 문서를 “의미 벡터들의 집합”이 아니라 “전문가가 순차적으로 탐색하는 구조화된 근거 공간”으로 본다 는 점이다.
특히 아래 영역과 잘 맞는다.
- 진료 가이드라인
- 보험/급여 기준 문서
- 병원 SOP / IRB 문서 / 임상시험 프로토콜
- 의료기기 IFU, 규제 제출 문서
의료 AI는 단순 semantic match보다 근거의 위치, 섹션 맥락, 버전 차이, 예외 조항 이 중요하다. PageIndex류 접근은 이런 high-stakes 문서에 더 잘 맞는다. 예를 들어:
- 쿼리가 “금기증” 을 묻는다면
Warnings,Contraindications,Adverse Reactions같은 section을 우선 탐색하도록 프롬프트 바이어스를 줄 수 있다. - node summary를 임상 ontology(SNOMED CT, LOINC, ICD, trial schema 등)와 결합하면, 단순 chunk search보다 훨씬 audit-friendly한 retrieval 체계를 만들 수 있다.
- page/section traceability는 추후 physician-facing evidence viewer나 compliance log로 직결된다.
2) Bioinformatics에 주는 영감
Bioinformatics 문서는 의외로 PageIndex 패턴과 잘 맞는다.
- 논문 본문 + Supplementary Appendix
- assay/protocol manual
- pipeline specification 문서
- QC 기준서, variant interpretation guideline
- vendor technical note
이 분야는 질문이 자주 Methods / Parameters / Appendix / Supplementary Table 에 걸쳐 있다. 임의 chunking은 문맥을 쉽게 깨지만, PageIndex는 구조 기반으로 해당 섹션을 먼저 찾게 만들 수 있다.
기술적으로는 아래 확장이 특히 유망하다.
- 문서 메타데이터에 organism / assay / platform / reference genome / disease area를 붙인 뒤, 앞단 라우팅 후 tree search 수행
- 표/그림/캡션을 node-level asset으로 별도 연결
- Methods 섹션과 Results 섹션의 cross-link를 만들어 “결론의 근거 파이프라인” 을 재구성
즉, Bioinformatics 쪽에서는 section-aware retrieval + domain metadata router + figure/table grounding 조합이 매우 강력해질 수 있다.
3) Autonomous Agent 개발에 주는 영감
이 저장소는 에이전트 개발 관점에서 특히 좋다. 이유는 인터페이스가 이미 다음과 같은 planner-friendly decomposition 으로 되어 있기 때문이다.
get_document()→ 현재 세계 상태 확인get_document_structure()→ 탐색 가능한 상태 공간 파악get_page_content()→ 필요한 evidence만 정밀 획득
이 구조는 ReAct/Planner-Executor/Self-Refinement 계열 에이전트와 매우 잘 맞는다. 문서 QA 에이전트가 해야 할 행동이 자연스럽게 다음처럼 분해된다.
- 어떤 문서인지 파악한다.
- 어떤 branch를 열어볼지 선택한다.
- 최종 evidence만 가져와 answer를 쓴다.
- 부족하면 다른 branch를 다시 탐색한다.
여기에 value model, 휴리스틱 점수, user preference, domain rule을 붙이면 사실상 작은 탐색기(search policy) 가 된다. 공식 docs의 hybrid tree search가 바로 그 방향성을 보여준다.
내가 이 프로젝트에서 가장 크게 가져갈 아이디어는 다음 한 줄이다.
문서 검색을 vector similarity 문제가 아니라, 구조화된 상태 공간 위에서의 탐색 문제로 재정의한다.
이 관점은 의료 AI, 바이오 문헌 분석, 규제 문서 분석, autonomous research agent 전반에 모두 확장 가능하다.
References / Source Trail
저장소 핵심 파일
- README: https://github.com/VectifyAI/PageIndex/blob/main/README.md
- requirements: https://github.com/VectifyAI/PageIndex/blob/main/requirements.txt
- CLI: https://github.com/VectifyAI/PageIndex/blob/main/run_pageindex.py
- package init: https://github.com/VectifyAI/PageIndex/blob/main/pageindex/__init__.py
- config: https://github.com/VectifyAI/PageIndex/blob/main/pageindex/config.yaml
- PDF index engine: https://github.com/VectifyAI/PageIndex/blob/main/pageindex/page_index.py
- Markdown index engine: https://github.com/VectifyAI/PageIndex/blob/main/pageindex/page_index_md.py
- client wrapper: https://github.com/VectifyAI/PageIndex/blob/main/pageindex/client.py
- retrieval helpers: https://github.com/VectifyAI/PageIndex/blob/main/pageindex/retrieve.py
- utilities: https://github.com/VectifyAI/PageIndex/blob/main/pageindex/utils.py
공식 문서 / 블로그
- Docs home: https://docs.pageindex.ai
- PageIndex Framework intro: https://pageindex.ai/blog/pageindex-intro
- Doc Search tutorial: https://docs.pageindex.ai/tutorials/doc-search
- LLM Tree Search: https://docs.pageindex.ai/tutorials/tree-search/llm
- Hybrid Tree Search: https://docs.pageindex.ai/tutorials/tree-search/hybrid
- Vectorless RAG cookbook: https://docs.pageindex.ai/cookbook/vectorless-rag-pageindex
- Vision RAG cookbook: https://docs.pageindex.ai/cookbook/vision-rag-pageindex
Discussions / Community
- Discussions home: https://github.com/VectifyAI/PageIndex/discussions
- #171 Metadata / Semantics / Storage clarification: https://github.com/VectifyAI/PageIndex/discussions/171
- #111 OpenAI-compatible API key question: https://github.com/VectifyAI/PageIndex/discussions/111
- #56 Performance limit question: https://github.com/VectifyAI/PageIndex/discussions/56
- #22 API server projected Pageindex: https://github.com/VectifyAI/PageIndex/discussions/22
- #159 Web UI / complete QA system share: https://github.com/VectifyAI/PageIndex/discussions/159
Figures 원본
- Banner asset: https://github.com/user-attachments/assets/46201e72-675b-43bc-bfbd-081cc6b65a1d
- Vectorless RAG diagram: https://docs.pageindex.ai/images/cookbook/vectorless-rag.png
- Hybrid tree search pipeline: https://docs.pageindex.ai/images/general/pipeline.png
Bottom Line
PageIndex는 “vector DB를 대체하는 범용 검색엔진” 이라기보다, 장문 전문 문서를 계층형 탐색 공간으로 바꾸고, 에이전트가 그 공간 위를 reasoning으로 탐색하게 만드는 엔진 으로 이해하는 것이 가장 정확하다.
실제로 구현에 참고한다면 다음 식으로 가져가는 것이 좋다.
- 문서별 tree 생성: 이 저장소 사용
- 문서 선택(router): metadata / semantics / description 계층 별도 설계
- 정책(search policy): LLM tree search + heuristic/value model 추가
- evidence grounding:
get_page_content()결과를 page/section citation과 함께 소비
이렇게 보면 의료 AI, Bioinformatics, Autonomous Agent 모두에서 매우 생산적인 출발점이 된다.
'AI 생성 글 정리 > tech_github' 카테고리의 다른 글
| InkOS — 다중 에이전트 기반 자율 소설 집필 CLI/Studio (0) | 2026.04.09 |
|---|---|
| OpenScreen — 오픈소스 Screen Studio 대안, Electron 기반 데스크톱 데모 레코더/에디터 (0) | 2026.04.09 |
| agency-agents — 전문 역할형 AI 에이전트 명세집 + 멀티툴 변환/설치 툴킷 (0) | 2026.04.09 |
| Daytona — AI가 생성한 코드를 실행하기 위한 보안형·탄력형 샌드박스 플랫폼 (0) | 2026.04.09 |
| Hermes Agent — self-improving 멀티채널 AI agent runtime (0) | 2026.04.08 |




{kind=link}
{kind=link}