
캡션: Hindsight는 “기억하는 에이전트”보다 “시간이 지나며 학습하는 에이전트”를 목표로 설계된 메모리 인프라다.
Quick Links
- 공식 문서: https://hindsight.vectorize.io/
- API Reference: https://hindsight.vectorize.io/api-reference
- Cookbook: https://hindsight.vectorize.io/cookbook
- Hindsight Cloud / 데모 UI: https://ui.hindsight.vectorize.io/
- CLI 문서: https://hindsight.vectorize.io/sdks/cli
- 논문: https://arxiv.org/abs/2512.12818
- GitHub 저장소: https://github.com/vectorize-io/hindsight
- GitHub Discussions: https://github.com/vectorize-io/hindsight/discussions
- 최신 릴리스(v0.5.0 기준): https://github.com/vectorize-io/hindsight/releases/tag/v0.5.0
분석 기준: 이 문서는 공개 GitHub 저장소의 README, 릴리스 노트, Discussions,
hindsight-docs기반 공식 문서, 그리고 monorepo의 코드 구조를 함께 대조해 작성했다. GitHub Wiki는 별도 공개 문서가 실질적으로 노출되지 않아,
프로젝트의 사실상 문서 허브는hindsight-docs와 공식 사이트라고 보는 편이 맞다.
Project at a Glance
Hindsight는 AI agent memory를 “대화 로그를 벡터 DB에 넣고 top-k를 꺼내오는 보조 계층”으로 취급하지 않는다. 대신, retain → recall → reflect라는 세 개의 1급 연산을 중심으로, 새로운 정보의 구조화 저장, 시간·엔티티·관계 기반 검색, 그리고 메모리 위에서의 반성적 추론까지 하나의 시스템 안에서 다룬다.
이 프로젝트를 읽으며 가장 인상적인 점은 제품화 범위가 넓다는 것이다. 저장소는 단일 Python 라이브러리가 아니라 다음을 모두 포함한 monorepo다.
- Python 기반 FastAPI 메모리 서버
- Next.js 기반 Control Plane UI
- Rust 기반 CLI/TUI
- 서버 없이 동작하는 embedded/local mode
- Python/TypeScript/Rust client SDK
- LiteLLM, LangGraph, CrewAI, AutoGen, Claude Code, Codex 등 다수의 통합 패키지
- Prometheus/OpenTelemetry/Grafana 기반 관측성 자산
현재 공개 상태를 기준으로 보면, Hindsight는 “연구용 메모리 아키텍처”를 넘어 운영 가능한 agent memory platform에 가깝다. 다만 README 자체에서도 암시하듯, 단순한 단기 챗봇이나 n8n형 경량 워크플로우에는 다소 과할 수 있다. 반대로, 여러 세션에 걸쳐 사용자를 학습하고, 행동을 수정하고, 장기 과업을 이어가는 에이전트에는 구조적으로 잘 맞는다.
Current Snapshot
- 최신 공개 릴리스는 v0.5.0이다.
- 릴리스 노트 기준으로 최근 변화는 Control Plane의 Constellation view, retain 파이프라인 개선, OpenRouter / built-in llama.cpp 지원, bank template import/export,
retain의 append 모드 등이다. - 문서/코드/통합 패키지를 함께 보면, 프로젝트는 “기억 저장소”보다 에이전트 실행 환경과 밀착된 memory substrate로 진화하는 방향에 있다.
Key Features
1. retain()은 단순 적재가 아니라 사실 추출과 정규화 파이프라인이다
Hindsight의 retain 경로는 “문장을 통째로 저장”하는 접근이 아니다. README와 코드 구조를 보면, 입력은 LLM fact extraction을 거쳐 facts, temporal ranges, fact types, entities, relationships로 분해되고, 이후 canonical entity 정규화와 링크 구성을 통해 나중의 검색 경로를 만든다.
핵심은 다음과 같다.
- 단순 텍스트 저장이 아니라 memory unit 단위의 구조화 저장
- entity/temporal/semantic/causal link 생성
- world / experience / observation 등 메모리 경로로 라우팅
- metadata, timestamp, document_id 같은 운영 정보와 함께 저장 가능
- retain 후에는 관련 facts를 묶어 observation consolidation이 비동기적으로 진행됨

캡션: Retain은 ingestion이 아니라 정규화 파이프라인이다. 이 구조 덕분에 Hindsight는 이후 recall/reflect에서 시간, 개체, 인과 링크를 활용할 수 있다.
2. recall()은 TEMPR 기반 4-way 병렬 검색을 수행한다
공식 문서에서 recall은 Semantic / Keyword(BM25) / Graph / Temporal 네 가지 전략을 병렬 수행하는 TEMPR 검색으로 설명된다. 코드 구조에서도 search/retrieval.py, fusion.py, reranking.py가 별도 모듈로 나뉘어 있어 이 설계가 문서만의 설명이 아님을 확인할 수 있다.
이 설계가 중요한 이유는 질문 유형마다 최적 검색기가 다르기 때문이다.
- “Alice works at Google” → 정확한 이름/용어 매칭이 중요
- “Where does Alice work?” → 의미 기반 semantic 매칭이 중요
- “What happened last spring?” → temporal reasoning이 중요
- “Why did Alice leave?” → graph/causal link 추적이 중요
Hindsight는 이 결과들을 RRF(Reciprocal Rank Fusion) 와 cross-encoder reranking으로 다시 합쳐 최종 context set을 만든다. 즉, recall은 단순 vector similarity wrapper가 아니라 하이브리드 retrieval orchestrator에 가깝다.

캡션: 검색 전략을 병렬화한 뒤 fusion과 reranking을 수행하는 구조가 Hindsight의 recall 정확도를 떠받치는 핵심 설계다.
3. reflect()는 검색 결과를 그대로 반환하지 않고, disposition-aware agentic reasoning을 수행한다
Reflect는 Hindsight의 차별점이 가장 크게 드러나는 지점이다. 공식 문서는 reflect를 단순 retrieval-augmented response가 아니라, 도구를 가진 agentic loop로 설명한다. 이 루프는 search_mental_models, search_observations, recall, expand, done 같은 내부 도구를 사용하며, 최대 10회까지 증거를 수집한 후 답변을 생성한다.
여기서 중요한 특징은 세 가지다.
- 계층적 검색 우선순위
Mental Models → Observations → Raw Facts 순으로 증거를 찾는다. - Disposition / Directives / Mission의 개입
똑같은 사실 집합이라도 bank의 성향과 하드 규칙에 따라 해석과 응답이 달라진다. - Citation discipline
실제로 가져온 memory id만 인용할 수 있게 설계되어 있어, “그럴듯한 추론”과 “근거 있는 응답”을 분리하려는 의도가 강하다.

캡션: Reflect는 Hindsight를 단순 메모리 저장소가 아니라 ‘배운 것을 다시 해석하는 시스템’으로 만든다.
4. Per-user memory 패턴이 문서와 운영 팁 수준까지 잘 정리돼 있다
README와 cookbook, discussions를 함께 보면 Hindsight는 개인화된 챗봇 / 사용자별 메모리 격리를 대표적인 진입 사례로 강하게 밀고 있다. 흥미로운 점은 “사용자별 세션 격리”와 “사용자 간 학습”을 함께 놓고 설명한다는 것이다. 즉, 개별 사용자의 개인정보/선호는 분리하되, 공통적으로 학습된 mental model이나 agent mission을 통해 전체 성능을 높이는 방향이다.
실무적으로 중요한 운영 팁도 Discussions에 드러난다.
- 채팅 로그는 너무 잘게 쪼개기보다 한 세션을 하나의 document로 유지하고 변화 시 upsert하는 편이 권장된다.
- Hindsight는 내부적으로 chunking을 수행하므로, 운영자는 “얼마나 문맥을 보존할지”를 더 신경 쓰면 된다.
- metadata는 recall 결과에 구조화 문맥으로 반환되지만, filtering/isolation 자체는 tags가 담당한다. 즉, “사용자 분리”를 metadata에 기대면 안 된다.
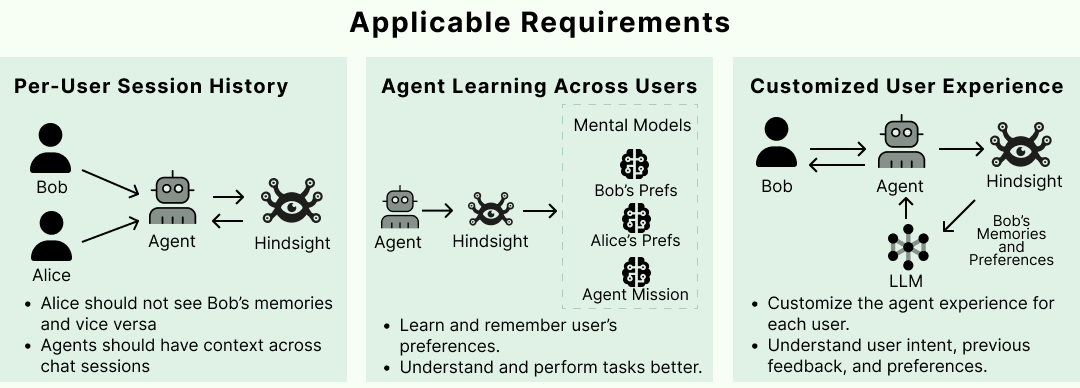
캡션: Hindsight의 per-user memory는 단순 세션 저장이 아니라, 격리·개인화·공유 학습의 균형을 목표로 한다.
5. 통합 표면이 넓다: API, SDK, CLI, UI, MCP, Embedded mode
저장소 구조를 보면 Hindsight는 다양한 도입 경로를 제공한다.
- Python / TypeScript client SDK
- Rust CLI + TUI explorer
- Next.js Control Plane UI
- FastAPI HTTP API
- MCP 서버(
/mcp)를 통한 tool-use 연동 hindsight-embed와hindsight-all을 통한 로컬/임베디드 실행- LiteLLM, LangGraph, CrewAI, AutoGen, Claude Code, Codex 등 폭넓은 integration
즉, 이 프로젝트는 “내 앱이 이미 있는데 메모리만 붙이고 싶다”는 경우와 “관리 UI와 운영면까지 갖춘 memory backend가 필요하다”는 경우를 모두 커버하려고 한다. 이 폭은 일반적인 OSS memory repo보다 훨씬 넓다.
6. 벤치마크 지향성이 강하다
README와 논문은 Hindsight를 단순 기능 중심이 아니라 벤치마크 우위로 포지셔닝한다. 공개 자료에서 가장 자주 반복되는 수치는 LongMemEval 91.4와 LoCoMo 최대 89.61이며, full-context baseline 및 기존 memory architecture 대비 우위를 강조한다.
이 포지셔닝은 단순 마케팅 문구 이상이다. 실제 코드 구조를 보면 recall 파이프라인 분리, reranker, query analyzer, consolidation, monitoring, benchmark 스크립트 등이 저장소 안에 같이 들어 있다. 다시 말해, “성능을 주장하는 프로젝트”가 아니라 성능을 재현하고 추적하려는 프로젝트에 더 가깝다.

캡션: README와 논문은 Hindsight를 장기 기억 벤치마크에서 강한 시스템으로 제시한다. 이 프로젝트의 설계가 retrieval 품질과 reasoning traceability를 동시에 겨냥하고 있음을 보여준다.
7. 운영 친화적이다: 관측성과 bank 단위 관리가 기본 전제로 들어가 있다
Hindsight는 toy demo를 넘어서 운영을 전제한다.
- Prometheus
/metrics - OpenTelemetry tracing
- Grafana LGTM 로컬 모니터링 스택
- bank template / mission / disposition 관리
- document/entity/bank 수준의 관리 API
- Control Plane UI를 통한 시각 탐색
- CLI explorer를 통한 TUI 기반 조사
특히 bank라는 개념을 중심에 둔 설계는 “한 제품 안에서 여러 agent persona/tenant/use case를 운영”하기 좋다. 다만 Discussion을 보면 최종 사용자별 API key를 네이티브하게 전달받는 BYOK 시나리오는 아직 완전한 1급 기능은 아니며, 현재는 LiteLLM proxy를 우회로로 쓰는 방향이 언급된다.
Tech Stack
| 레이어 | 사용 기술 | 버전 / 관찰 포인트 |
|---|---|---|
| Core API | Python, FastAPI, Uvicorn | Python >=3.11, FastAPI >=0.120.3, Uvicorn >=0.38.0 |
| Storage / ORM | PostgreSQL, pgvector, SQLAlchemy, Alembic | SQLAlchemy >=2.0.44, Alembic >=1.17.1, pgvector >=0.4.1 |
| LLM Provider Layer | OpenAI, Anthropic, Google GenAI, LiteLLM, Cohere 등 | OpenAI >=1.0.0, Anthropic >=0.40.0, Google GenAI >=1.0.0, LiteLLM >=1.83.0 |
| Embeddings / Reranking | local sentence-transformers, TEI, cross-encoder | 기본 예시 모델은 BAAI/bge-small-en-v1.5, reranker는 cross-encoder/ms-marco-MiniLM-L-6-v2 |
| File Ingestion | MarkItDown | markitdown[pdf,docx,pptx,xlsx,xls] >= 0.1.4 |
| Embedded / Local | hindsight-embed, pg0 embedded DB |
첫 실행은 모델/의존성 로드로 1 |
| Control Plane | Next.js, React, Tailwind CSS | Next.js ^16.1.7, React ^19.2.0, Tailwind CSS ^4.1.17 |
| Graph / Viz | Cytoscape, cytoscape-fcose, Recharts | Cytoscape ^3.33.1, cytoscape-fcose ^2.2.0, Recharts ^3.5.1 |
| CLI / TUI | Rust, clap, ratatui, crossterm, reqwest | Rust edition 2021, clap 4.5, ratatui 0.29, crossterm 0.28, reqwest 0.12 |
| Observability | Prometheus, OpenTelemetry, Grafana LGTM | 로컬 스택 스크립트와 대시보드 JSON이 저장소에 포함 |
| Docs / DX | Docusaurus, OpenAPI, generated clients | docs site + OpenAPI 기반 SDK 생성 스크립트 제공 |
지원 모델/실행 환경 관점에서 본 해석
.env.example를 보면 LLM provider는 openai, groq, ollama, gemini, anthropic, lmstudio, vertexai, minimax, volcano 등을 예시로 지원한다. 벡터 확장도 pgvector, vchord, pgvectorscale(DiskANN) 중 선택 가능하다. 이는 Hindsight가 특정 SaaS 종속보다 배포/인프라 적응성을 중요하게 본다는 신호다.
Architecture

캡션: Hindsight의 상위 수준 아키텍처. 에이전트는 정보를 저장(retain)하고, 검색(recall)하고, 새로운 통찰을 만든다(reflect).
1) 논리적 메모리 계층
공식 Overview 문서는 Hindsight의 지식 계층을 대체로 다음 네 수준으로 설명한다.
- Mental Model: 자주 쓰는 질의에 대한 사용자 큐레이션 요약
- Observation: facts에서 합성된 중간 수준의 통찰
- World Fact: 외부 세계에 대한 사실
- Experience Fact: agent/bank의 행위와 상호작용에서 나온 사실
여기서 주목할 점은 reflect가 항상 raw fact부터 읽지 않는다는 것이다. Mental Model과 Observation을 먼저 확인하고, 필요할 때 raw fact로 내려가 검증한다. 이는 성능 최적화일 뿐 아니라, “학습된 요약”과 “원자료”를 분리하는 설계다.
용어 주의: 최신 공식 문서는
Mental Model을 최상위 요약 계층으로 강조하지만, 저장소 내 일부 다이어그램은Opinion이라는 레이어 명칭을 사용한다. 코드/문서 전반을 종합하면 핵심 개념은 동일하다. 즉, Hindsight는 원시 facts와 별도로 학습된 고수준 판단/요약 레이어를 보존하려는 방향을 갖는다.
2) 실행 경로
Hindsight의 세 연산은 서로 다른 역할을 가진다.
Retain
- LLM fact extraction
- fact type 분류
- entity recognition / canonicalization
- temporal / semantic / causal link 생성
- memory unit 저장
- 이후 observation consolidation
Recall
- semantic / keyword / graph / temporal 병렬 검색
- RRF fusion
- cross-encoder reranking
- token budget trimming
- 최종 contextual memory set 반환
Reflect
- bank profile(성향/배경/지시문) 로드
- memory hierarchy 기반 증거 수집
- agentic loop로 추가 탐색
- grounded response 생성
- 필요 시 observation/opinion 계층 업데이트
3) 코드 구조에서 본 시스템 분해
문서뿐 아니라 CLAUDE.md와 디렉터리 구조를 읽으면, 프로젝트의 관심사가 매우 분명하게 모듈화돼 있다.
hindsight/
├─ hindsight-api-slim/ # Python FastAPI 서버 + 메모리 엔진
├─ hindsight-control-plane/ # Next.js 관리 UI
├─ hindsight-cli/ # Rust CLI / TUI
├─ hindsight-embed/ # 로컬 daemon 기반 embedded 모드
├─ hindsight-clients/ # 생성형 SDK (Python / TS / Rust)
├─ hindsight-docs/ # Docusaurus 문서 사이트
├─ hindsight-integrations/ # LiteLLM, LangGraph, AutoGen, Claude Code 등
├─ monitoring/ # Grafana dashboards
├─ docker/ # 로컬/외부 DB용 실행 자산
├─ helm/ # Kubernetes 배포 자산
└─ scripts/ # 개발, benchmark, client generation 스크립트핵심 Python 엔진은 대략 다음처럼 읽힌다.
hindsight-api-slim/hindsight_api/engine/
├─ memory_engine.py # retain/recall/reflect 전체 orchestrator
├─ llm_wrapper.py # OpenAI/Anthropic/Gemini/Groq/Ollama/LiteLLM 추상화
├─ embeddings.py # 임베딩 생성
├─ cross_encoder.py # reranking
├─ entity_resolver.py # 엔티티 추출과 정규화
├─ query_analyzer.py # 질의 해석
├─ retain/orchestrator.py # retain 플로우 제어
├─ retain/fact_extraction.py # LLM 기반 fact extraction
├─ search/retrieval.py # 병렬 검색 orchestrator
├─ search/fusion.py # reciprocal rank fusion
└─ search/reranking.py # cross-encoder reranking이 구조는 Hindsight가 사실상 세 층으로 나뉜다는 점을 잘 보여준다.
- Memory ingestion layer
- Hybrid retrieval layer
- Disposition-aware reasoning layer
4) 데이터 계층
저장 계층은 PostgreSQL + pgvector가 기본이며, Alembic migration이 API startup 시 자동 적용된다. 코드 문서에 노출된 핵심 테이블 이름은 다음과 같다.
banksmemory_unitsdocumentsentitiesentity_links
이 설계는 entity-first retrieval과 document provenance를 함께 챙기려는 의도가 분명하다. 특히 documents와 entities를 모두 분리한 점은, 나중에 “무엇을 기억하고 있는가”와 “그 기억의 원문 문서가 무엇인가”를 둘 다 추적하기 쉽게 한다.
Usage & Setup
1) 가장 빠른 로컬 시작: Docker
README 기준 가장 쉬운 시작 경로는 Docker다.
export OPENAI_API_KEY=sk-xxx
docker run --rm -it --pull always -p 8888:8888 -p 9999:9999 \
-e HINDSIGHT_API_LLM_API_KEY=$OPENAI_API_KEY \
-v $HOME/.hindsight-docker:/home/hindsight/.pg0 \
ghcr.io/vectorize-io/hindsight:latest- API:
http://localhost:8888 - Control Plane UI:
http://localhost:9999
외부 PostgreSQL을 쓰고 싶다면 docker/docker-compose 경로의 compose 설정을 이용할 수 있다.
2) Python SDK 경로
pip install hindsight-client -Ufrom hindsight_client import Hindsight
client = Hindsight(base_url="http://localhost:8888")
client.retain(
bank_id="my-bank",
content="Alice works at Google as a software engineer"
)
client.recall(
bank_id="my-bank",
query="What does Alice do?"
)
client.reflect(
bank_id="my-bank",
query="Tell me about Alice"
)이 경로는 Hindsight를 명시적 memory service로 쓰는 방식이다. 메모리를 언제 저장하고 어떤 질의에서 불러올지 애플리케이션이 직접 통제한다.
3) 기존 LLM 앱에 붙이기: Wrapper 우선 접근
프로젝트가 강조하는 가장 짧은 통합 경로는 LLM wrapper다. 기존 OpenAI/LiteLLM 경로를 감싸면 retain/recall이 자동 삽입되는 흐름이다.
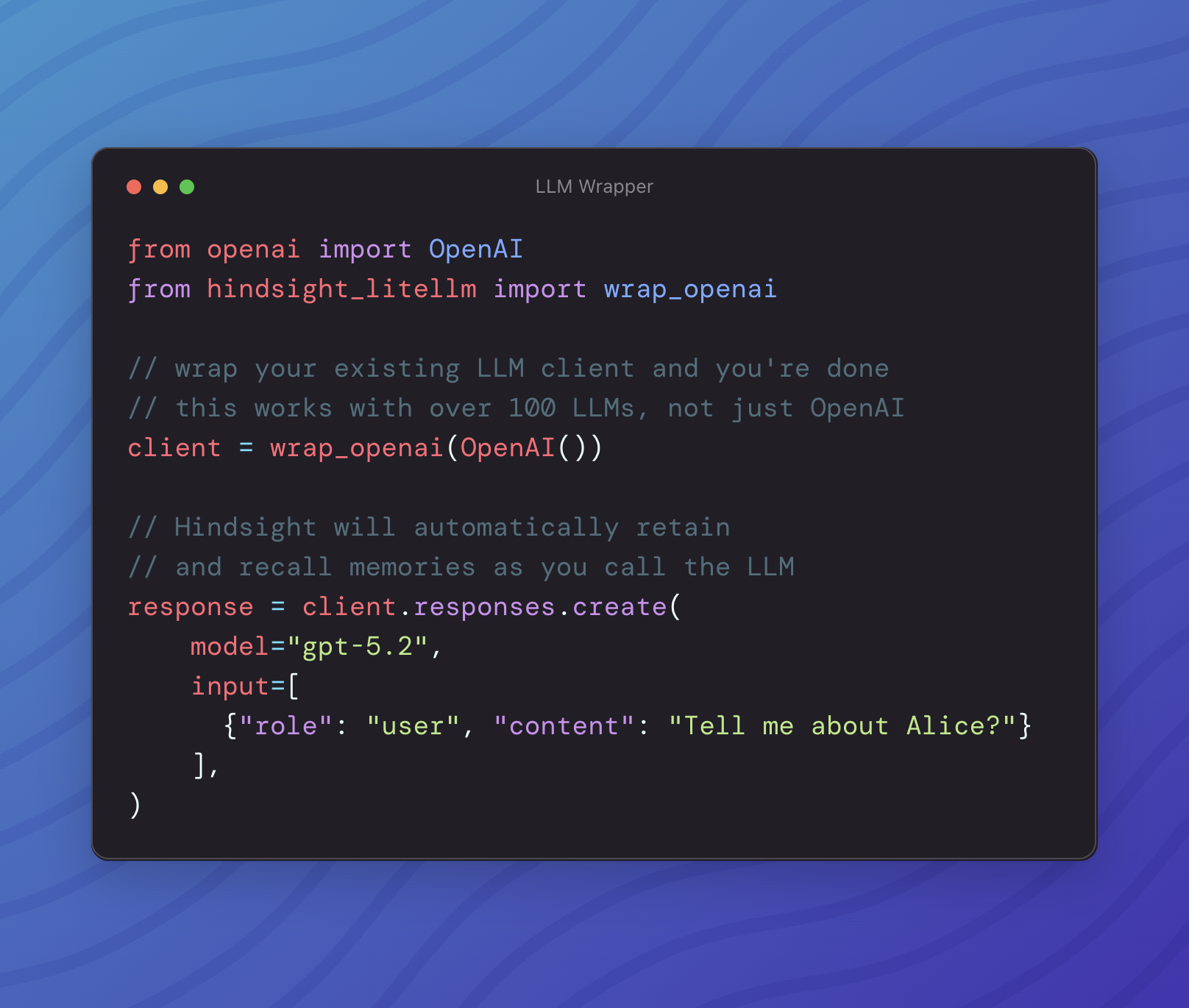
캡션: “내 앱은 이미 있는데, 메모리만 붙이고 싶다”는 팀에게 가장 매력적인 진입점이다.
예시 흐름은 대략 아래와 같다.
from openai import OpenAI
from hindsight_litellm import wrap_openai
client = wrap_openai(OpenAI())
response = client.responses.create(
model="gpt-5.2",
input=[{"role": "user", "content": "Tell me about Alice?"}],
)실무적으로는 이 방식이 가장 빠르다. 다만 “어떤 호출에 메모리를 저장할지”를 세밀하게 통제해야 하는 제품이라면, wrapper보다 명시적 retain/recall API가 더 안전하다.
4) Embedded Python: 서버를 따로 띄우고 싶지 않을 때
README와 hindsight-embed 문서를 보면, Hindsight는 embedded/local mode에 꽤 진심이다.
pip install hindsight-all -Uimport os
from hindsight import HindsightServer, HindsightClient
with HindsightServer(
llm_provider="openai",
llm_model="gpt-5-mini",
llm_api_key=os.environ["OPENAI_API_KEY"]
) as server:
client = HindsightClient(base_url=server.url)
client.retain(bank_id="my-bank", content="Alice works at Google")
results = client.recall(bank_id="my-bank", query="Where does Alice work?")hindsight-embed 문서상 특징은 다음과 같다.
- 첫 실행 시 local daemon이 자동 기동
- 첫 실행은 모델/의존성 준비로 1~3분 소요 가능
- 이후 호출은 대략 1~2초 수준
- 5분 비활성 시 daemon 자동 종료
localhost:8888와 embedded PostgreSQL(pg0) 사용
즉, PoC, 데스크톱 에이전트, 사내 단일 사용자 도구, 민감 데이터 로컬 실험에 적합하다.
5) CLI / TUI / Control Plane
CLI는 단순 wrapper가 아니라 꽤 강력한 운영 표면이다.
curl -fsSL https://hindsight.vectorize.io/get-cli | bash
hindsight configure --api-url http://localhost:8888
hindsight memory retain demo "Alice works at Google"
hindsight memory recall demo "Where does Alice work?"
hindsight memory reflect demo "What do you know about Alice?"
# 웹 UI
hindsight ui
# TUI explorer
hindsight explorehindsight ui는 로컬 port 9999에서 Control Plane을 띄우며, 문서 기준 다음 기능을 제공한다.
- memory bank 관리
- entity explorer / knowledge graph 시각화
- recall / reflect 질의 테스트
- operation history 확인
hindsight explore는 터미널에서 banks, facts, entities, documents를 탐색하는 TUI다. Rust CLI를 별도 패키지로 유지한 이유가 납득되는 지점이다.
6) Per-user memory 구현 패턴
Per-user memory 구현은 공식 문서와 cookbook에 절차가 비교적 잘 정리돼 있다.

캡션: per-user memory는 단순 user_id 저장이 아니라, 입력 보강 → retain → 모델 형성 → filtered recall → personalized response로 이어지는 파이프라인이다.
실전 적용 시 권장할 만한 패턴은 다음과 같다.
- 세션 또는 사용자를 식별할 수 있는 document/tag 체계를 먼저 설계한다.
- 대화는 너무 미세하게 쪼개기보다, 문맥이 살아 있는 document 단위로 retain한다.
- filtering은 metadata가 아니라 tags에 의존한다.
- bank mission에서 “무엇을 추출하고 무엇을 무시할지”를 명확히 적는다.
- 개인화 레이어와 공유 지식 레이어를 bank / tags / documents 수준에서 분리한다.
7) 운영 메모
Monitoring
./scripts/dev/start-monitoring.sh문서 기준 로컬 Grafana LGTM 스택이 함께 제공되며, API의 /metrics를 자동 scrape하고 OTLP endpoint를 통해 trace도 수집할 수 있다.
MCP
API 서버는 /mcp endpoint를 제공한다. Claude Code, Cursor, Codex 같은 tool-use 환경과 연결할 때 유용하다.
파일 기반 ingest
CLI의 retain-files와 API의 file ingestion 경로는 PDF, DOCX, PPTX, XLSX 등 문서형 데이터를 다룰 수 있고, 내부적으로 MarkItDown 기반 변환을 활용한다.
Vector extension
기본은 pgvector지만, 환경 설정상 vchord, pgvectorscale(DiskANN)도 고려돼 있다. 즉, 검색 계층도 단일 로컬 개발 시나리오만 가정하지 않는다.
Personal Insights
1) 의료 AI 관점
의료 AI에서 Hindsight의 가장 강한 지점은 시간성과 근거 추적성이다. 환자/사용자와의 장기 대화에서 중요한 것은 “무엇을 말했는가”보다 언제, 어떤 맥락에서, 반복적으로 나타났는가다. Hindsight의 temporal recall, observation consolidation, mental model 계층은 이런 요구와 잘 맞는다.
다만 의료 도메인에서는 세 가지 원칙이 필요하다.
retain_mission을 매우 엄격하게 설계해, 증상/복약/선호/금기/일정 같은 신호만 추출해야 한다.- World fact(의학 상식)와 Experience fact(환자별 사실)를 혼동하지 않도록 bank 설계를 분리해야 한다.
- personalized filtering을 metadata에 의존하지 말고 tags/tenant isolation로 구현해야 한다.
즉, Hindsight는 의료 지식 자체를 대체하는 엔진이 아니라, 환자별 장기 맥락과 상호작용 이력을 구조화하는 레이어로 볼 때 가장 강하다.
2) Bioinformatics 관점
Bioinformatics나 연구 지원 에이전트에 Hindsight를 적용하면, 단순 문서 검색보다 강한 부분은 entity + temporal + session continuity다. 예를 들어 다음 같은 시나리오가 잘 맞는다.
- 실험 로그와 분석 결정의 장기 축적
- 샘플/유전자/파이프라인 버전/결과 지표 간 연결 추적
- 같은 프로젝트에 걸친 관찰 패턴 요약
- “지난달과 비교해 이번 QC가 왜 달라졌는가?” 같은 temporal question 처리
하지만 이 도메인에서는 엔티티 표준화가 매우 중요하다. 유전자 alias, 샘플 ID, assay 명칭처럼 exact term이 중요한 분야에서는 BM25/keyword와 canonical entity 설계가 성패를 가른다. 다시 말해, Hindsight는 bioinformatics에서 강력할 수 있지만, 성능은 mission 설계와 입력 표준화에 크게 의존한다.
3) Autonomous Agent 관점
자율 에이전트 관점에서 Hindsight의 진짜 강점은 “기억 저장”이 아니라 행동 수정 가능성이다. reflect는 단순한 retrieve-and-answer가 아니라, bank의 disposition과 directives를 바탕으로 과거 경험을 다시 읽고 해석하게 만든다. 이 덕분에 다음 유형의 agent에 특히 잘 맞는다.
- 실패를 통해 작업 방식을 바꿔야 하는 coding agent
- 사용자 피드백을 장기적으로 흡수해야 하는 customer support agent
- 멀티세션 태스크를 이어받는 AI employee
- tool usage ambiguity를 경험을 통해 줄여야 하는 orchestration agent
다만 비용/복잡도도 함께 커진다. 단순한 FAQ bot이라면 RAG나 최근 대화 몇 턴만으로 충분할 수 있다. Hindsight가 진가를 보려면 에이전트가 최소한 아래 두 조건을 만족해야 한다.
- 여러 세션에 걸쳐 상태를 이어야 한다.
- 단순 사실 검색이 아니라 행동과 판단이 시간이 지나며 개선되어야 한다.
4) 내가 보는 핵심 가치와 한계
가장 큰 가치
- memory를 retrieval cache가 아니라 학습 가능한 지식 구조로 다룬다.
- raw facts와 synthesized knowledge를 분리해 설명 가능성을 높인다.
- monorepo 전체가 API/UI/CLI/ops까지 포함해 실제 도입 가능성이 높다.
가장 현실적인 한계
- 구성 요소가 많아 단순 use case에는 과하다.
- mission, tags, bank boundaries를 잘못 잡으면 메모리 품질이 빠르게 무너질 수 있다.
- per-user BYOK 같은 SaaS 멀티테넌시 고급 기능은 아직 일부 우회 구성이 필요하다.
- learned summary layer(
Mental Model/Opinion)의 용어와 문서 표현이 완전히 하나로 정리된 상태는 아니다.
Conclusion
Hindsight는 “벡터 검색을 얹은 챗봇 메모리”가 아니라, 장기 학습형 에이전트를 위한 메모리 substrate다. 프로젝트의 설계 철학은 매우 분명하다. 입력은 구조화되어야 하고, 검색은 다중 전략이어야 하며, 응답은 성향과 규칙을 반영한 반성적 추론이어야 한다.
의료 AI, Bioinformatics, Autonomous Agent 개발이라는 세 관점에서 공통적으로 보이는 결론은 하나다. Hindsight는 단기 recall보다 장기 adaptation에 더 강한 시스템이다. 따라서 “기억”보다 “학습”이 중요한 에이전트를 만들 때 가장 설득력이 크다.
Sources
- GitHub README: https://github.com/vectorize-io/hindsight/blob/main/README.md
- GitHub Releases: https://github.com/vectorize-io/hindsight/releases
- GitHub Discussions #422: https://github.com/vectorize-io/hindsight/discussions/422
- GitHub Discussions #510: https://github.com/vectorize-io/hindsight/discussions/510
- GitHub Discussions #595: https://github.com/vectorize-io/hindsight/discussions/595
- Official Overview: https://hindsight.vectorize.io/
- Recall docs: https://hindsight.vectorize.io/developer/retrieval
- Reflect docs: https://hindsight.vectorize.io/developer/reflect
- CLI docs: https://hindsight.vectorize.io/sdks/cli
- Monitoring docs: https://hindsight.vectorize.io/developer/monitoring
- Best Practices: https://hindsight.vectorize.io/best-practices
- Paper: https://arxiv.org/abs/2512.12818
'AI 생성 글 정리 > tech_github' 카테고리의 다른 글
| opendataloader — 로컬 우선(local-first) 구조 추출과 하이브리드 AI 보강을 결합한 PDF 파서 (0) | 2026.04.10 |
|---|---|
| Gemma Multimodal Fine-Tuner — Apple Silicon에서 Gemma 4/3n 멀티모달 LoRA를 실행하는 실전형 튜너 (0) | 2026.04.09 |
| Superpowers — 코딩 에이전트에 설계·계획·구현·검증 습관을 주입하는 skill-driven 개발 프레임워크 (1) | 2026.04.09 |
| InkOS — 다중 에이전트 기반 자율 소설 집필 CLI/Studio (0) | 2026.04.09 |
| OpenScreen — 오픈소스 Screen Studio 대안, Electron 기반 데스크톱 데모 레코더/에디터 (0) | 2026.04.09 |



