핵심 요약
이 논문은 추론할 때의 연산량에 주목한다.
기존 스케일링 법칙은 주로 학습 단계에 집중했다.
- 모델을 얼마나 키울 것인가
- 학습 토큰을 얼마나 늘릴 것인가
- 학습 연산량을 어떻게 배분할 것인가
이 논문은 질문을 바꾼다.
이미 학습된 모델을 쓸 때, 제한된 추론 예산을 어디에 써야 가장 정확한가?
결론은 명확하다.
- 큰 모델이 항상 최적은 아니다.
- 작은 모델에 더 많은 추론 절차를 붙이면 더 효율적일 수 있다.
- 단순 샘플링과 투표는 결국 성능이 포화된다.
- 저자들이 제안한 REBASE는 실험 전반에서 가장 좋은 비용 대비 성능을 보였다.

문제의식: 학습 스케일링에서 추론 스케일링으로
Chinchilla류의 학습 스케일링은 모델 크기와 학습 토큰의 균형을 다룬다.
이 논문은 같은 관점을 추론 단계로 옮긴다.
추론 단계의 선택지는 다르다.
- 어떤 크기의 모델을 쓸 것인가
- 답을 몇 번 생성할 것인가
- 후보 답을 어떻게 고를 것인가
- 트리 탐색을 쓸 것인가
- 보상 모델로 중간 풀이를 평가할 것인가
즉, 최적화 대상이 모델 크기 + 추론 전략으로 확장된다.
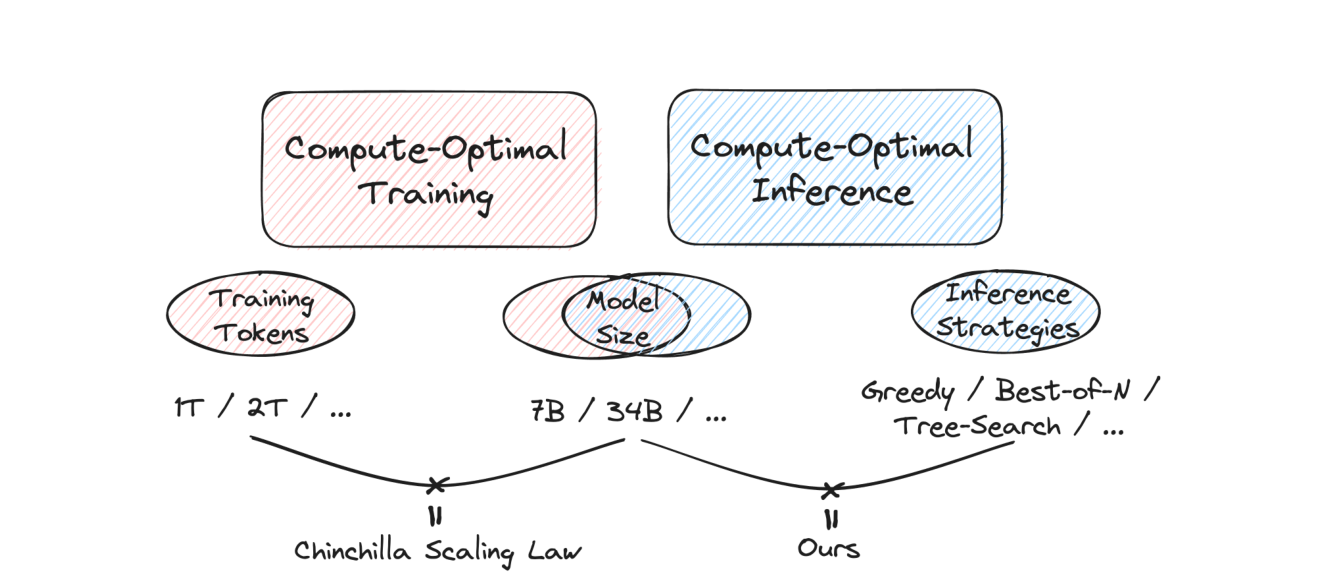
Crop 포인트: 오른쪽의 “Inference Strategies”가 모델 크기와 함께 새로운 최적화 축으로 들어간다는 점에 주목하면 된다.
연구 질문
논문은 두 가지 질문을 실험으로 확인한다.
1. 같은 추론 전략이라면, 어떤 모델 크기가 최적인가?
큰 모델은 한 번의 생성 비용이 크다.
작은 모델은 한 번의 생성 비용이 낮다.
따라서 같은 예산이라면 작은 모델은 더 많은 후보 풀이를 만들 수 있다.
이때 작은 모델이 큰 모델보다 나을 수 있는지가 핵심이다.
2. 같은 예산이라면, 어떤 추론 전략이 최적인가?
논문은 다음 전략을 비교한다.
- Greedy search: 매 순간 가장 가능성이 높은 토큰을 고른다.
- Best-of-N: 여러 답을 만들고 보상 점수가 가장 높은 답을 고른다.
- Majority voting: 여러 답 중 가장 많이 나온 답을 고른다.
- Weighted majority voting: 보상 점수로 후보 답의 투표 가중치를 조정한다.
- MCTS: 트리 탐색으로 풀이 경로를 탐색한다.
- REBASE: 보상 점수로 탐색 폭을 조절하는 저자들의 새 트리 탐색 방법이다.
핵심 실험 환경
실험은 수학 문제 풀이에 집중한다.
사용 데이터셋은 두 가지다.
- GSM8K: 초등·중등 수준의 수학 추론 문제
- MATH500: 더 어려운 고등학교 수학 경시 수준 문제
사용 모델은 다음과 같다.
- Pythia 계열: 여러 모델 크기 비교용
- Llemma-7B, Llemma-34B: 수학 특화 모델
- Mistral-7B: 다른 아키텍처에서도 경향 확인용
보상 모델은 Llemma-34B를 기반으로 한다.
이 보상 모델은 풀이의 중간 단계에 점수를 주는 방식으로 사용된다.
결과 1: 추론 연산량을 늘리면 좋아지지만, 무한히 좋아지지는 않는다
Pythia 계열 실험은 추론 스케일링의 기본 형태를 보여준다.
아래 그래프에서 오류율은 낮을수록 좋다.
왼쪽은 같은 모델에서 추론 연산량을 늘릴 때의 변화다.
오류율은 꾸준히 내려가다가 어느 시점부터 둔화된다.
오른쪽은 같은 예산에서 어떤 모델 크기가 유리한지 보여준다.
초기에는 작은 모델이 유리하다.
예산이 충분히 커지면 더 큰 모델이 유리해지는 구간도 나타난다.

Crop 포인트: 오른쪽 패널의 별표는 “같은 예산에서 최적인 모델 크기”가 고정되어 있지 않다는 점을 보여준다.
이 결과는 배포 관점에서 중요하다.
현실의 서비스는 보통 추론 예산이 제한되어 있다.
그 구간에서는 큰 모델을 한 번 쓰는 것보다 작은 모델로 더 많이, 더 똑똑하게 추론하는 쪽이 나을 수 있다.
왜 단순 샘플링은 한계가 있는가
논문은 투표 기반 방법의 이론적 한계도 분석한다.
수식으로 표현하면 복잡하지만, 직관은 단순하다.
모델이 여러 풀이를 샘플링하면 결국 “그 모델이 자주 내는 답” 쪽으로 수렴한다.
따라서 모델 내부 분포가 틀린 답에 더 많은 무게를 주고 있다면, 샘플 수만 늘려도 완전히 해결되지 않는다.
가중 투표도 마찬가지다.
보상 모델이 좋은 답에 더 높은 점수를 줄 수 있으면 한계는 올라간다.
그러나 여전히 포화 지점은 존재한다.
그래서 필요한 것은 단순히 더 많이 뽑는 방식이 아니다.
좋은 풀이 경로를 더 적극적으로 찾아가는 방식이 필요하다.
REBASE: 좋은 중간 풀이에 더 많은 탐색을 배정하는 방식
REBASE는 트리 탐색이다.
하지만 전통적인 MCTS와 다르게 비싼 rollout에 크게 의존하지 않는다.
핵심 절차는 다음과 같다.
- 풀이를 단계별 노드로 본다.
- 보상 모델이 각 중간 풀이의 품질을 평가한다.
- 점수가 높은 노드에 더 많은 확장 기회를 준다.
- 완성된 풀이를 모아 최종 후보로 쓴다.
- 후보 답은 best-of-N 또는 weighted majority voting으로 고른다.
즉, REBASE는 “좋아 보이는 풀이 흐름”에 예산을 더 쓴다.
동시에 이미 완성된 풀이도 후보로 회수한다.
이 구조가 MCTS보다 효율적인 이유다.

Crop 포인트: 보상 모델에서 SOFTMAX로 이어지는 흐름은 각 노드의 품질이 다음 탐색 폭을 결정한다는 의미다.
결과 2: MATH500에서는 REBASE가 가장 좋은 비용 대비 성능을 보인다
MATH500은 더 어려운 수학 문제다.
여기서는 좋은 풀이 경로를 찾는 능력이 더 중요해진다.
아래 그래프는 Llemma-7B와 Llemma-34B를 비교한다.
동시에 sampling, MCTS, REBASE를 비교한다.
REBASE는 대부분의 예산 구간에서 가장 낮은 오류율을 보인다.
특히 7B 모델에 REBASE를 붙인 조합이 강하다.
이는 “작은 모델 + 좋은 추론 전략”이 “큰 모델 + 단순 전략”보다 효율적일 수 있음을 보여준다.

Crop 포인트: 주황색 REBASE 7B 곡선이 낮은 오류율을 유지하는 구간을 보면, 작은 모델의 추론 예산 효율이 드러난다.
논문은 Llemma-7B가 Llemma-34B와 비슷한 정확도에 도달하는 데 더 적은 연산량이 필요하다고 보고한다.
핵심은 모델 크기가 아니다.
같은 예산을 어디에 쓰느냐다.
결과 3: GSM8K에서도 REBASE가 강하지만, 포화가 더 빠르다
GSM8K는 MATH500보다 쉬운 문제 세트다.
따라서 성능 포화가 더 빠르게 나타난다.
그래도 REBASE는 sampling보다 좋은 비용 대비 성능을 보인다.
다만 쉬운 문제에서는 모델이 이미 정답 쪽에 높은 확률을 주는 경우가 많다.
그래서 더 어려운 MATH500보다 전략 간 차이가 줄어드는 구간도 있다.

Crop 포인트: GSM8K에서는 오류율이 빠르게 내려간 뒤 완만해지는 구간이 길어지며, 쉬운 문제에서의 조기 포화를 보여준다.
결과 4: 모델이 약할수록 트리 탐색의 이득이 커진다
논문은 Llemma-7B, Llemma-34B, Mistral-7B를 함께 비교한다.
MATH500에서는 REBASE의 개선 폭이 특히 눈에 띈다.
저자들은 MATH에서 다음과 같은 개선을 보고한다.
- Mistral-7B: 약 5.3% 개선
- Llemma-7B: 약 3.3% 개선
- Llemma-34B: 약 2.6% 개선
성능이 약한 모델일수록 탐색 전략이 더 큰 도움을 준다는 뜻이다.

Crop 포인트: Mistral-7B와 Llemma-7B에서 REBASE 곡선이 sampling보다 더 아래로 내려가는 차이를 보면, 약한 모델일수록 탐색의 보정 효과가 크다는 점이 보인다.
GSM8K에서도 비슷한 흐름이 나타난다.
다만 문제 난도가 낮기 때문에 곡선들이 더 빨리 수렴한다.
그럼에도 REBASE는 낮은 오류율 구간에 더 빨리 도달한다.

Crop 포인트: 세 모델 모두에서 REBASE 계열 곡선이 초반 예산 구간부터 빠르게 내려가는 흐름을 보면 된다.
결과 5: 더 적은 샘플과 더 적은 연산으로 더 높은 정확도를 얻는다
논문의 Table 1은 REBASE의 비용 효율을 직접 보여준다.
sampling은 많은 후보를 만든다.
REBASE는 더 적은 후보를 만들지만 더 좋은 경로에 집중한다.
| 모델 | 방법 | 샘플 수 | 추론 연산량 | MATH500 정확도 |
|---|---|---|---|---|
| Mistral-7B | Sampling | 256 | 약 870조 FLOPs | 42.8 |
| Mistral-7B | REBASE | 32 | 약 136조 FLOPs | 45.0 |
| Llemma-7B | Sampling | 256 | 약 1,000조 FLOPs | 45.5 |
| Llemma-7B | REBASE | 32 | 약 148조 FLOPs | 46.8 |
| Llemma-34B | Sampling | 64 | 약 1,210조 FLOPs | 46.7 |
| Llemma-34B | REBASE | 32 | 약 708조 FLOPs | 49.2 |
표의 의미는 단순하다.
REBASE는 더 적은 샘플로도 더 높은 정확도를 낸다.
이는 “많이 뽑기”보다 “잘 골라 확장하기”가 낫다는 증거다.
보충 결과: 다수결만 써도 REBASE의 이점은 유지된다
부록에서는 majority voting만 사용한 결과도 제시된다.
MATH500에서는 REBASE가 sampling majority voting보다 낮은 오류율을 보인다.
이는 REBASE가 후보를 고르는 단계 이전부터 더 나은 풀이 후보를 만든다는 뜻이다.

Crop 포인트: 각 모델에서 REBASE M.V. 곡선이 Sampling M.V.보다 아래에 있는지를 보면 된다.
GSM8K의 majority voting 결과도 같은 방향이다.
쉬운 문제라 포화는 빠르지만, REBASE는 낮은 오류율로 더 빠르게 이동한다.

Crop 포인트: GSM8K에서도 REBASE M.V.가 초기 예산 구간에서 빠르게 오류율을 낮추는 흐름에 주목하면 된다.
보충 결과: 가중 투표의 이득은 sampling에서 더 크다
논문은 majority voting과 weighted majority voting도 비교한다.
sampling에서는 두 방식의 차이가 크다.
보상 모델이 후보 답의 품질을 구분해 주기 때문이다.
하지만 REBASE에서는 차이가 상대적으로 작아진다.
REBASE 자체가 이미 보상 모델을 이용해 좋은 풀이를 많이 뽑기 때문이다.

Crop 포인트: MATH500에서 sampling의 M.V.와 W.M. 간격, 그리고 REBASE의 M.V.와 W.M. 간격 차이를 비교하면 된다.
GSM8K에서도 같은 해석이 가능하다.
보상 기반 가중 투표는 여전히 유용하다.
다만 REBASE를 쓰면 후보 풀이의 평균 품질이 이미 높아진다.
그래서 최종 투표 방식의 차이가 줄어든다.

Crop 포인트: REBASE 계열 곡선들이 서로 가까워지는 구간은 탐색 단계에서 이미 후보 품질이 정리되었음을 시사한다.
논문의 핵심 기여
1. 추론 스케일링 법칙을 실험적으로 분석했다
이 논문은 학습이 아니라 추론 예산에 초점을 맞춘다.
모델 크기, 생성 토큰 수, 추론 전략이 성능에 어떤 영향을 주는지 체계적으로 비교했다.
2. 작은 모델이 큰 모델보다 효율적일 수 있음을 보였다
같은 연산 예산에서는 작은 모델이 더 많은 후보를 만들 수 있다.
적절한 추론 전략을 쓰면 이 장점이 커진다.
3. 투표 기반 샘플링의 포화 한계를 설명했다
샘플을 무한히 늘려도 성능은 모델과 보상 모델의 내부 분포에 묶인다.
따라서 단순 샘플 수 증가는 장기적으로 수익이 줄어든다.
4. REBASE를 제안했다
REBASE는 중간 풀이의 보상 점수로 탐색 폭을 조절한다.
비싼 rollout을 줄이고, 좋은 후보 풀이를 더 효율적으로 만든다.
실험에서는 sampling과 MCTS보다 좋은 비용 대비 성능을 보였다.
실무적 시사점
큰 모델부터 고르는 것은 최적이 아닐 수 있다
추론 예산이 제한되어 있다면 다음 조합을 함께 비교해야 한다.
- 큰 모델 + 단순 생성
- 작은 모델 + 다중 샘플링
- 작은 모델 + 보상 모델
- 작은 모델 + 트리 탐색
논문의 결과는 마지막 조합이 강력할 수 있음을 보여준다.
샘플 수만 늘리는 전략은 곧 한계에 부딪힌다
여러 답을 뽑아 투표하는 방식은 간단하고 효과적이다.
하지만 모델이 틀린 풀이를 자주 생성하면 한계가 생긴다.
보상 모델과 탐색 전략이 필요한 이유다.
보상 모델 품질이 중요해진다
REBASE는 보상 모델이 중간 풀이를 평가한다는 전제 위에 있다.
보상 모델이 부정확하면 탐색이 잘못된 방향으로 확장될 수 있다.
따라서 추론 최적화는 모델 하나의 문제가 아니다.
정책 모델, 보상 모델, 탐색 알고리즘의 조합 문제다.
한계
이 논문은 수학 문제 풀이에 초점을 맞춘다.
다른 작업에서도 같은 결과가 유지되는지는 추가 검증이 필요하다.
예를 들어 다음 영역은 별도 연구가 필요하다.
- 코드 생성
- 장문 추론
- 도구 사용 에이전트
- 계획 수립
- 일반 질의응답
또한 REBASE는 보상 모델에 의존한다.
보상 모델이 잘못된 중간 풀이를 높게 평가하면 탐색 효율이 떨어질 수 있다.
정리
이 논문의 메시지는 단순하다.
추론도 스케일링의 대상이다.
모델을 키우는 것만이 답은 아니다.
같은 예산 안에서 더 많은 후보를 만들고, 더 좋은 후보를 탐색하고, 더 정확하게 선택하는 전략이 중요하다.
특히 REBASE는 작은 모델의 비용 효율을 크게 끌어올린다.
이는 LLM 배포에서 중요한 방향을 제시한다.
앞으로의 최적화는 “가장 큰 모델을 쓸 것인가”가 아니라 “주어진 예산을 모델 크기와 추론 절차 사이에 어떻게 나눌 것인가”의 문제가 될 가능성이 크다.
Source
- Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, Yiming Yang. Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for LLM Problem-Solving. arXiv:2408.00724v2, 2024.
- Paper: https://arxiv.org/abs/2408.00724
- Project page: https://thu-wyz.github.io/inference-scaling/
- Figures are extracted from the provided paper PDF.
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| Positive Alignment: Artificial Intelligence for Human Flourishing 논문 정리 (0) | 2026.05.18 |
|---|---|
| Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering 논문 정리 (0) | 2026.05.18 |
| Chain-of-Agents 논문 정리 (0) | 2026.04.28 |
| O-Researcher 논문 정리 (0) | 2026.04.28 |
| CASTER 논문 정리 (0) | 2026.04.28 |



