한 줄 요약
ReVeal은 코드 생성 모델이 스스로 테스트를 만들고, 실행 결과를 보고,
코드를 반복 수정하도록 학습시키는 강화학습 프레임워크다.
핵심은 단순하다.
정답을 맞혔는지만 보상하지 않는다.
검증을 잘했는지도 직접 학습시킨다.
그 결과 모델은 추론 시간에 더 많은 반복을 써도 성능이 계속 오른다.
논문에서는 3턴만 학습한 모델이 20턴 이상 추론을 이어가며 성능을 높이는 결과를 보인다.

왜 이 논문이 중요한가
최근 코드·수학 추론 모델은 “검증 가능한 보상”으로 크게 발전했다.
예를 들어 코드 문제에서는 실행 결과가 맞는지 확인할 수 있다.
하지만 기존 방식은 주로 마지막 결과만 본다.
- 최종 코드가 맞았는가
- 테스트를 통과했는가
- 정답 형식을 지켰는가
이 방식에는 약점이 있다.
모델이 중간에 어떤 검증을 했는지 학습하지 못한다.
그래서 어려운 문제에서는 “반성하는 척”만 하거나, 무작위로 다시 시도하는 경우가 생긴다.
ReVeal은 이 지점을 바꾼다.
모델이 코드를 쓰는 능력과 테스트를 만드는 능력을 함께 키운다.
핵심 아이디어: 풀기보다 검증이 쉽다
ReVeal의 출발점은 검증-생성 비대칭이다.
어떤 문제는 처음부터 정답을 만들기는 어렵다.
하지만 후보 답이 맞는지 확인하는 일은 상대적으로 쉽다.
코드 문제에서는 이 차이가 더 분명하다.
코드를 바로 완성하기는 어렵지만, 작은 테스트를 만들어 실행해 보면 오류를 찾을 수 있다.
ReVeal은 이 차이를 의도적으로 키운다.
검증 능력을 강하게 학습시켜서, 검증이 생성 과정을 끌고 가도록 만든다.

주목 포인트: 파란 검증 곡선이 빨간 생성 곡선보다 높은 위치에 남아 있어, 검증 능력이 생성 개선을 이끄는 구조를 보여준다.
ReVeal의 작동 방식
ReVeal은 한 번에 답을 내지 않는다.
각 문제를 여러 번의 생성-검증 턴으로 나눈다.
한 턴은 다음 흐름으로 진행된다.
- 모델이 후보 코드를 작성한다.
- 모델이 직접 테스트 케이스를 만든다.
- Python 인터프리터가 코드를 실행한다.
- 실행 결과가 다음 턴의 피드백이 된다.
- 모델은 오류를 해석하고 코드를 수정한다.
중요한 점은 별도의 비평 모델이 없다는 것이다.
하나의 정책 모델이 코드 생성과 검증을 모두 수행한다.
이 구조는 비용을 줄인다.
또한 코드 작성 전략과 테스트 작성 전략이 서로 영향을 주며 함께 발전할 수 있게 만든다.
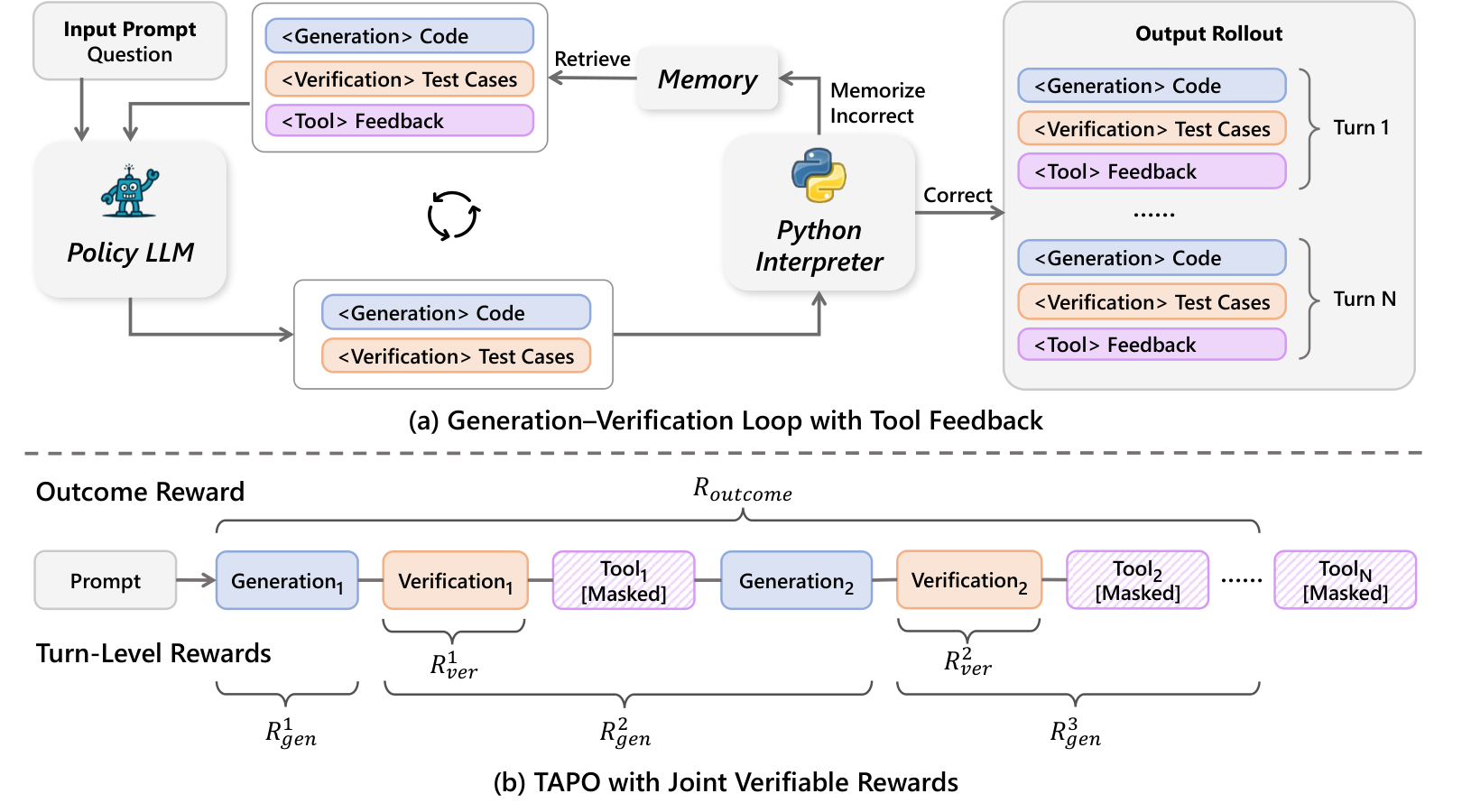
주목 포인트: 위쪽 루프는 코드·테스트·실행 피드백이 반복되는 과정을, 아래쪽 흐름은 각 턴에 보상이 어떻게 배정되는지를 보여준다.
TAPO: 턴별로 공을 정확히 나누는 방법
ReVeal의 학습 알고리즘은 TAPO다.
Turn-Aware Policy Optimization의 약자다.
역할은 명확하다.
긴 추론 과정에서 어느 턴이 실제 개선에 기여했는지 더 정확히 나눠 준다.
ReVeal은 보상을 세 갈래로 본다.
- 최종 결과가 맞았는가
- 이전 코드보다 이번 코드가 나아졌는가
- 모델이 만든 테스트가 유효하고 신뢰할 만한가
여기서 중요한 설계가 있다.
코드 생성 턴은 코드 품질로 평가한다.
검증 턴은 테스트 품질과 다음 코드 개선에 미친 영향으로 평가한다.
이렇게 해야 보상 해킹을 줄일 수 있다.
예를 들어 모델이 허술한 코드를 만들고 쉬운 테스트만 통과시키는 식의 편법을 막는다.
실험 설정
학습 데이터는 TACO 기반이다.
원본에서 실행 불가능하거나 품질이 낮은 문제를 걸러낸 뒤, 11,151개 문제를 학습에 사용했다.
별도 테스트 문제는 509개다.
주요 평가는 다음 벤치마크에서 진행됐다.
- LiveCodeBench V6
- CodeContests
- 추가 평가: HumanEval+, MBPP+
기본 모델은 주로 DAPO-Qwen-32B다.
추가로 Qwen2.5-32B-Instruct와 Qwen3-4B-Instruct에서도 실험했다.
핵심 결과: 추론 턴을 늘릴수록 성능이 오른다
가장 눈에 띄는 결과는 테스트 시간 확장이다.
ReVeal은 학습 때 최대 3턴만 사용했다.
그런데 추론 때는 25턴까지 성능이 계속 오른다.
LiveCodeBench V6에서 Pass@1은 다음처럼 증가한다.
| 설정 | Pass@1 |
|---|---|
| 1턴 | 34.8% |
| 3턴 | 36.7% |
| 25턴 | 38.7% |
기존 단일 턴 RL은 최종 결과 중심 보상만 사용한다.
ReVeal은 검증을 직접 학습하기 때문에 더 깊은 반복에서도 무너지지 않는다.

주목 포인트: 왼쪽 그래프에서는 추론 턴이 늘수록 성능이 상승하고, 오른쪽 그래프에서는 ReVeal이 샘플 수가 커져도 다른 기준선을 계속 앞선다.
단순한 반복이 아니다
ReVeal의 성능 향상은 “그냥 여러 번 시도했기 때문”으로 보기 어렵다.
논문은 여러 비교를 제시한다.
| 비교 항목 | 결과 |
|---|---|
| LiveCodeBench V6 단일 턴 RL | 32.8% |
| LiveCodeBench V6 ReVeal 25턴 | 38.7% |
| CodeContests 단일 턴 RL | 21.0% |
| CodeContests ReVeal 25턴 | 33.6% |
| LiveCodeBench V6에서 틀린 답을 고친 비율 | 7.50% |
| CodeContests에서 틀린 답을 고친 비율 | 15.69% |
| 맞던 답을 틀리게 바꾼 비율 | 0.0% |
특히 마지막 항목이 중요하다.
ReVeal은 틀린 답을 고치면서도, 이미 맞던 답을 망치지 않았다.
이는 검증 신호가 비교적 안정적으로 작동했다는 의미다.
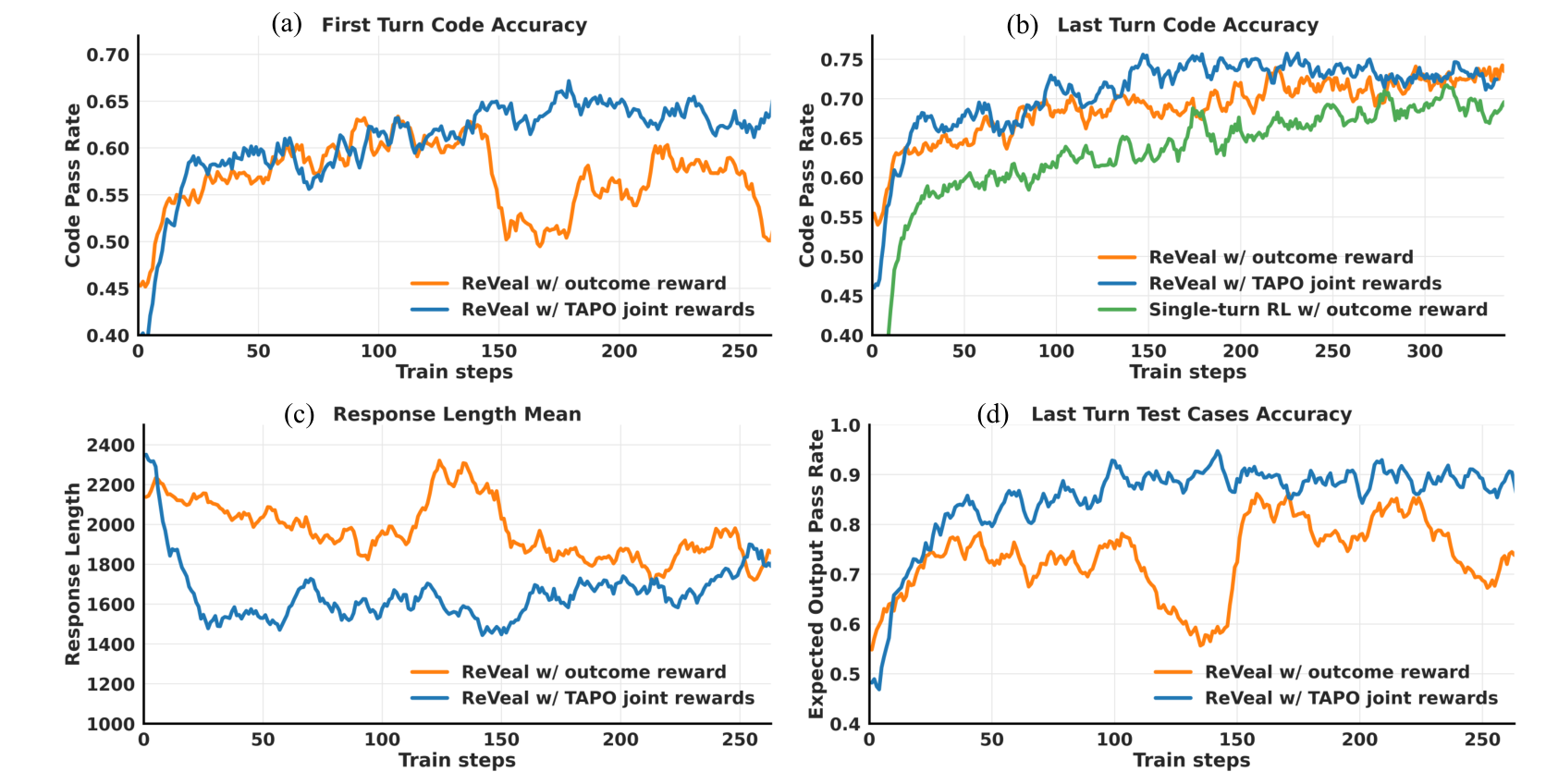
생성과 검증이 함께 자란다
ReVeal의 핵심 주장은 공동 진화다.
코드 생성 능력만 좋아지는 것이 아니다.
테스트를 만들고 판단하는 능력도 함께 개선된다.
학습 곡선을 보면 이 흐름이 보인다.
- 첫 턴 코드 성능이 상승한다.
- 마지막 턴 코드 성능은 더 크게 상승한다.
- 테스트 케이스 정확도도 함께 오른다.
- TAPO를 쓴 모델이 outcome-only 모델보다 더 안정적으로 학습된다.
논문에서는 형식을 익힌 뒤 테스트 케이스 정확도가 약 50% 수준에서 거의 88%까지 오른다고 보고한다.

주목 포인트: 오른쪽 아래 그래프에서 TAPO 모델의 테스트 케이스 정확도가 빠르게 상승하며, 검증 능력이 실제로 학습되고 있음을 보여준다.
다른 모델에서도 효과가 유지된다
ReVeal은 32B급 모델에만 맞춘 기법이 아니다.
Qwen2.5-32B-Instruct에서도 TAPO 기반 ReVeal은 outcome-only 학습보다 높은 성능을 보였다.
반복 실험에서도 평균 성능 차이가 유지됐다.
Qwen3-4B-Instruct 같은 더 작은 모델에서도 개선이 확인됐다.
특히 3턴 학습 후 8턴 추론 설정에서 LiveCodeBench V6 44.5%, CodeContests 33.9%를 기록했다.
이는 ReVeal의 핵심이 모델 크기보다 학습 구조에 있음을 시사한다.
주목 포인트: Qwen2.5-32B-Instruct에서도 TAPO 기반 학습은 코드 정확도와 테스트 정확도를 동시에 끌어올리는 패턴을 보인다.
보상 설계에서 얻는 교훈
논문은 생성 보상을 어떻게 설계해야 하는지도 실험했다.
결론은 현재 코드가 얼마나 좋은지만 보는 것보다, 이전 턴보다 실제로 얼마나 개선됐는지를 보는 쪽이 더 효과적이라는 것이다.
이는 ReVeal의 목표와 맞다.
ReVeal은 한 번에 완벽한 코드를 만들게 하는 시스템이 아니다.
피드백을 통해 점진적으로 나아지게 만드는 시스템이다.
그래서 “현재 점수”보다 “개선 여부”가 더 중요한 신호가 된다.
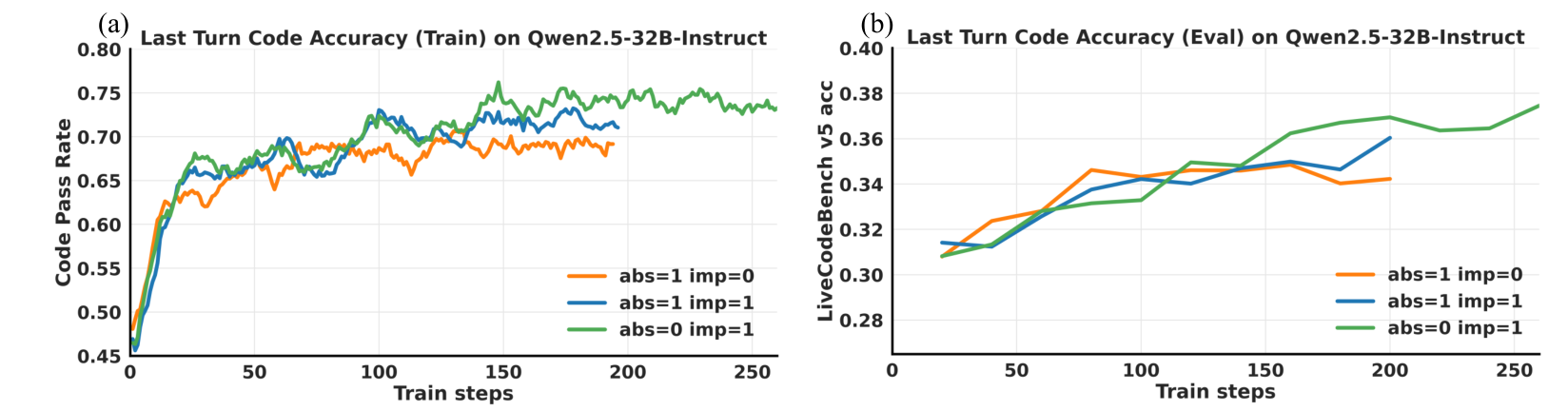
주목 포인트: 초록색 설정은 이전 턴 대비 개선을 강조하며, 학습 및 평가 곡선에서 더 나은 최종 흐름을 만든다.
기존 방법과의 차이
ReVeal은 세 가지 점에서 기존 접근과 다르다.
1. 검증을 직접 학습한다
기존 RLVR은 대체로 최종 정답만 본다.
ReVeal은 테스트 생성과 검증 자체를 학습 목표로 둔다.
2. 공개 테스트에 의존하지 않는다
일부 코드 에이전트는 이미 주어진 테스트를 실행한다.
하지만 현실에서는 충분한 공개 테스트가 없는 경우가 많다.
ReVeal은 모델이 직접 테스트를 만든다.
그래서 더 현실적인 코드 생성 환경에 가깝다.
3. 별도 critic 모델이 필요 없다
비평 모델을 따로 두면 시스템이 복잡해진다.
ReVeal은 하나의 모델이 생성과 검증을 모두 수행한다.
한계
ReVeal도 완전한 해결책은 아니다.
가장 큰 한계는 기능적 정답성 중심 평가다.
코드가 테스트를 통과하면 정답으로 본다.
따라서 비효율적인 brute-force 코드가 테스트를 통과하면 좋은 코드처럼 취급될 수 있다.
시간 복잡도나 메모리 사용량을 더 강하게 반영하려면 추가 장치가 필요하다.
논문은 다음 방향을 제안한다.
- 더 큰 입력을 포함한 스트레스 테스트 추가
- 실행 시간과 메모리 사용량을 도구 피드백에 포함
- 효율적인 코드와 효율성 문제를 드러내는 테스트를 함께 학습
정리
ReVeal의 메시지는 분명하다.
코드 에이전트가 더 오래 생각하게 하려면, 단순히 턴 수를 늘리는 것으로는 부족하다.
각 턴에서 무엇을 검증했고, 그 검증이 다음 코드를 어떻게 바꿨는지 학습해야 한다.
ReVeal은 이 과정을 강화학습 구조 안에 넣었다.
그 결과 모델은 다음 능력을 얻는다.
- 스스로 테스트를 만든다.
- 실행 결과를 해석한다.
- 코드를 안전하게 수정한다.
- 학습 때보다 긴 추론 과정에서도 성능을 높인다.
이 논문은 코드 생성 모델을 “한 번 답하는 모델”에서 “검증하며 진화하는 에이전트”로 바꾸려는 시도다.
Source
- Yiyang Jin, Kunzhao Xu, Hang Li, Xueting Han, Yanmin Zhou, Cheng Li, Jing Bai. “ReVeal: Self-Evolving Code Agents via Reliable Self-Verification.” Published as a conference paper at ICLR 2026.
- Project / Code: https://ReVeal.github.io/
- PDF:
15991_ReVeal_Self_Evolving_Cod.pdf



