한 줄 요약: Crawl4AI는 웹페이지를 LLM/RAG/Agent 파이프라인에서 바로 사용할 수 있는 Markdown·JSON·미디어 메타데이터로 변환하는 오픈소스 비동기 크롤링 프레임워크다.

Quick Links
| 구분 | 링크 | 비고 |
|---|---|---|
| GitHub Repository | unclecode/crawl4ai | README, 소스 코드, 릴리스, 이슈, Discussion |
| 공식 문서 | Crawl4AI Documentation | Quick Start, Core, Advanced, Extraction, API Reference |
| Quick Start | Quick Start | Python SDK, Markdown 생성, CSS/LLM 추출, arun_many() 예제 |
| Self-hosting | Self-Hosting Guide | Docker 서버, REST API, MCP, 모니터링 대시보드 |
| Deep Crawling | Deep Crawling | BFS/DFS/Best-first, 필터, 스코어러, 체크포인트 복구 |
| Docker Architecture | deploy/docker/ARCHITECTURE.md |
FastAPI 서버, 브라우저 풀, 모니터링 구조 |
| Demo / Apps | Demo Apps | 문서 내 앱 섹션으로 제공 |
| 논문 / 인용 | README Citation | 별도 학술 논문은 확인되지 않았고, README는 software citation 형식을 제공 |
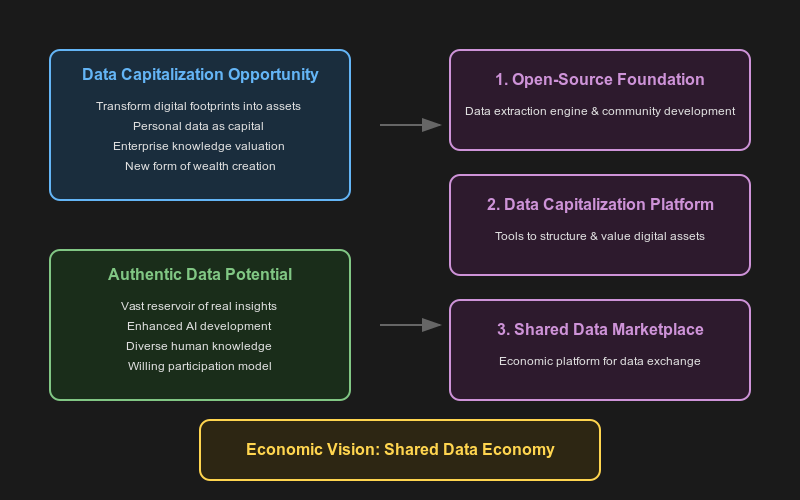
그림 설명: 저장소의 docs/assets/pitch-dark.png 자산이다. Crawl4AI가 단순 크롤러를 넘어 “오픈소스 기반 데이터 구조화 → 데이터 자산화 → 공유 데이터 마켓플레이스”로 확장하려는 제품 비전을 설명한다.
분석 기준
이 리포트는 2026년 5월 29일 기준으로 공개 저장소와 공식 문서를 확인해 작성했다.
GitHub Wiki 주소는 별도 Wiki 콘텐츠가 아니라 저장소 홈으로 리다이렉트되며, 프로젝트의 실질 문서는 docs.crawl4ai.com, docs/, deploy/docker/, README, Discussion에 집중되어 있다.
확인한 주요 영역은 다음과 같다.
- README: 프로젝트 목표, Quick Start, 기능 목록, 설치 커맨드, citation, mission.
- 공식 문서: Quick Start, Self-hosting, Deep Crawling, Advanced, Extraction, API Reference.
- 소스 코드 구조:
crawl4ai/async_webcrawler.py,async_dispatcher.py,browser_manager.py,extraction_strategy.py,markdown_generation_strategy.py,content_scraping_strategy.py,deep_crawling/. - Docker 서버 구조:
deploy/docker/ARCHITECTURE.md, API 예제, 모니터링과 브라우저 풀 설계. - Discussion: Agentic mode, anti-bot, Docker job queue, JsonXPath, browserless, Playwright 설정 노출 같은 실제 사용자 요구가 활발히 올라온다.
Key Features
1. LLM-ready Markdown 생성
Crawl4AI의 핵심 출력은 “사람이 읽는 HTML”이 아니라 “LLM이 안정적으로 소비할 수 있는 Markdown”이다.
README와 문서 모두 Markdown 생성, 제목·표·코드·링크/인용 힌트, fit_markdown 같은 압축된 컨텍스트 생성을 강조한다.
일반적인 웹 스크래퍼는 HTML 조각을 반환하고 이후 정제는 사용자가 직접 처리해야 한다.
Crawl4AI는 이 단계를 DefaultMarkdownGenerator, content filter, cleaned HTML 파이프라인으로 묶어 제공한다.
이 덕분에 RAG 인덱싱, 에이전트 도구 호출, 문서 요약, 데이터 파이프라인에서 후처리 비용이 낮아진다.
2. 구조화 추출: CSS/XPath/LLM 기반 JSON
Crawl4AI는 단순 본문 추출을 넘어 JSON 스키마 기반 데이터 추출을 지원한다.
안정적인 DOM 구조를 가진 페이지에는 JsonCssExtractionStrategy, JsonXPathExtractionStrategy, JsonLxmlExtractionStrategy가 적합하고, 의미 해석이 필요한 페이지에는 LLMExtractionStrategy를 적용할 수 있다.

그림 설명: 코드의 extraction strategy 계층을 바탕으로 재구성한 전략 선택 지도다. 반복 가능한 상품 목록·테이블에는 CSS/XPath 기반 결정론적 추출을, 의미가 복잡한 필드에는 LLM 추출을, 최종 산출물에는 Pydantic/JSON 검증을 결합하는 구성이 적합하다.
기술적으로 중요한 점은 “LLM을 항상 쓰지 않는다”는 점이다.
문서의 Quick Start는 LLM으로 스키마를 한 번 생성한 뒤 반복 추출은 LLM-free 방식으로 수행할 수 있음을 보여준다.
이는 비용과 지연 시간이 민감한 운영 환경에서 큰 장점이다.
3. 브라우저 제어: Playwright/Patchright, 세션, 쿠키, 프록시, Hook
동적 페이지를 처리하기 위해 Crawl4AI는 Playwright 계열 브라우저 전략을 사용한다.
BrowserConfig와 CrawlerRunConfig를 통해 headless 모드, 세션, 쿠키, 프록시, JavaScript 실행, 페이지 상호작용, 스크린샷/PDF 같은 기능을 구성할 수 있다.
browser_manager.py는 세션 ID 기반 페이지/컨텍스트 재사용, managed browser, CDP 연결, persistent context 같은 브라우저 생명주기 관리를 담당한다.
이는 로그인 후 크롤링, lazy loading, virtual scrolling, 인증 쿠키가 필요한 업무에서 유리하다.
4. Deep Crawling과 Adaptive Crawling
단일 URL만 처리하는 스크래퍼와 달리 Crawl4AI는 사이트 내부 링크를 따라가며 여러 페이지를 수집하는 deep crawling 전략을 제공한다.
공식 문서와 deep_crawling/ 소스에는 BFS, DFS, Best-first 전략, 필터 체인, URL scorer, 최대 depth/page 제한, 체크포인트 복구, 취소 콜백이 포함되어 있다.
특히 Best-first 전략은 URL을 발견한 순서대로 무작정 순회하지 않고 키워드 relevance scorer 등으로 우선순위를 부여한다.
이는 문서 사이트, 기업 웹사이트, 제품 카탈로그처럼 관련 없는 하위 페이지가 많은 환경에서 비용을 줄이는 데 도움이 된다.
5. 다중 URL 병렬 처리와 메모리 적응형 Dispatcher
arun_many()는 여러 URL을 병렬로 처리하며, 기본적으로 MemoryAdaptiveDispatcher 같은 dispatcher를 통해 메모리 임계치, 동시 세션 수, rate limiter, streaming/batch 결과 반환을 관리한다.
단순 asyncio gather가 아니라, 대량 URL 작업에서 리소스 압박을 감지하고 조절하는 구조다.

그림 설명: 저장소의 docs/md_v2/assets/images/dispatcher.png 자산이다. Crawler Performance Monitor 화면은 총 작업 수, 성공/실패/대기 작업, 메모리 사용량, peak memory, 평균 처리 시간, timeout 등을 보여준다. 이는 arun_many()와 dispatcher 기반 대량 크롤링의 운영 상태를 설명하는 데 적합하다.
6. Docker Self-hosting, REST API, MCP 도구화
Crawl4AI는 로컬 SDK뿐 아니라 Docker 기반 self-hosted 서버로도 실행할 수 있다.
Self-hosting 문서는 /crawl, /crawl/stream, /html, /md, /screenshot, /pdf, /execute_js 같은 API를 안내하며, MCP(Model Context Protocol) 엔드포인트도 제공한다.
MCP 도구로 연결하면 에이전트가 별도 REST 호출을 직접 작성하지 않고도 Markdown 생성, HTML 추출, 스크린샷, PDF 생성, JavaScript 실행, multi-URL crawl 같은 기능을 도구처럼 사용할 수 있다.
Autonomous Agent 관점에서는 이 부분이 특히 중요하다.
7. 브라우저 풀과 실시간 모니터링
Docker 아키텍처 문서는 permanent/hot/cold 3계층 브라우저 풀을 설명한다.
기본 설정 브라우저는 permanent pool에서 유지하고, 자주 쓰이는 설정은 hot pool, 드문 설정은 cold pool에서 짧은 TTL로 정리한다.
이 구조는 Chromium 기동 비용을 줄이고 컨테이너 메모리를 예측 가능하게 만드는 데 초점을 둔다.
Self-hosted 서버는 /monitor 대시보드를 통해 CPU·메모리, 활성/완료 요청, browser pool 상태, janitor 이벤트, 오류 로그를 실시간으로 보여준다.
대량 크롤링 작업이 실패했을 때 “네트워크 문제인지, 브라우저 풀이 고갈됐는지, 메모리 pressure인지”를 분리해 볼 수 있는 운영 장치다.
Tech Stack
| 영역 | 기술 | 버전 / 비고 |
|---|---|---|
| 언어 | Python | requires-python >=3.10 |
| 패키지 관리 | pyproject.toml, requirements.txt |
PyPI 패키지명: crawl4ai |
| 비동기 HTTP | aiohttp, httpx[http2] |
aiohttp>=3.12.0, httpx[http2]>=0.27.2 |
| 브라우저 자동화 | Playwright, Patchright | playwright>=1.49.0, patchright>=1.49.0 |
| HTML 파싱 | lxml, BeautifulSoup, cssselect | lxml~=5.3, beautifulsoup4~=4.12, cssselect>=1.2.0 |
| 데이터 검증 | Pydantic | pydantic>=2.10 |
| LLM 라우팅 | unclecode-litellm |
unclecode-litellm==1.81.13 |
| 이미지 / 미디어 | Pillow | pillow>=10.4 |
| 검색/랭킹 | rank-bm25, snowballstemmer, nltk |
BM25, stemming, chunk ranking 용도 |
| 시스템 모니터링 | psutil, Rich |
psutil>=6.1.1, rich>=13.9.4 |
| 저장 / 캐시 | SQLite 계열, aiosqlite |
aiosqlite~=0.20 |
| CLI | Click, Rich 기반 CLI | 실행 명령: crwl, crawl4ai-setup, crawl4ai-doctor |
| Docker 서버 | FastAPI 계열 서버 구조 | deploy/docker/server.py, api.py, monitor.py, crawler_pool.py 중심 |
| 선택 의존성 | PyTorch, Transformers, Sentence-Transformers, PDF | torch, transformers, sentence-transformers, pypdf, pdf2image 등 optional extra |
Architecture
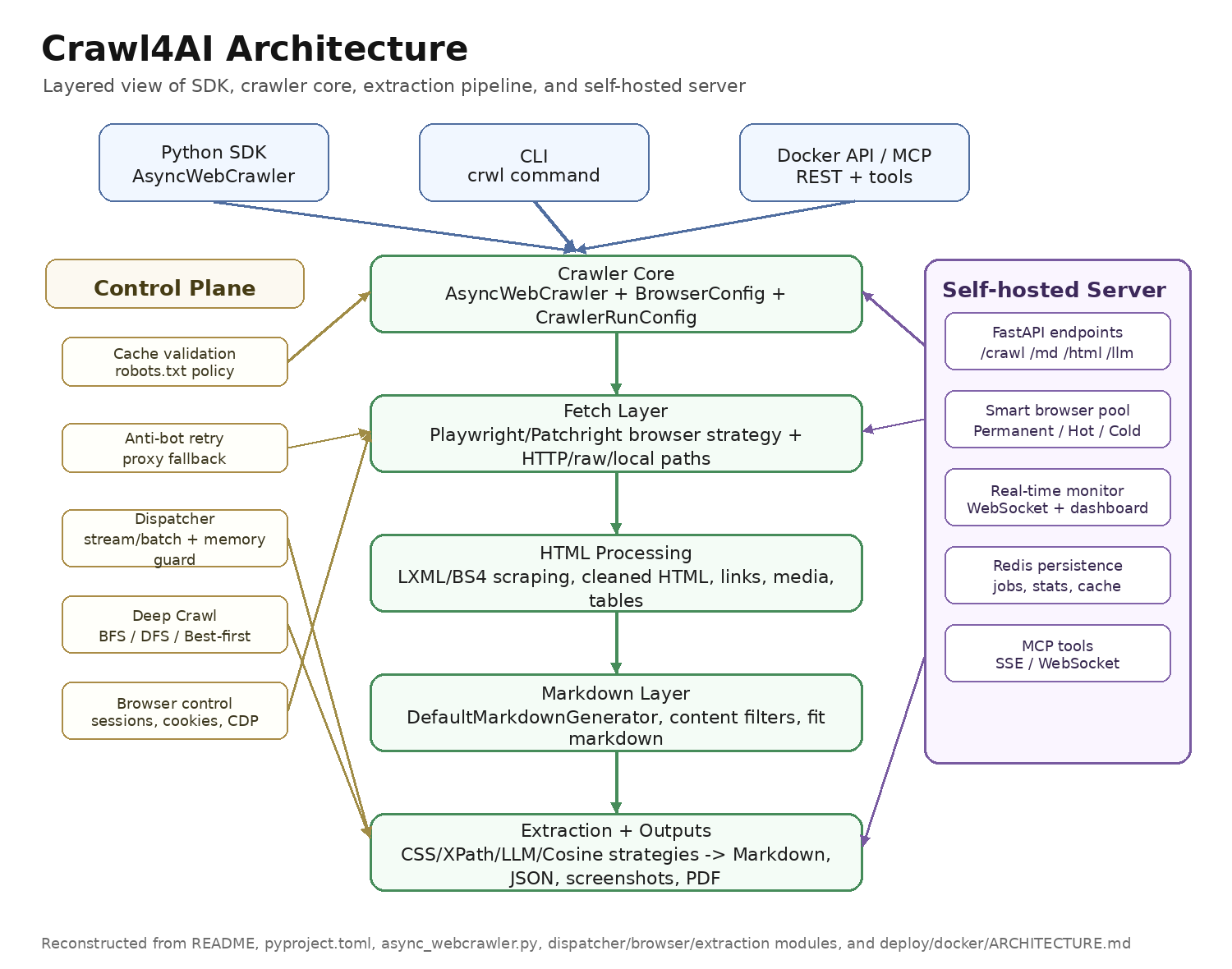
그림 설명: README, pyproject.toml, async_webcrawler.py, async_dispatcher.py, browser_manager.py, extraction/markdown/scraping 전략, deploy/docker/ARCHITECTURE.md를 바탕으로 재구성한 Crawl4AI의 처리 아키텍처다. SDK와 Docker 서버 모두 결국 AsyncWebCrawler 중심의 fetch → clean HTML → Markdown → extraction → output 흐름으로 수렴한다.
전체 처리 흐름
Crawl4AI의 중심에는 AsyncWebCrawler가 있다.
사용자는 Python SDK, CLI, Docker REST API, MCP 클라이언트 중 하나로 URL과 설정을 전달한다.
이후 내부적으로 BrowserConfig와 CrawlerRunConfig가 브라우저·크롤링·추출·캐시·스트리밍 옵션을 결정한다.
실제 fetch 단계는 크게 두 경로다.
JavaScript 렌더링이 필요한 페이지는 Playwright/Patchright 기반 strategy가 브라우저 컨텍스트를 열고, 단순 페이지·raw HTML·local file은 HTTP/raw/local 경로로 처리될 수 있다.
브라우저 경로에서는 세션, 쿠키, user script, proxy, CDP, stealth/anti-bot 설정이 중요하다.
가져온 HTML은 scraping strategy를 거쳐 cleaned HTML로 정제된다.
이 단계에서 script/style 제거, 링크·미디어·표 추출, 내부/외부 링크 분리, metadata 수집이 일어난다.
이후 Markdown generator가 LLM 친화형 Markdown을 만들고, 필요하면 content filter가 fit_markdown을 생성한다.
마지막으로 extraction strategy가 목적에 따라 데이터를 구조화한다.
안정적인 구조에는 CSS/XPath/LXML 전략을, 의미 기반 추출에는 LLM 전략을, topic chunking에는 cosine/BM25 계열 전략을 사용할 수 있다.
결과는 Markdown, JSON, table/media metadata, screenshot, PDF, stream result, API response 등으로 반환된다.
Docker 서버 아키텍처
Self-hosted 서버에서는 이 엔진을 FastAPI 기반 API 계층이 감싼다.
Docker 아키텍처 문서에 따르면 서버는 /crawl, /html, /md, /llm, /screenshot, /pdf 같은 엔드포인트와 monitoring WebSocket을 제공한다.
내부에는 smart browser pool이 있어 permanent/hot/cold pool로 브라우저를 재사용하고, Redis는 작업 결과·통계·캐시성 데이터를 보존하는 데 사용된다.
이 구조는 단순 라이브러리보다 운영형 데이터 수집 시스템에 가깝다.
예를 들어 의료 지침 사이트를 주기적으로 크롤링하거나, 생물정보학 데이터베이스 문서 전체를 RAG 인덱스로 변환하거나, 에이전트에게 “웹에서 정제된 evidence를 가져오는 도구”를 붙일 때 Docker 서버 모드가 더 적합하다.
Usage & Setup
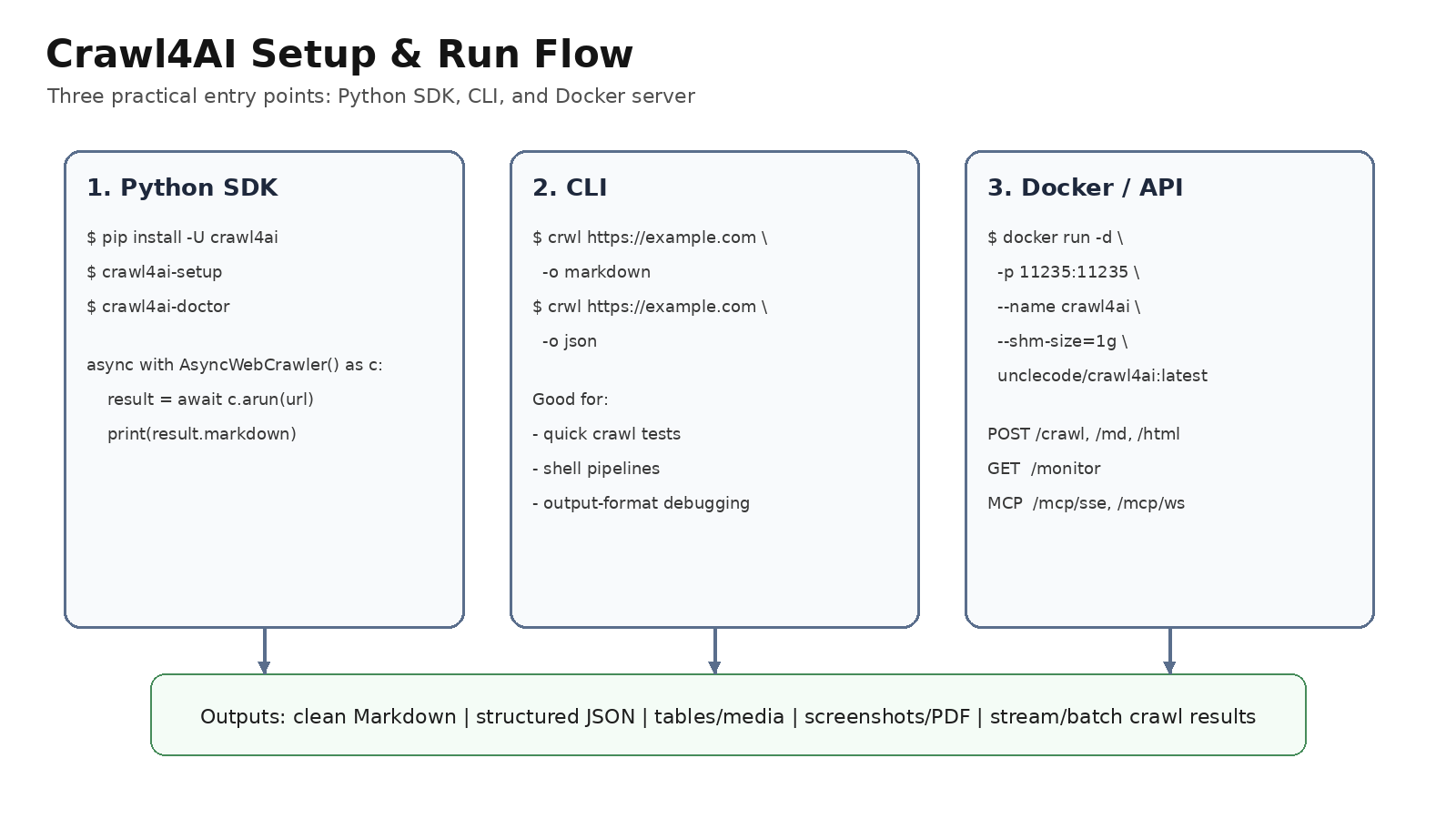
그림 설명: README와 공식 Quick Start를 바탕으로 정리한 설치·실행 흐름이다. 로컬 개발은 Python SDK, 빠른 테스트는 CLI, 운영형 API 제공은 Docker/self-hosting 방식이 적합하다.
1. Python 패키지 설치
pip install -U crawl4ai
crawl4ai-setup
crawl4ai-doctor브라우저 관련 문제가 있으면 Chromium 의존성을 수동 설치한다.
python -m playwright install --with-deps chromium2. 최소 Python 예제
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(url="https://example.com")
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())3. CLI 사용
crwl https://example.com -o markdownCLI는 설치 검증, 간단한 페이지 테스트, shell pipeline 연결에 적합하다.
반복 운영에서는 Python SDK나 Docker API가 더 통제하기 쉽다.
4. Docker 서버 실행
docker run -d \
-p 11235:11235 \
--name crawl4ai \
--shm-size=1g \
unclecode/crawl4ai:latestLLM 기반 추출을 사용할 때는 .llm.env를 전달한다.
docker run -d \
-p 11235:11235 \
--name crawl4ai \
--env-file .llm.env \
--shm-size=1g \
unclecode/crawl4ai:latest서버 실행 후 핵심 접근점은 다음과 같다.
| 용도 | 경로 |
|---|---|
| 기본 서버 | http://localhost:11235 |
| 크롤링 API | POST /crawl, POST /crawl/stream |
| Markdown API | POST /md |
| HTML API | POST /html |
| Screenshot / PDF | POST /screenshot, POST /pdf |
| JavaScript 실행 | POST /execute_js |
| 모니터링 | /monitor |
| MCP | /mcp/sse, /mcp/ws |
Image & Asset Harvesting 결과
| 파일 | 출처 | 문서 내 배치 | 설명 |
|---|---|---|---|
figures/프로젝트_로고.png |
docs/md_v2/assets/images/logo.png |
제목 직후 | 프로젝트 식별용 로고 |
figures/프로젝트_비전.png |
docs/assets/pitch-dark.png |
Quick Links 아래 | Crawl4AI의 데이터 자산화·플랫폼 비전 |
figures/디스패처_성능_모니터.png |
docs/md_v2/assets/images/dispatcher.png |
Key Features - 병렬 처리 | Crawler Performance Monitor 예시 화면 |
figures/아키텍처_다이어그램.png |
코드·Docker 문서 기반 생성 | Architecture 최상단 | 전체 SDK/Docker 처리 파이프라인 |
figures/설치_실행_흐름.png |
README·Quick Start 기반 생성 | Usage & Setup 최상단 | SDK/CLI/Docker 실행 경로 요약 |
figures/추출_전략_맵.png |
extraction strategy 코드 기반 생성 | Key Features - 구조화 추출 | CSS/XPath/LLM/schema 추출 전략 매핑 |
Personal Insights
의료 AI 관점
의료 AI에서 Crawl4AI의 핵심 가치는 “웹 문서를 RAG-ready evidence로 바꾸는 중간 계층”이다.
임상 가이드라인, 병원 공개 문서, 보험 기준, 학회 자료, 규제 문서처럼 HTML 구조가 제각각인 소스를 Markdown과 JSON으로 정제하면, LLM이 참조할 수 있는 근거 문서 레이어를 만들기 쉽다.
다만 의료 도메인에서는 정확성과 감사 가능성이 더 중요하다.
Crawl4AI의 Markdown citation hint, structured extraction, cache validation은 유용하지만, 실제 적용 시에는 다음 보완이 필요하다.
- 원문 URL, 수집 시각, 문서 버전, 해시를 함께 저장한다.
- LLM extraction 결과는 Pydantic schema와 rule-based validator로 검증한다.
- 개인식별정보/PHI가 포함될 수 있는 페이지는 수집 전 접근 권한과 보관 정책을 분리한다.
- 의료 권고문은 “수집된 텍스트”와 “모델의 해석”을 명확히 분리한다.
즉 Crawl4AI는 의료 판단 모델 자체가 아니라, 의료 지식 수집·정제·증거화 파이프라인의 ingestion layer로 보는 것이 안전하다.
Bioinformatics 관점
Bioinformatics에서는 데이터베이스와 문서가 매우 분산되어 있다.
NCBI, Ensembl, UniProt, ClinVar, dbSNP, GEO, 논문 보충자료, 도구 문서 등은 HTML, table, PDF, 동적 페이지가 뒤섞여 있다. Crawl4AI의 강점은 이질적 웹 소스를 하나의 추출 인터페이스로 묶을 수 있다는 점이다.
예를 들어 유전자/변이/질병 관련 페이지에서 반복 구조는 CSS/XPath로 결정론적으로 추출하고, 설명 텍스트는 Markdown으로 보존하며, 불규칙한 설명 필드는 LLM extraction으로 보완할 수 있다.
Deep Crawling은 문서 사이트 전체를 따라가며 도구 매뉴얼이나 API reference를 인덱싱하는 데 적합하다.
실무적으로는 다음 구성이 유용하다.
- CSS/XPath schema: gene table, variant list, publication list처럼 구조가 안정적인 영역.
- Markdown + chunking: 도구 문서, protocol, FAQ, method description.
- Deep crawl + scorer: 특정 organism, assay, variant keyword와 관련된 페이지 우선 수집.
- Cache + versioning: 데이터베이스 업데이트 주기가 다른 리소스의 freshness 관리.
Bioinformatics에서 중요한 것은 “최대한 많이 긁기”가 아니라 “출처와 버전을 잃지 않고 구조화하기”다. Crawl4AI는 그 전처리 프레임워크로 적합하다.
Autonomous Agent 개발 관점
Autonomous Agent에게 웹은 가장 큰 정보원이지만, 동시에 가장 불안정한 입력이다.
에이전트가 브라우저를 직접 조작해 DOM을 읽고 요약하게 만들면, 매번 토큰 비용과 실패 가능성이 커진다.
Crawl4AI는 이 문제를 “도구화된 웹 추출 계층”으로 해결한다.
특히 MCP 지원은 중요하다. 에이전트는 Crawl4AI 서버를 md, html, screenshot, pdf, execute_js, crawl, ask 같은 외부 도구로 호출할 수 있다. 그러면 에이전트는 브라우저 자동화의 세부 구현보다 “어떤 evidence를 가져올 것인가”에 집중할 수 있다.
또한 dispatcher와 browser pool은 장기 실행 에이전트에 필요한 운영 안정성을 제공한다.
예를 들어 에이전트가 수십~수백 개 URL을 조사해야 할 때, 메모리 임계치와 rate limiter 없이 단순 병렬 실행을 하면 쉽게 실패한다.
Crawl4AI는 이를 dispatcher, streaming results, monitor dashboard로 완화한다.
주의할 점도 있다. anti-bot/fallback 기능은 합법적·윤리적 경계를 넘기 위한 도구가 아니라, 정상 접근 가능한 웹페이지에서 기술적 실패를 줄이기 위한 운영 기능으로 다뤄야 한다.
또한 에이전트가 추출 결과를 그대로 사실로 간주하지 않도록 schema validation, source provenance, human review가 필요하다.
종합 평가
Crawl4AI는 “웹페이지를 Markdown으로 바꾸는 도구”라는 설명보다 넓은 범위를 가진다.
실제 구조는 비동기 브라우저 제어, deep crawling, structured extraction, Markdown generation, Docker API, MCP, browser pool, 실시간 모니터링까지 포함한 웹 데이터 ingestion 플랫폼에 가깝다.
가장 강한 사용처는 다음 세 가지다.
- RAG/LLM 애플리케이션을 위한 웹 문서 정제.
- 반복 가능한 웹 데이터 추출을 위한 JSON schema 기반 스크래핑.
- Agent가 안정적으로 호출할 수 있는 self-hosted web extraction tool 제공.
반대로 단순 HTML 다운로드만 필요한 작업이라면 과한 선택일 수 있다. 하지만 의료 AI, Bioinformatics, Autonomous Agent처럼 데이터 출처·구조화·운영 안정성이 중요한 영역에서는 Crawl4AI의 설계가 상당히 실용적이다.
참고 소스
- GitHub Repository: https://github.com/unclecode/crawl4ai
- Official Documentation: https://docs.crawl4ai.com/
- Quick Start: https://docs.crawl4ai.com/core/quickstart/
- Self-hosting Guide: https://docs.crawl4ai.com/core/self-hosting/
- Deep Crawling: https://docs.crawl4ai.com/core/deep-crawling/
- Docker Architecture: https://github.com/unclecode/crawl4ai/blob/main/deploy/docker/ARCHITECTURE.md
- Discussion: https://github.com/unclecode/crawl4ai/discussions
'AI 생성 글 정리 > tech_github' 카테고리의 다른 글
| Lemonade — 클라우드 API처럼 쓰는 로컬 AI 서버 (0) | 2026.05.29 |
|---|---|
| Twenty — AI 시대를 겨냥한 오픈소스 CRM 플랫폼 (0) | 2026.05.29 |
| OpenHarness — 에이전트에게 손, 눈, 기억, 권한을 붙이는 오픈소스 Agent Harness (1) | 2026.05.29 |
| MarkItDown — LLM을 위한 범용 파일→Markdown 변환 엔진 (2) | 2026.05.27 |
| Understand Anything — 코드베이스를 “배우는” 인터랙티브 지식 그래프로 바꾸는 멀티 에이전트 플러그인 (0) | 2026.05.27 |



