이 문서는 원문 논문을 블로그 포스팅 관점에서 빠르게 이해하고 정리할 수 있도록 만든 요약본이다.
핵심 주장, 방법, 실험 결과, figure 해설, 그리고 포스팅할 때 강조하면 좋은 포인트까지 함께 정리했다.
사용한 그림은 원문 PDF에서 직접 crop했으며, 가능한 한 페이지 머리말과 캡션을 제외하도록 정리했다.
논문 한 줄 요약
이 논문은 “데이터 분석을 잘하는 LLM”보다 먼저, “필요한 파일을 제대로 찾는 LLM 시스템”이 중요하다는 문제의식에서 출발한다. 그리고 그 해법으로, 중앙 컨트롤러가 모든 하위 에이전트를 직접 지시하는 대신, 메인 에이전트가 blackboard에 요청을 올리고 각 에이전트가 스스로 응답 여부를 결정하는 자율형 멀티에이전트 구조를 제안한다.[^1][^2]
1. 왜 이 논문이 중요한가
데이터 사이언스에서 실제 병목은 “모델이 코드를 잘 짜는가?”보다 “수많은 파일 중 어떤 파일이 문제 해결에 필요한지 찾을 수 있는가?”인 경우가 많다.
논문은 바로 이 data discovery 문제를 전면에 놓는다.[^1]
기존 접근의 한계는 크게 세 가지다.[^1][^2]
- Single-agent / all-in-context 방식
모든 파일을 한 번에 프롬프트에 넣는 방식은 데이터 레이크가 커지면 곧바로 한계에 부딪힌다. - RAG 방식
일반 문서 검색에는 강하지만, 표 형식 데이터나 도메인 특화 데이터 검색에는 성능이 충분하지 않을 수 있다. - Master-Slave 멀티에이전트 방식
중앙 컨트롤러가 “누가 무엇을 해야 하는지” 잘 알아야 한다.
하지만 큰 데이터 레이크에서는 각 하위 에이전트의 전문성과 보유 정보를 중앙이 완전히 알기 어렵다.
이 논문의 메시지는 명확하다.
문제는 단순한 모델 성능이 아니라, 에이전트들 사이의 “통신 구조”와 “업무 라우팅 방식”이다.[^1][^2]
2. 핵심 아이디어: “지시”하지 말고 “방송”하라
이 논문이 제안하는 구조는 다음과 같다.
- 메인 에이전트는 특정 하위 에이전트를 지목하지 않는다.
- 대신 blackboard에 “어떤 정보가 필요한지”를 broadcast한다.
- 파일 에이전트(file agent)와 검색 에이전트(search agent)는 그 요청을 보고,
자신이 도울 수 있다고 판단할 때만 응답한다. - 메인 에이전트는 모인 응답을 읽고 최종 코드를 생성한다.[^2]
즉, 중앙집중형 task assignment를 분산형 self-selection으로 바꾼 것이다.[^1][^2]
이 구조가 주는 이점
- 중앙 컨트롤러가 각 하위 에이전트의 내부 상태를 완전히 알 필요가 없다.
- 여러 에이전트가 부분적으로 겹치는 전문성을 가질 때도 유연하게 대응할 수 있다.
- 큰 데이터 레이크에서 각 에이전트가 담당 파일 묶음만 이해하면 되므로 확장성이 좋아진다.[^1][^2]
3. 시스템 구조 요약
Figure 1. 전체 구조
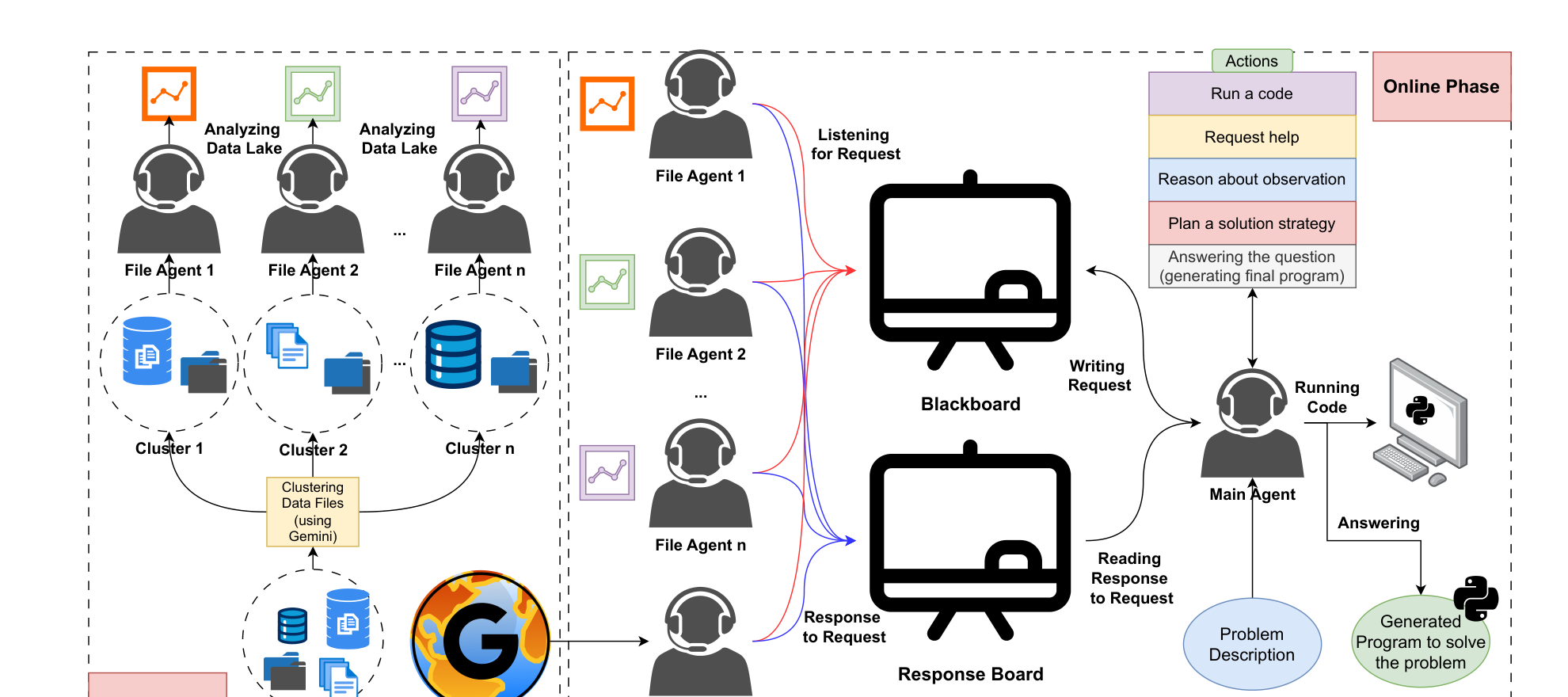
Figure 1. 데이터 레이크를 여러 클러스터로 나누고, 각 클러스터를 file agent가 맡는다. 메인 에이전트는 blackboard에 요청을 게시하고, 각 에이전트는 자율적으로 응답한다.
Figure 1은 이 논문의 핵심을 가장 직관적으로 보여준다.[^1][^2]
오프라인 단계
- 데이터 레이크를 여러 클러스터로 분할한다.
- 각 클러스터는 하나의 file agent가 맡는다.
- 기본 설정에서는 파일 이름만 보고 Gemini 2.5 Pro가 클러스터링한다.[^2][^5]
온라인 단계
- 메인 에이전트는 ReAct 스타일로 문제를 푼다.
- 사용할 수 있는 액션은 대략 다음 다섯 가지다.[^2]
- plan
- reason
- run_code
- request_help
- answer
보조 에이전트 구성
- File agent: 자신이 맡은 파일 묶음을 이해하고, 필요한 파일/컬럼/로드 코드/전처리 방법을 제안한다.
- Search agent: 웹에서 일반 지식이나 도메인 배경지식을 찾는다.[^2]
4. 기존 방식과 무엇이 다른가
| 관점 | Single-agent / RAG | Master-Slave | Blackboard |
|---|---|---|---|
| 데이터 접근 | 하나의 모델 또는 retriever에 크게 의존 | 중앙 컨트롤러가 하위 에이전트를 지정 | 요청을 broadcast하고 하위 에이전트가 자율 응답 |
| 병목 | 컨텍스트 한계, 검색 실패 | 라우팅 오류, 중앙 통제 의존 | 토큰 비용 증가 가능 |
| 장점 | 단순함 | 명시적 분업 | 유연성, 확장성, 에이전트 자율성 |
| 이 논문의 주장 | 대규모/이질 데이터에서는 약함 | 큰 데이터 레이크일수록 불리 | 실제 data discovery에 가장 적합 |
핵심 차이는 하나다.
Master-Slave는 “누가 할지 중앙이 결정”하고, Blackboard는 “누가 할 수 있는지 각 에이전트가 결정”한다.[^1][^2]
5. 실험은 어떻게 했나
논문은 세 가지 벤치마크에서 평가한다.[^1][^3]
- KramaBench: 공개된 data discovery 중심 데이터 사이언스 벤치마크
- DSBench (modified): 원래는 파일이 지정되어 있었지만, 이를 데이터 레이크 형태로 바꿔 data discovery를 강제
- DA-Code (modified): 마찬가지로 data discovery 단계가 필요하도록 재구성
백본 모델은 다음을 사용했다.[^3]
- Qwen3-Coder
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Claude 4 Opus
평가도 두 층위로 나뉜다.[^1][^2]
- 최종 문제 해결 성능
생성한 Python 프로그램을 실행해 정답을 맞히는가 - 파일 발견 성능
실제로 필요한 ground-truth 파일을 잘 찾아냈는가
6. 메인 결과: 정말 더 좋은가?
6.1 최종 문제 해결 성능
아래 표는 Table 1의 평균 macro score만 뽑아 블로그용으로 다시 정리한 것이다.[^3]
| 백본 LLM | RAG | Master-Slave | Blackboard | Blackboard의 최고 baseline 대비 상대 향상 |
|---|---|---|---|---|
| Qwen3-Coder | 3.87 | 5.03 | 7.90 | +57.1% |
| Gemini 2.5 Flash | 14.52 | 14.49 | 16.54 | +13.9% |
| Gemini 2.5 Pro | 18.51 | 24.01 | 28.53 | +18.8% |
| Claude 4 Opus | 23.00 | 27.63 | 31.43 | +13.8% |
이 표가 의미하는 바는 두 가지다.
- 어떤 백본 LLM을 써도 Blackboard가 평균적으로 가장 높다.
- 즉, 이 논문의 기여는 “더 좋은 모델”이 아니라 “더 좋은 에이전트 통신 구조”에 있다.[^1][^3]
논문 초록과 본문은 이 상대 향상 폭을 13%~57%라고 요약한다.[^1]
해석 포인트
이 결과는 단순히 “멀티에이전트가 좋다”는 수준이 아니다.
멀티에이전트라도 중앙이 지시하는 방식보다, 자율 응답 방식이 data discovery 문제에 더 맞는다는 점이 핵심이다.
6.2 파일 발견 성능
파일 discovery 성능(Table 2의 average macro)을 블로그용으로 정리하면 다음과 같다.[^4]
| 방법 | Recall | Precision | F1 |
|---|---|---|---|
| RAG | 0.229 | 0.324 | 0.247 |
| Master-Slave | 0.482 | 0.647 | 0.513 |
| Blackboard | 0.533 | 0.699 | 0.561 |
여기서 중요한 수치는 F1 0.561이다.
최고 baseline인 Master-Slave의 0.513 대비 약 9.4% 향상으로, 논문이 말하는 “up to 9% relative gain in data discovery F1”와 맞아떨어진다.[^1][^4]
즉, 이 논문은 단순히 답을 우연히 잘 맞힌 것이 아니라,
그 이전 단계인 “정확한 파일을 더 잘 찾았다”는 점까지 보여준다.
7. Figure로 읽는 논문의 핵심
Figure 18. Search agent가 실제로 도움이 되는가

Figure 18. Search agent를 넣었을 때와 뺐을 때의 성능 비교. 평균적으로 search agent가 있을 때 더 높은 성능을 보인다.
논문은 메인 에이전트가 도메인 지식이 부족할 때, search agent가 웹에서 보조 정보를 찾아오도록 설계했다.
Figure 18은 이 search agent가 실제로 평균 성능 향상에 기여한다는 점을 보여준다.[^4][^5]
이 포인트는 블로그에서 꽤 중요하다.
왜냐하면 이 시스템은 단순히 “파일 찾기”만 하는 게 아니라,
파일 내부 데이터 + 외부 도메인 지식을 함께 엮어 문제를 푸는 구조이기 때문이다.
Figure 14. Blackboard가 실제 요청-응답을 어떻게 묶는가
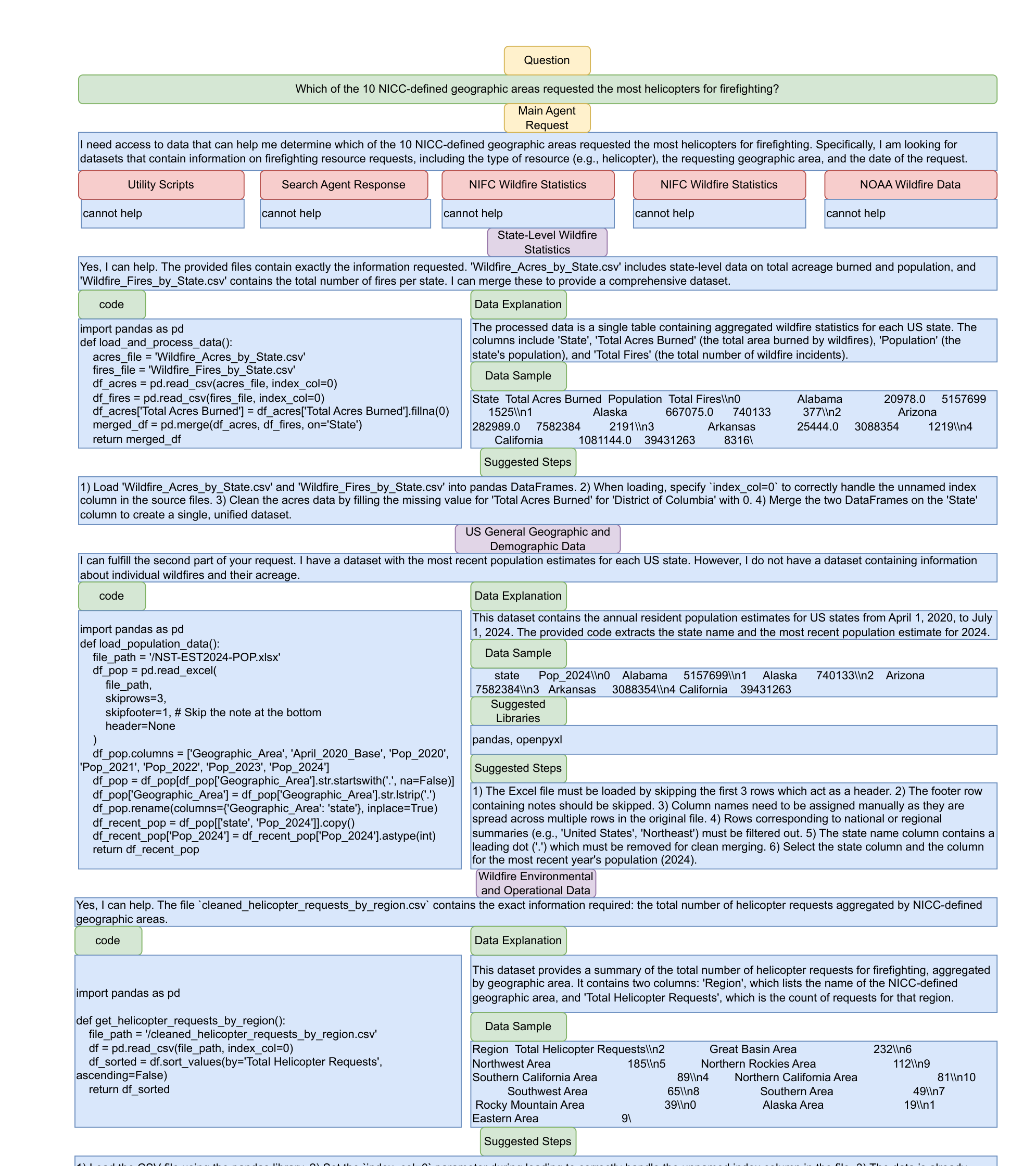
Figure 14. 메인 에이전트가 필요한 정보를 blackboard에 요청하면, 관련 있는 여러 file agent가 동시에 응답하는 예시.
Figure 14는 “왜 blackboard가 유용한가”를 가장 잘 설명하는 사례다.[^6]
- 메인 에이전트는 “헬리콥터 요청 지역을 알고 싶다”는 식으로 필요한 정보의 형태를 적는다.
- 여러 에이전트가 자기 파일 묶음을 기준으로 “도울 수 있다 / 없다”를 판단한다.
- 실제로 필요한 파일이 여러 클러스터에 흩어져 있어도,
관련 에이전트들이 자율적으로 응답을 모아 준다.[^6]
블로그용으로 표현하면 이렇게 정리할 수 있다.
이 시스템의 강점은 “정답을 아는 에이전트를 중앙이 맞혀야 하는 구조”가 아니라,
“관련 있는 에이전트가 스스로 앞으로 나오는 구조”라는 점이다.
Figure 15. 왜 Master-Slave보다 더 정확한가

Figure 15. 동일한 질문에서 Blackboard는 올바른 파일(mmc1.xlsx, mmc7.xlsx)을 선택해 정답 60을 만들고, Master-Slave는 잘못된 파일(mmc2.xlsx)을 골라 오답 74를 낸다.
이 그림은 논문의 주장 전체를 거의 한 장으로 요약한다.[^6]
- Blackboard는 필요한 Age와 APP-Z score가 각각 어느 파일에 있는지 제대로 찾는다.
- Master-Slave는 중앙 라우팅 과정에서 파일 선택이 어긋난다.
- 결과적으로 파일 선택 오류가 바로 정답 오류로 이어진다.[^6]
즉, 이 논문은 “멀티에이전트 협업” 자체보다,
협업 이전의 파일 선택과 라우팅이 얼마나 중요한지를 보여준다.
Figure 20. 데이터 레이크가 커질수록 더 유리한가
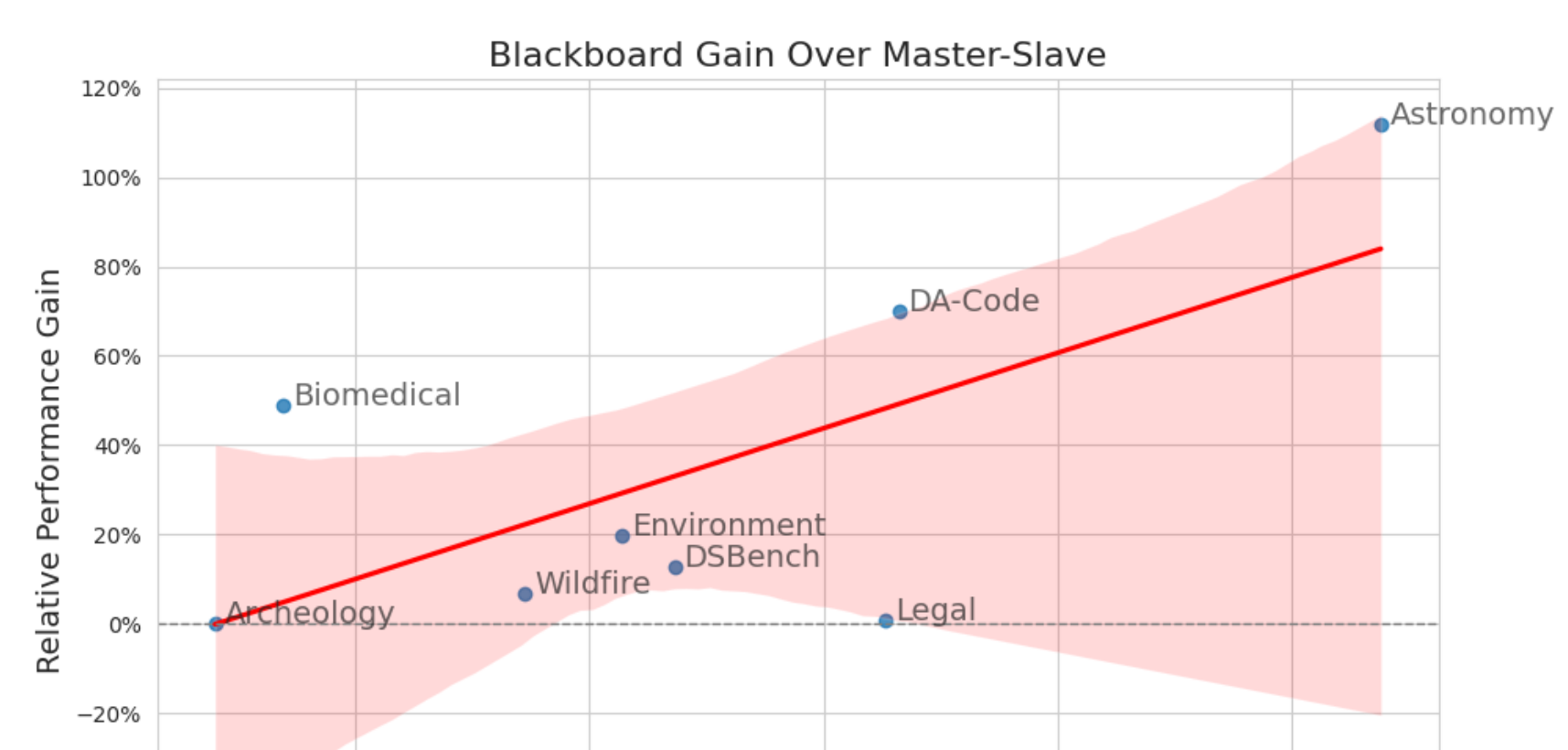
Figure 20. 데이터 레이크 크기(log scale)가 커질수록 Blackboard의 Master-Slave 대비 상대 이득이 커지는 경향을 보여준다.
Figure 20은 이 논문의 확장성 주장을 뒷받침한다.[^5][^7]
- x축: 데이터 레이크 크기
- y축: Master-Slave 대비 Blackboard의 상대 성능 이득
논문의 메시지는 명확하다.
데이터가 커질수록 중앙 라우팅보다 자율 응답 구조가 더 유리해진다.[^5][^7]
이건 실무 관점에서도 중요하다.
파일 수가 적은 toy setting에서는 큰 차이가 안 날 수 있지만,
실제 조직의 데이터 레이크처럼 파일이 많고 이질적일수록 Blackboard 구조의 장점이 커질 가능성이 있다는 뜻이다.
Figure 21. 성능은 좋아졌는데 비용은 어떤가
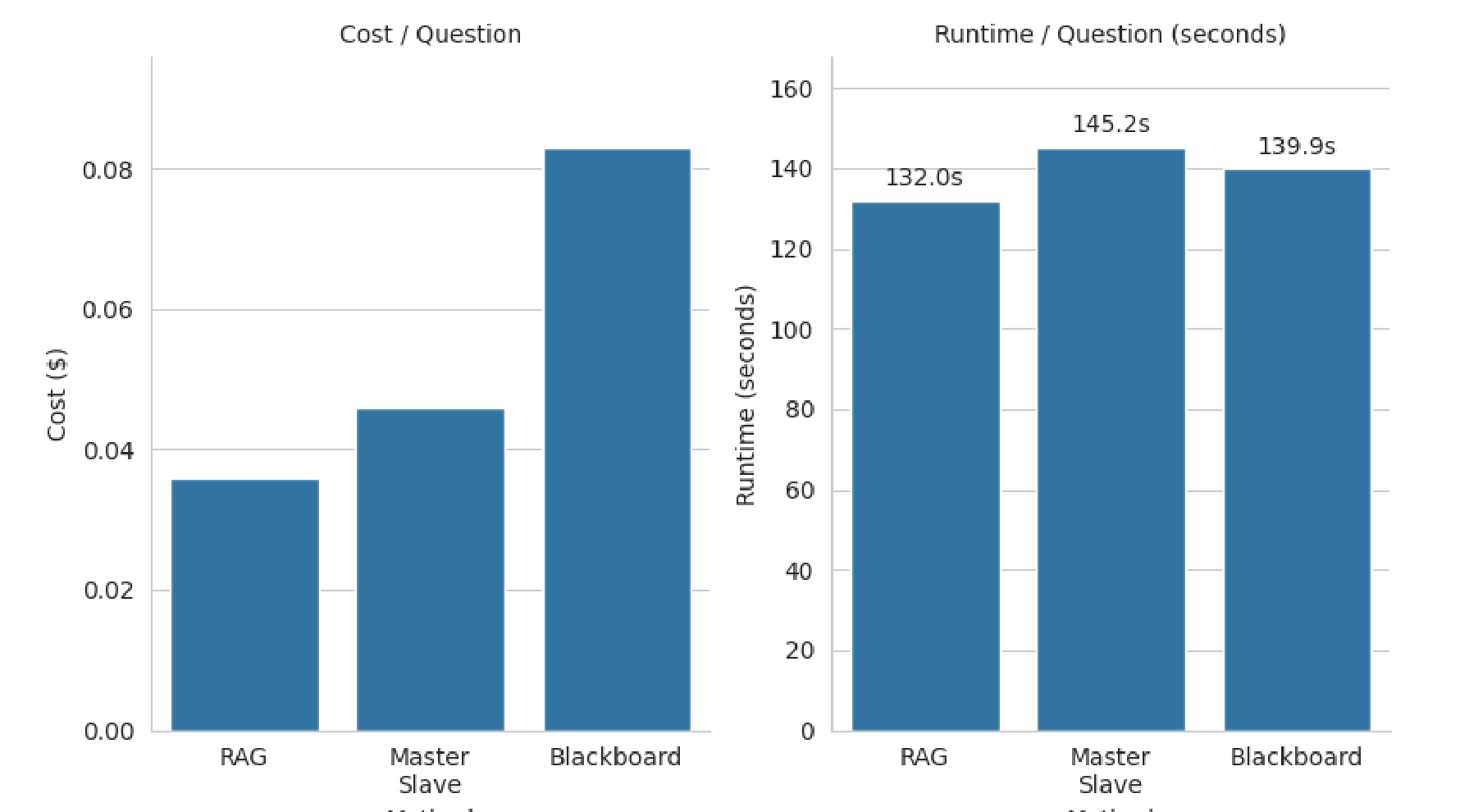
Figure 21. Blackboard는 RAG와 Master-Slave보다 비용은 더 들지만, 런타임은 크게 늘지 않는다.
이 논문은 장점만 말하지 않는다. 비용 문제도 분명히 보여준다.[^5][^7]
- Runtime: 세 방법이 대체로 비슷하다. 대략 132.0-145.2초 범위다.
- Cost: Blackboard가 더 비싸다.
- RAG 대비 약 2.3배
- Master-Slave 대비 약 1.8배[^5][^7]
하지만 논문은 이 비용 증가가 성능 향상으로 상쇄된다고 주장한다.
특히 50개 KramaBench 샘플에서 Blackboard는
- RAG 대비 54.1%
- Master-Slave 대비 18.8%
더 높은 성능을 냈다고 보고한다.[^5][^7]
블로그에서는 이 부분을 다음처럼 쓰면 좋다.
Blackboard는 “무료 점심”은 아니다.
대신 비슷한 실행 시간 안에서 더 높은 토큰 비용을 지불하고 더 나은 정답률을 얻는 구조다.
8. 강조 메시지 5개
- 이 논문은 ‘코드 생성’보다 ‘데이터 찾기’를 더 근본 문제로 본다.
- 성능 차이의 핵심은 모델 크기가 아니라 에이전트 통신 구조다.
- 대형 데이터 레이크에서는 중앙 라우팅보다 자율 응답 구조가 더 잘 맞는다.
- 정답률 향상은 파일 discovery 개선에서 온다.
- 성능은 좋아지지만 비용은 올라가므로, 실무 적용에서는 정확도-비용 trade-off를 함께 봐야 한다.
9. 이 논문의 강점
9.1 문제 설정이 현실적이다
많은 데이터 사이언스 벤치마크는 필요한 파일을 이미 알려준다.
이 논문은 그 직전 단계인 “어떤 파일이 필요한가”를 문제에 포함했다는 점에서 현실성이 높다.[^1][^3]
9.2 구조적 기여가 명확하다
“모델을 더 크게”가 아니라 아키텍처를 바꿔 성능을 올렸다는 점이 분명하다.[^1][^2]
9.3 정량 + 정성 분석이 함께 있다
Table 1, Table 2 같은 정량 결과뿐 아니라, Figure 14/15 같은 실제 실패/성공 사례를 보여준다.[^3][^4][^6]
9.4 스케일 논리가 설득력 있다
작은 세팅보다 큰 데이터 레이크에서 왜 이 구조가 유리한지, Figure 20으로 방향성을 제시한다.[^5][^7]
10. 한계와 비판적으로 볼 포인트
10.1 비용이 확실히 증가한다
정답률 향상은 분명하지만, 토큰 비용은 커진다.
실무에서는 이 구조를 그대로 쓰기보다, 요청 횟수 제한, 클러스터 수 최적화, 응답 agent 수 제한 같은 운영 전략이 함께 필요해 보인다.[^5][^7]
10.2 클러스터링 품질에 영향을 받는다
논문 구조상 file agent가 맡는 파일 묶음이 중요하다.
즉, 처음 파일을 어떻게 나누느냐가 이후 discovery 품질에 직접 영향을 줄 수 있다.[^2][^5]
10.3 일부 평가는 LLM judge에 의존한다
DSBench는 Gemini 2.5 Pro를 judge로 사용하는 평가가 포함되어 있어, 완전한 rule-based evaluation만으로 이뤄진 것은 아니다.[^3]
10.4 논문 내부 서술과 figure 사이에 재확인할 부분이 있다
이건 블로그에서 “좋은 논문이지만 숫자는 한 번 더 체크했다”는 식으로 짚어주면 좋다.
- 본문은 Astronomy/DA-Code에서 상대 향상이 70%와 211%라고 적지만,
Figure 20과 Table 1의 Gemini 2.5 Pro 수치(예: Astronomy 8.47 -> 17.95)를 기준으로 계산하면
Astronomy는 약 112%에 가깝다.
즉, 본문의 211% 표기는 재확인 필요해 보인다.[^8] - 또한 본문은 semantic content clustering이 filename/random보다 “일관되게” 낫다고 서술하지만,
Figure 23을 보면 최소한 Legal subset에서는 random이 더 높은 값으로 보인다.
따라서 클러스터링 관련 서술은 그림과 완전히 일치한다고 보긴 어렵다.[^9]
이 부분은 논문 전체의 가치를 무너뜨릴 정도는 아니지만,
블로그에서 “좋았던 점 + 내가 체크한 부분”으로 써주면 글의 신뢰도가 높아진다.
11. 요약
대부분의 LLM 데이터 사이언스 연구는 이미 필요한 데이터가 주어졌다고 가정하지만, 실제 현업의 병목은 그 이전 단계인 data discovery에 있다. 이 논문은 중앙 컨트롤러가 하위 에이전트에게 일을 배분하는 대신, 메인 에이전트가 blackboard에 요청을 올리고 각 file/search agent가 스스로 응답 여부를 결정하는 구조를 제안한다. 핵심은 task assignment를 중앙집중형에서 자율형으로 바꿨다는 점이며, 실험에서는 RAG와 Master-Slave baseline을 꾸준히 앞서고, 파일 discovery F1도 더 높게 나온다. 특히 데이터 레이크가 커질수록 Blackboard 구조의 상대적 이점이 커진다는 점이 인상적이다. 다만 비용은 더 들고, 일부 appendix 서술은 figure와 100% 일치하는지 재검토가 필요하다.[^1][^3][^4][^5][^7][^8][^9]
13. 최종 코멘트
이 논문은 “에이전트를 몇 개 쓰느냐”보다
“에이전트들이 어떻게 소통하느냐”가 더 중요할 수 있다는 점을 설득력 있게 보여준다.
특히 블로그 관점에서 이 논문은 다음 두 문장으로 요약할 수 있다.
- 데이터 사이언스에서 진짜 병목은 분석보다 발견(data discovery)이다.
- 그 발견 문제에서는 중앙 라우팅보다 자율형 blackboard 구조가 더 잘 작동할 수 있다.
참고 / 출처
- Salemi, A., Parmar, M., Goyal, P., Song, Y., Yoon, J., Zamani, H., Pfister, T., & Palangi, H.
LLM-based Multi-Agent Blackboard System for Information Discovery in Data Science.
arXiv:2510.01285v2, 2026-01-31.
주석
[^1]: Salemi et al., 2026, pp. 1-3. 문제 정의, 기존 접근의 한계, blackboard 패러다임의 핵심 기여 요약.
[^2]: Salemi et al., 2026, pp. 4-6. 시스템 구조, main agent / file agent / search agent, action space 설명.
[^3]: Salemi et al., 2026, p. 8, Table 1; p. 19-20, Table 3 및 실험 설정.
[^4]: Salemi et al., 2026, p. 9, Table 2 및 Figure 2; p. 40, Figure 18.
[^5]: Salemi et al., 2026, pp. 9-10; pp. 31-32. search ablation, scalability, cost/runtime, clustering 분석.
[^6]: Salemi et al., 2026, pp. 30-31; pp. 36-37. Figure 14, Figure 15 사례 분석.
[^7]: Salemi et al., 2026, p. 41, Figure 20-21.
[^8]: Salemi et al., 2026, p. 9의 본문 서술과 p. 41의 Figure 20, p. 8의 Table 1을 교차 확인. 본문 수치와 도표/표 계산값 사이에 일치성 점검이 필요하다.
[^9]: Salemi et al., 2026, pp. 31-32의 clustering 서술과 p. 42의 Figure 23을 교차 확인. 일부 subset에서는 random이 더 높게 보인다.
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| EAGLE-3 논문 정리 (0) | 2026.04.09 |
|---|---|
| In-Place Test-Time Training 논문 정리 (0) | 2026.04.09 |
| SHINE: 하이퍼네트워크 정리 (0) | 2026.04.07 |
| Enhancing Retrieval-Augmented Generation: A Study of Best Practices 논문 정리 (0) | 2026.04.07 |
| Multi-agent Architecture Search via Agentic Supernet 정리 (0) | 2026.04.07 |



