한눈에 보는 결론
- EAGLE-3는 LLM 추론 가속 기법인 speculative sampling 계열의 최신 개선안이다.
- 핵심은 draft model이 꼭 target model의 특정 hidden feature를 흉내 낼 필요는 없다는 점이다.
- 대신 토큰을 직접 잘 맞히는 방향으로 학습하고, 실제 추론 때처럼 자기 출력을 다시 입력으로 받는 상황까지 훈련에 넣는다.
- 이 변화 덕분에 학습 데이터를 늘릴수록 속도 이득도 같이 커지는, 기존 EAGLE에서는 잘 보이지 않던 스케일링 효과가 나타난다.
- 논문 기준 최고 6.5x speedup을 보고했고, SGLang에서는 batch size 64에서도 1.38x throughput 향상을 보였다.
문제 설정: 왜 이런 가속이 필요한가
LLM은 토큰을 한 개씩 순서대로 만든다.
모델이 아무리 똑똑해져도, 답변을 길게 생성할수록 지연 시간은 길어진다.
특히 추론형 모델은 답변 전에 긴 사고 과정을 만들기 때문에 비용과 대기 시간이 더 크게 늘어난다.
이 논문은 여기서 한 가지 질문을 던진다.
"더 똑똑한 모델을 만드는 방식처럼, 더 빠른 추론도 학습 데이터 확대로 같이 좋아질 수 없을까?"
기존 EAGLE 계열은 그 답이 명확하지 않았다.
데이터를 더 넣어도 속도 향상이 크게 늘지 않았기 때문이다.
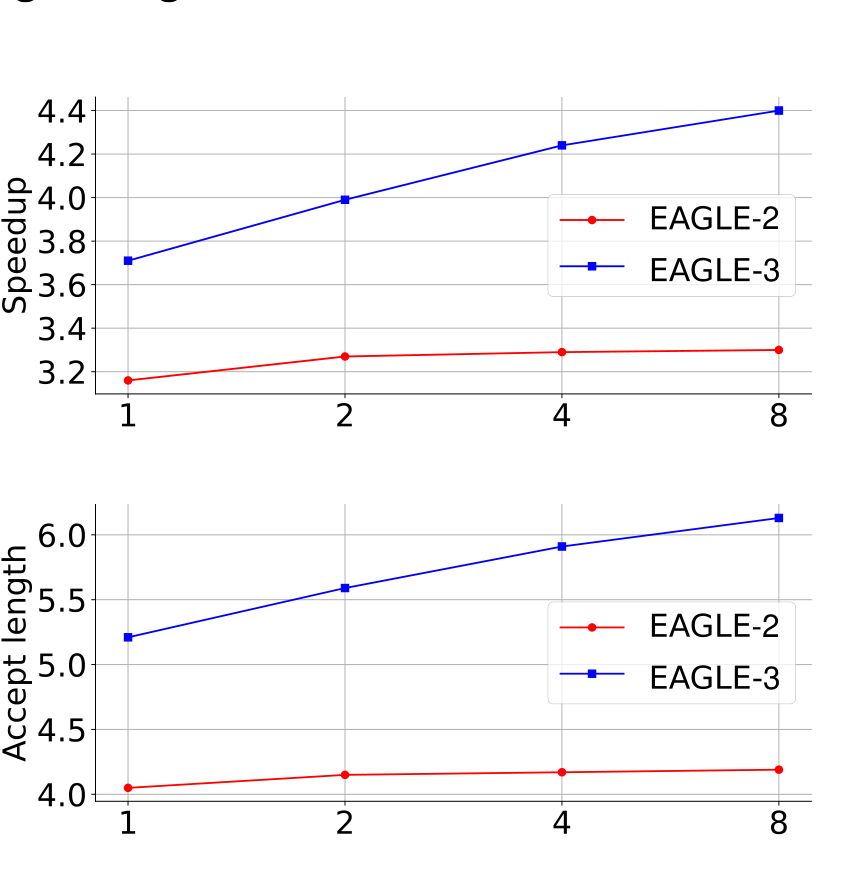
주목 포인트: 파란 선의 상승 곡선입니다. EAGLE-3는 데이터가 늘수록 속도와 한 번에 통과되는 토큰 수가 함께 올라갑니다.
배경: speculative sampling을 아주 짧게 설명하면
아이디어는 단순하다.
- 작은 모델이 다음 몇 토큰을 빠르게 미리 써 본다.
- 큰 모델이 그 초안을 한 번에 검사한다.
- 큰 모델이 동의한 토큰은 여러 개를 한꺼번에 확정한다.
이 방식이 먹히면, 비싼 큰 모델 호출 한 번으로 여러 토큰을 처리할 수 있다.
여기서 중요한 지표는 두 가지다.
- Acceptance rate: 초안 토큰 중 실제로 통과한 비율
- Acceptance length: 한 번의 draft-verify 사이클에서 평균 몇 토큰이 통과했는지
핵심은 분명하다.
draft model이 target model의 다음 행동을 얼마나 잘 맞히느냐가 속도를 정한다.
기존 EAGLE가 잘했던 점과 막혔던 지점
기존 speculative sampling은 보통 더 작은 별도 언어모델을 draft model로 쓴다.
EAGLE은 한 단계 더 나아갔다.
target model의 마지막 층 바로 전 표현을 재활용해, draft model이 더 많은 힌트를 받은 상태에서 초안을 만들게 했다.
이 아이디어 덕분에 EAGLE은 기존 방법보다 빨랐다.
문제는 무엇을 맞히도록 학습했는가였다.
기존 EAGLE은 "다음 토큰"을 직접 맞히기보다, 먼저 다음 hidden feature를 맞히도록 강하게 유도했다.
표면상으로는 그럴듯하다.
하지만 목표가 토큰 예측이라면, hidden feature를 특정 모양으로 복제하라는 요구는 추가 제약이 된다.
즉, draft model 입장에서는 정답을 맞히는 일과 교사의 내부 표현까지 똑같이 따라 하는 일을 동시에 해야 했다.
이 제약은 데이터가 늘어나도 성능을 계속 키우기 어렵게 만든다.
더 큰 문제는 다단계 초안 생성에서 생긴다.
첫 번째 초안은 잘 맞혀도, 두 번째 단계부터는 model이 자기 자신의 추정값을 입력으로 받기 시작한다.
그러면 훈련 때 보던 입력 분포와 실제 추론 때의 입력 분포가 어긋난다.
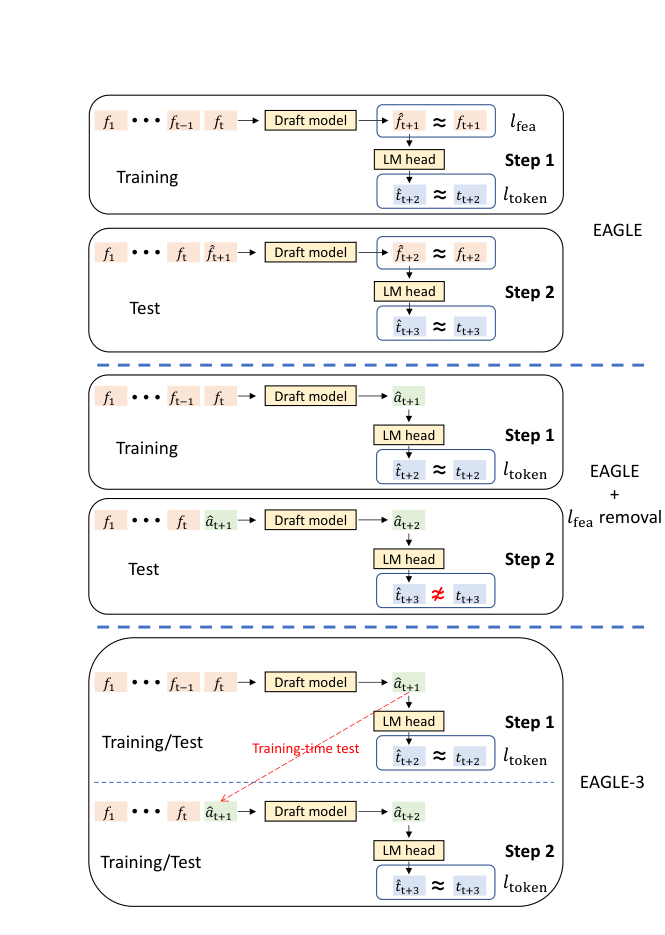
주목 포인트: 맨 아래 블록입니다. EAGLE-3는 훈련 단계부터 자기 출력을 다시 넣어 보며, 실제 추론과 비슷한 입력 환경을 미리 겪습니다.
이 차이는 acceptance rate에서 바로 드러난다.
feature 제약만 없애면 첫 토큰은 더 잘 맞힐 수 있다.
하지만 그 상태로는 두 번째 토큰부터 쉽게 무너진다.
논문은 이 문제를 training-time test로 풀었다.
훈련 도중에도 실제 추론처럼 한 번 예측한 결과를 다음 단계 입력에 다시 섞어 넣는 방식이다.
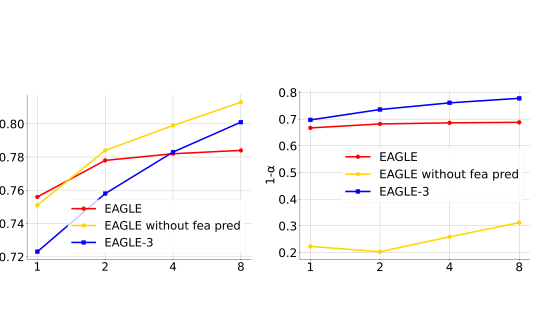
주목 포인트: 오른쪽 그래프입니다. 첫 토큰보다 두 번째 이후 토큰에서 차이가 더 크게 벌어지며, training-time test가 누적 오차를 막는 핵심임을 보여줍니다.
EAGLE-3가 바꾼 것 1: feature prediction을 버리고 token prediction으로
이 논문의 첫 번째 전환점은 명확하다.
draft model이 target model의 특정 hidden feature를 흉내 내게 하지 않는다.
대신 draft model이 토큰을 잘 맞히는 데 집중하게 한다.
이 변화의 의미는 크다.
- 학습 목표가 더 직접적이다.
- draft model의 표현 공간이 덜 묶인다.
- 더 많은 학습 데이터를 넣었을 때, 그 이득이 실제 토큰 예측력으로 더 잘 연결된다.
직관적으로 말하면 이렇다.
이전 EAGLE이 "정답뿐 아니라 풀이 중간 메모까지 비슷하게 써라"에 가까웠다면, EAGLE-3는 "정답을 더 자주 맞히는 방향으로 내부 표현을 자유롭게 써라"에 가깝다.
EAGLE-3가 바꾼 것 2: 마지막 층 하나가 아니라 여러 층을 함께 본다
논문은 top-layer feature 하나만 쓰는 것도 한계라고 본다.
마지막 층 표현은 바로 다음 토큰과 강하게 연결되어 있다.
하지만 speculative sampling은 여러 단계를 미리 내다봐야 한다.
그러면 구문 정보, 문맥 정보, 고수준 의미 정보가 함께 필요하다.
EAGLE-3는 낮은 층, 중간 층, 높은 층의 feature를 합쳐 하나의 fused feature로 만든다.
그리고 여기에 직전 샘플링 토큰의 embedding까지 더해 draft model에 넣는다.
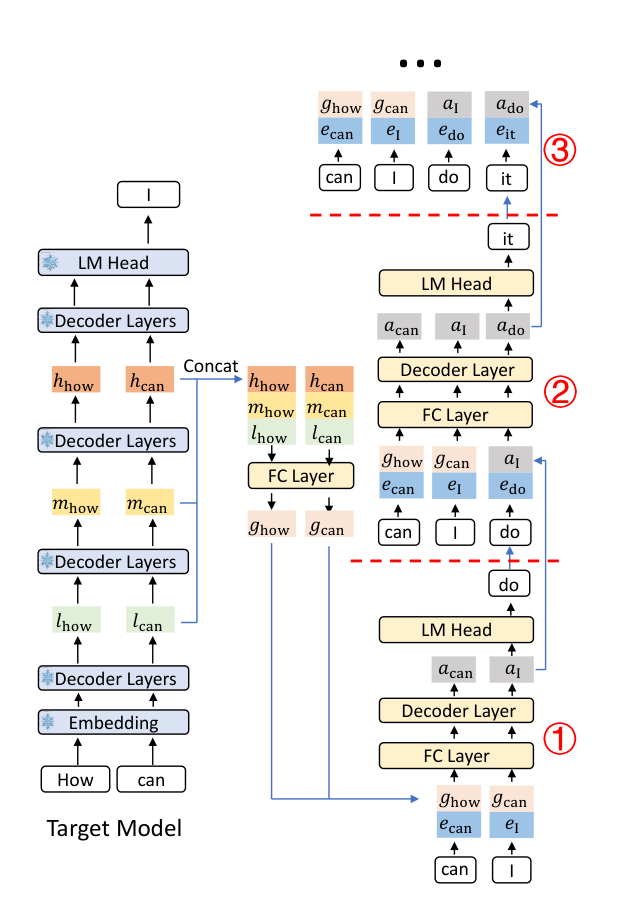
주목 포인트: 왼쪽의 low, middle, high feature가 하나로 합쳐지는 부분입니다. EAGLE-3는 마지막 층 하나보다 더 풍부한 문맥 신호를 초안 생성에 활용합니다.
한편 초안 트리를 문맥에 따라 조정하는 EAGLE-2의 dynamic draft tree도 그대로 가져간다.
즉, EAGLE-3는 새 학습 방식과 기존의 런타임 최적화를 함께 쓴다.
EAGLE-3가 바꾼 것 3: 훈련 때부터 실제 추론의 문맥 구조를 흉내 낸다
training-time test를 넣으려면 attention도 그대로 둘 수 없다.
훈련 데이터의 원래 문맥은 직선형이다.
하지만 draft model이 자기 예측을 다시 입력으로 받기 시작하면, 문맥 관계는 더 트리 형태에 가까워진다.
EAGLE-3는 이 구조를 반영하도록 attention mask를 조정한다.
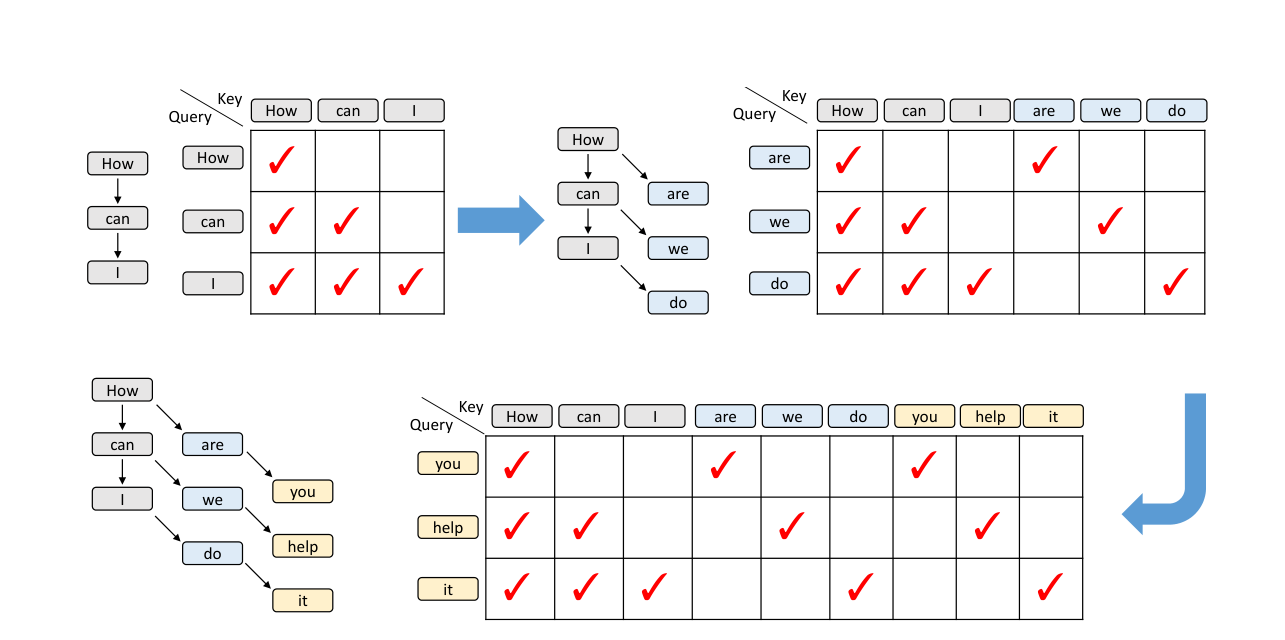
주목 포인트: 아래쪽 마스크 구조입니다. 실제 초안 생성에서 생기는 가지형 문맥 관계를 훈련 때도 반영해, 학습과 추론의 간극을 줄입니다.
이 부분은 구현 디테일처럼 보이지만, 실제로는 꽤 중요하다.
모델이 "훈련에서는 정답 이력만 보고, 실전에서는 자기 예측 이력도 봐야 하는" 불일치를 줄여 주기 때문이다.
결과: 얼마나 빨라졌나
핵심 결과는 단순하다.
거의 모든 비교에서 EAGLE-3가 가장 빠르다.

주목 포인트: 보라색 막대입니다. 서로 다른 모델군에서도 EAGLE-3가 가장 높은 speedup을 반복적으로 기록합니다.
논문에서 특히 눈에 띄는 숫자만 추리면 이 정도다.
| 설정 | EAGLE-2 | EAGLE-3 | 해석 |
|---|---|---|---|
| Vicuna 13B, HumanEval, temperature=0 | 4.96x | 6.47x | 코드 생성처럼 패턴이 뚜렷한 작업에서 매우 강함 |
| LLaMA-Instruct 3.1 8B, MT-bench, temperature=0 | 3.16x | 4.40x | 대표적인 채팅 설정에서도 확실한 개선 |
| LLaMA-Instruct 3.3 70B, MT-bench, temperature=0 | 2.83x | 4.11x | 더 큰 target model에서도 이득 유지 |
| DeepSeek-R1-Distill-LLaMA 8B, GSM8K, temperature=0 | 3.40x | 5.01x | 추론형 모델에서도 큰 개선 |
평균적으로 보면, 논문은 EAGLE-3가 기존 EAGLE-2 대비 대략 20%에서 40% 수준의 추가 개선을 보인다고 정리한다.
왜 이 개선이 실제로 먹히는가
속도 향상은 결국 "나중 단계 초안도 얼마나 덜 무너지느냐"로 설명된다.
첫 토큰만 잘 맞히는 것은 충분하지 않다.
중간부터 draft model의 자기 예측이 입력에 섞여도 acceptance가 버텨야 한다.
이 지점에서 EAGLE-3는 기존 EAGLE과 꽤 다르게 움직인다.
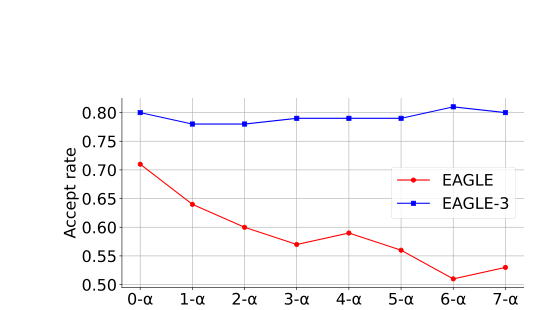
주목 포인트: 빨간 선과 파란 선의 간격입니다. 자기 예측이 입력에 더 많이 섞여도 EAGLE-3의 acceptance는 거의 평평하게 유지됩니다.
이 그림은 training-time test의 가치를 가장 직관적으로 보여준다.
EAGLE은 자기 예측이 누적될수록 acceptance가 빠르게 떨어진다.
반면 EAGLE-3는 같은 상황에서도 비교적 안정적이다.
즉, 초안 생성이 한 단계짜리 요행이 아니라 여러 단계를 버틸 수 있는 구조가 된 것이다.
서비스 관점에서 왜 의미가 큰가
speculative sampling은 자주 이런 비판을 받는다.
"batch가 커지면 오히려 throughput이 나빠지는 것 아닌가?"
논문은 이 지점도 확인한다.
SGLang 실험에서 EAGLE-3는 LLaMA-Instruct 3.1 8B 기준으로 다음과 같은 개선을 보였다.
- batch size 2: 1.81x
- batch size 16: 1.48x
- batch size 64: 1.38x
반면 같은 조건에서 EAGLE은 batch size 24 부근부터 1.0x 아래로 내려가는 구간이 나온다.
즉, EAGLE-3는 작은 배치에서만 빠른 트릭이 아니라, 실제 serving 환경에서도 상대적으로 오래 이득을 유지한다.
vLLM 실험도 같은 방향을 보여 준다.
논문 본문과 표 캡션 사이에 GPU 표기가 완전히 일치하지 않는 대목은 있지만, 큰 배치로 갈수록 EAGLE보다 EAGLE-3가 더 늦게 성능 이득을 잃는다는 메시지는 분명하다.
이 논문이 던지는 더 큰 메시지
이 논문의 가장 흥미로운 점은 개별 기법 하나보다도 시각의 전환이다.
보통 추론 가속은 런타임 엔지니어링 문제처럼 여겨진다.
하지만 EAGLE-3는 그 일부가 학습 문제이기도 하다고 주장한다.
- draft model의 학습 목표를 어떻게 잡을지
- 훈련과 추론의 입력 차이를 어떻게 줄일지
- 어떤 층의 정보를 가져다 쓸지
이 설계가 맞으면, 학습 데이터를 더 넣는 것 자체가 추론 속도 개선으로 이어질 수 있다.
논문이 말하는 "inference acceleration의 scaling law"는 바로 이 지점에 있다.
한계도 분명하다
좋은 결과와 별개로, 바로 실무에 가져갈 때는 몇 가지를 생각해야 한다.
- 405B, 671B 같은 초대형 모델 실험은 GPU 제약 때문에 하지 못했다.
- 별도 draft model 학습이 필요하다.
- serving framework와의 통합 비용이 있다.
- 작업 종류에 따라 이득 폭이 다르다. 코드 생성과 수학 추론은 특히 잘 맞지만, 모든 시나리오가 똑같지는 않다.
- 논문은 lossless acceleration을 전제로 하므로 품질 열화를 따로 평가하지 않는다. 대신 acceptance와 speedup으로 효과를 본다.
정리
EAGLE-3는 기존 EAGLE 계열의 핵심 병목을 정확히 짚는다.
문제는 "draft model이 작은가"가 아니었다.
더 정확히는, draft model을 무엇에 맞춰 학습시켰는가가 문제였다.
이 논문은 그 제약을 걷어내고, 훈련 단계부터 실제 추론 상황을 흉내 내게 만들었다.
그 결과는 분명하다.
- 더 많은 데이터가 실제 속도 향상으로 연결된다.
- 뒤쪽 초안 토큰의 acceptance가 덜 무너진다.
- 대형 모델과 serving framework에서도 개선이 유지된다.
LLM 추론 가속을 "런타임 최적화"만이 아니라 "학습 가능한 성질"로 다시 보게 만드는 논문이라고 볼 수 있다.
Source
- Yuhui Li, Fangyun Wei, Chao Zhang, Hongyang Zhang, EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test, arXiv, 2025.
- Paper: https://arxiv.org/abs/2503.01840
- PDF: https://arxiv.org/pdf/2503.01840
- Code: https://github.com/SafeAILab/EAGLE
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| PaperOrchestra 논문 정리 (0) | 2026.04.10 |
|---|---|
| DFlash: Block Diffusion for Flash Speculative Decoding 논문 정리 (0) | 2026.04.09 |
| In-Place Test-Time Training 논문 정리 (0) | 2026.04.09 |
| LLM-based Multi-Agent Blackboard System for Information Discovery in Data Science 정리 (0) | 2026.04.09 |
| SHINE: 하이퍼네트워크 정리 (0) | 2026.04.07 |



