한눈에 보기
- 이 논문은 LLM이 추론 중에도 일부 가중치를 바로 업데이트하게 만든다.
- 새 레이어를 억지로 추가하지 않는다.
대신 기존 MLP의 마지막 투영층을 빠르게 바뀌는 메모리로 재해석한다. - 핵심은 단순 복원이 아니다.
"지금 본 토큰"이 아니라 "다음 예측에 도움 되는 정보"를 저장하게 만든다. - 그래서 긴 문맥이 들어올수록 이점이 커진다.
왜 이런 시도가 필요한가
지금의 LLM은 대체로 학습한 뒤 배포하고, 배포 뒤에는 고정된다.
이 구조는 단순하고 강력하다.
하지만 한계도 분명하다.
- 새로운 정보가 길게 이어져 들어와도, 모델의 본체 가중치는 그대로다.
- 결국 적응은 대부분 컨텍스트 창 안에 토큰을 더 쌓는 방식에 의존한다.
- 그런데 컨텍스트가 길어질수록 attention 비용은 빠르게 커진다.
- 즉, 길어진 입력을 "읽는 것"과 그 안에서 "배우는 것"이 같은 문제가 아니게 된다.
이 논문은 여기서 출발한다.
입력을 더 오래 들고 있는 것만으로는 부족하니,
추론 도중에도 작은 메모리를 계속 갱신하게 만들자는 것이다.
기존 TTT가 LLM에 바로 붙기 어려웠던 이유
논문이 짚는 병목은 세 가지다.
- 아키텍처 호환성 부족
기존 TTT는 attention을 대체하는 별도 구조로 제안되는 경우가 많았다.
그러면 이미 잘 학습된 거대 LLM에 바로 붙이기 어렵다. - 계산 효율 문제
토큰마다 순차적으로 업데이트하면 GPU 병렬성이 크게 죽는다. - 목표 함수의 미스매치
기존 TTT는 보통 현재 토큰 표현을 복원하는 데 초점을 둔다.
하지만 언어모델의 진짜 목표는 다음 토큰 예측이다.
이 논문은 세 문제를 한 번에 묶어서 푼다.
핵심 아이디어 1: MLP를 그대로 적응 메모리로 쓴다
가장 중요한 설계는 여기다.
Transformer의 MLP는 원래도 사전학습 중 얻은 지식을 담고 있다.
저자들은 이 블록을 아예 버리거나 바꾸지 않는다.
대신 MLP의 마지막 투영층만 빠르게 바뀌는 가중치로 사용한다.
의미는 명확하다.
- attention은 그대로 둔다.
- MLP 앞단은 그대로 둔다.
- 마지막 투영층만 문맥을 보면서 즉석에서 조정한다.
그래서 이 방식은 기존 LLM을 크게 망가뜨리지 않으면서 붙일 수 있는 drop-in 강화에 가깝다.
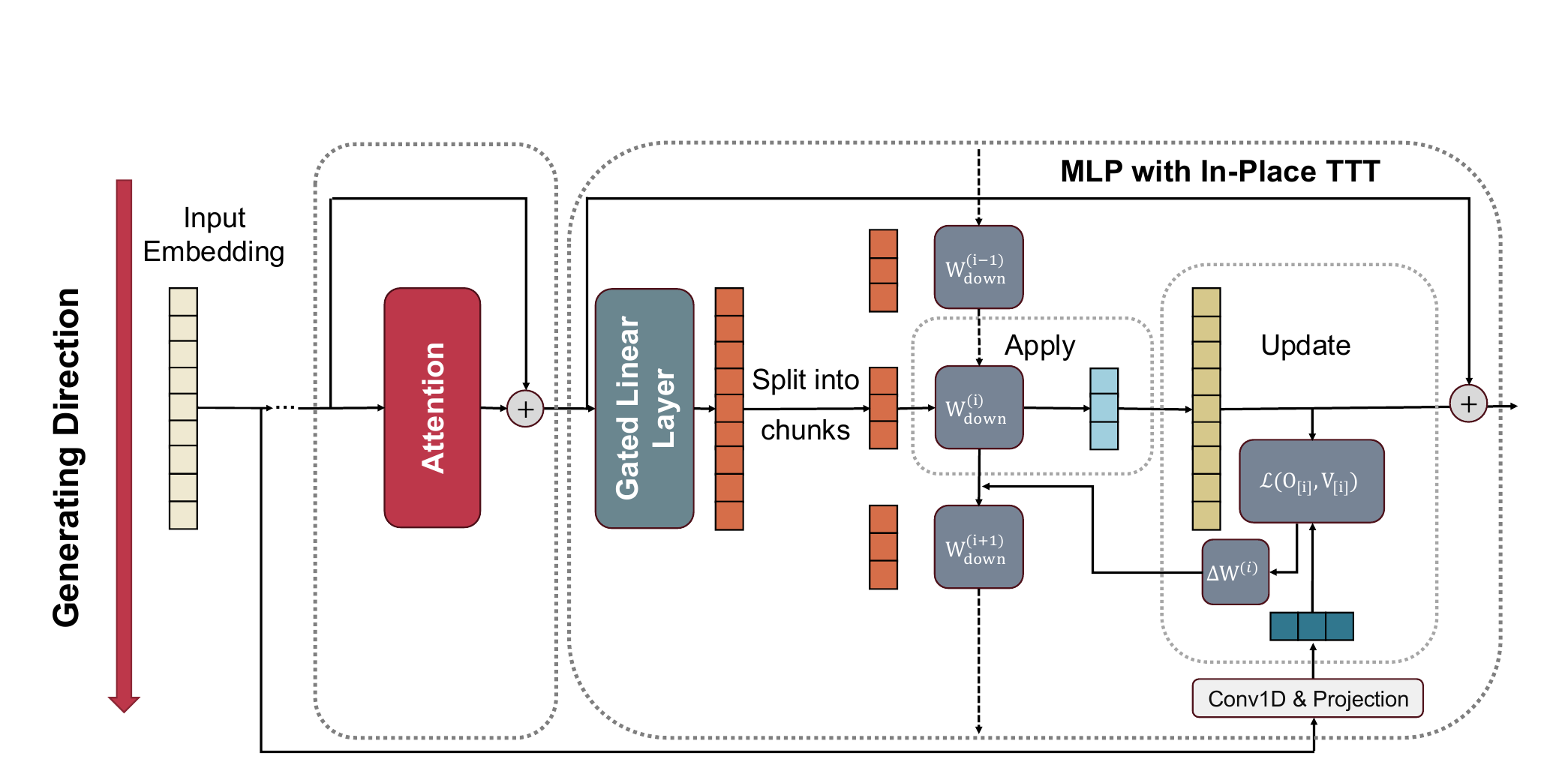
Crop 포인트: 가운데의
Apply -> Update흐름이 핵심입니다. 같은 MLP 안에서 출력을 만들고, 바로 그 문맥으로 메모리를 갱신하는 사이클이 완성됩니다.
이 그림이 말하는 바는 단순하다.
모델은 먼저 현재 상태의 MLP로 출력을 만든다.
그 다음 방금 본 문맥을 이용해 그 MLP의 일부를 조금 바꾼다.
즉, 추론과 적응이 같은 전진 과정 안에서 일어난다.
핵심 아이디어 2: 토큰마다가 아니라 chunk 단위로 반응한다
TTT의 고전적인 문제는 너무 순차적이라는 점이다.
토큰 하나를 볼 때마다 업데이트하면,
이론적으로는 섬세하지만 실제 시스템에서는 느리다.
이 논문은 입력을 여러 chunk로 나눈다.
그리고 각 chunk에 대해 두 단계를 반복한다.
- 현재 메모리 상태로 출력을 만든다.
- 그 chunk를 보고 메모리를 한 번 업데이트한다.
여기서 중요한 점이 있다.
기존 TTT 계열은 종종 TTT 자체가 주된 토큰 혼합기 역할을 맡았다.
그래서 chunk를 너무 크게 잡기 어려웠다.
반면 이 논문은 attention을 그대로 살려 둔다.
즉, 문맥 섞기는 attention이 담당하고,
TTT는 MLP를 통해 추가 적응 메모리만 얹는다.
그래서 더 큰 chunk를 써도 성능이 무너지지 않는다.
이 점이 실제 하드웨어 친화성으로 이어진다.
핵심 아이디어 3: 복원이 아니라 "다음에 필요할 정보"를 저장한다
이 논문의 차별점은 구조만이 아니다.
무엇을 저장하게 만들 것인가도 바꾼다.
기존 TTT는 보통 현재 토큰의 표현을 다시 맞추도록 학습한다.
이 방식은 "지금 본 것"을 기억하게는 한다.
하지만 언어모델 입장에서는 충분히 직접적이지 않다.
저자들은 목표를 바꾼다.
- 현재 토큰 자체를 복원하게 하지 않는다.
- 조금 앞의 미래 토큰 정보가 섞인 목표를 만든다.
- 그 목표를 향해 fast weight가 갱신되도록 한다.
직관은 이렇다.
이 메모리는 "무엇이 있었는가"보다
"이 패턴이 다시 나오면 다음에 무엇이 와야 하는가"를 더 잘 기억해야 한다.
그래서 논문은 1D convolution과 projection을 이용해
짧은 미래 정보를 반영한 타깃을 만든다.
수식은 복잡해 보여도 뜻은 단순하다.
문맥을 압축하되, 예측에 쓸모 있는 방향으로 압축하자는 것이다.
왜 이 목표가 언어모델에 더 잘 맞는가
논문은 이 차이를 이론적으로도 설명한다.
상황을 아주 단순하게 생각해 보자.
- 앞부분에서 어떤 패턴과 그 뒤에 붙는 답이 한 번 나온다.
- 나중에 같은 패턴이 다시 나온다.
- 모델은 이번에도 그 답을 이어서 내야 한다.
이때 단순 복원 목표는
"아, 이 토큰을 본 적 있어" 수준의 기억에 머물기 쉽다.
반면 이 논문의 목표는
"이 패턴 뒤에는 보통 이 정보가 이어진다"는 방향으로 메모리를 조정한다.
즉, 반복 패턴을 봤을 때
정답 쪽 로그잇을 올리는 기억을 만들 가능성이 높다.
한마디로 정리하면 이렇다.
- 복원 목표: 현재를 닮게 저장
- LM-aligned 목표: 다음을 맞히게 저장
언어모델에게 더 자연스러운 쪽은 당연히 후자다.
실험 1: 사전학습 LLM에 바로 붙였을 때
저자들은 Qwen3-4B-Base에 In-Place TTT를 붙여서 지속 학습을 진행했다.
평가는 긴 문맥 활용 능력을 보는 RULER 벤치마크로 했다.
결과의 포인트는 명확하다.
- 짧은 구간에서는 큰 차이가 없다.
- 문맥이 길어질수록 격차가 벌어진다.
대표 수치만 보면:
- 64k: 74.3 -> 78.7
- 128k: 74.8 -> 77.0
- 256k 외삽: 41.7 -> 43.9
즉, 이 방식의 장점은 초반보다 긴 구간에서 더 분명하게 드러난다.
확장성도 확인했다.
- LLaMA-3.1-8B: 64k에서 81.6 -> 83.7
- Qwen3-14B-Base: 64k에서 67.9 -> 70.6
- YaRN과 함께 썼을 때도 개선이 유지된다.
이 대목이 실무적으로 중요하다.
새 구조를 처음부터 끝까지 다시 학습하지 않고도,
기존 공개 LLM에 적응 메모리를 얹을 수 있다는 뜻이기 때문이다.
실험 2: 처음부터 학습해도 강한가
논문은 여기서 멈추지 않는다.
500M, 1.5B, 4B 규모에서도 처음부터 학습해 비교한다.
비교 대상은 SWA, GLA, DeltaNet, LaCT 같은 경쟁 방법들이다.
여기서 봐야 할 지표는 perplexity다.
쉽게 말해, 모델이 다음 토큰을 얼마나 덜 헷갈리는지를 보는 값이다.
낮을수록 좋다.
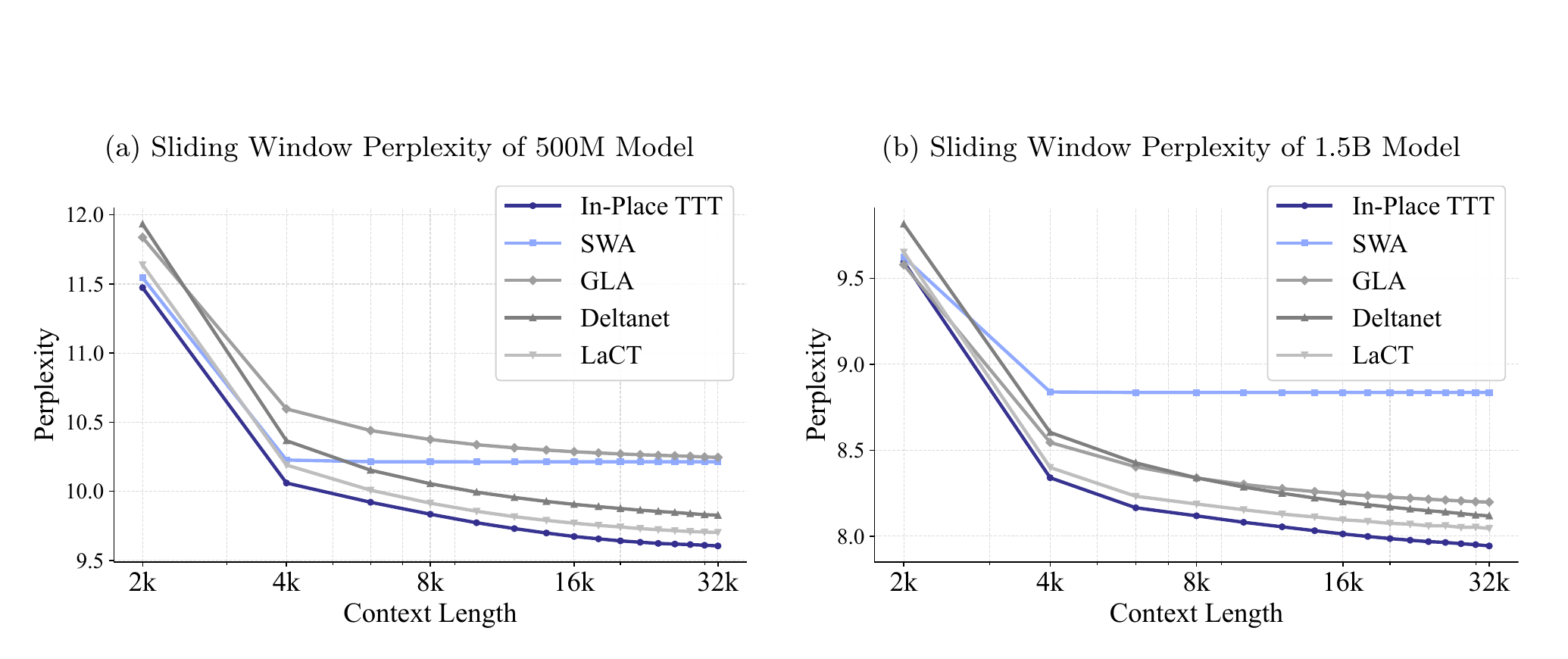
Crop 포인트: 문맥이 길어질수록 가장 아래로 내려가는 선이 In-Place TTT입니다. 긴 문맥을 실제로 더 잘 활용할수록 perplexity가 계속 내려갑니다.
그림이 보여 주는 메시지는 단순하다.
컨텍스트가 32k까지 길어져도 In-Place TTT는 꾸준히 더 낮은 perplexity를 유지한다.
4B 실험도 인상적이다.
- Full Attention 4B에서 RULER-16k: 6.58 -> 19.99
- SWA 4B에서 RULER-8k: 9.91 -> 26.80
상식 추론 계열 벤치마크도 대체로 유지되거나 소폭 좋아진다.
즉, 긴 문맥 능력을 얻는 대신 일반 성능을 크게 희생하는 그림은 아니다.
실험 3: 무엇이 성능을 갈랐나
이 논문은 설계 선택도 꽤 꼼꼼하게 분해해서 본다.
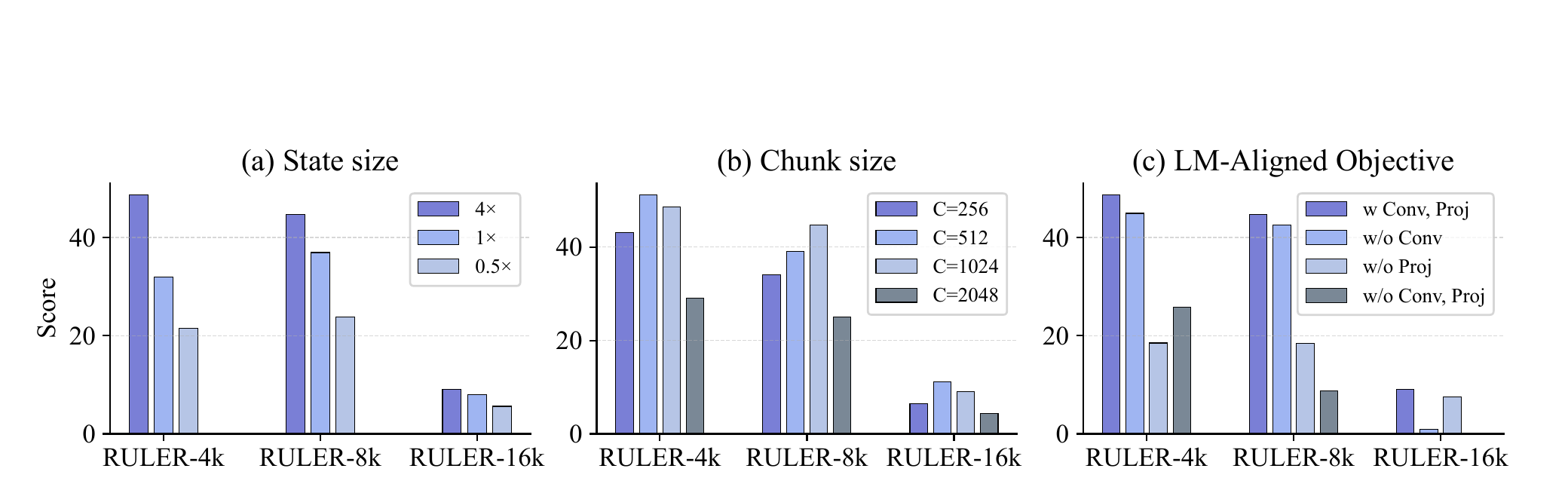
Crop 포인트: 가운데 패널에서 chunk 512~1024가 가장 균형이 좋고, 오른쪽 패널에서 Conv1D와 Projection을 함께 쓸 때 성능이 가장 안정적으로 높습니다.
핵심만 정리하면 다음과 같다.
- State size가 클수록 성능이 오른다.
즉, 적응 가능한 MLP 상태를 더 넓게 쓰는 것이 실제로 도움이 된다. - Chunk size는 너무 작아도, 너무 커도 아쉽다.
논문에서는 512와 1024가 가장 좋았고,
특히 1024가 효율 면에서도 유리했다. - LM-aligned objective의 두 부품이 모두 중요하다.
미래 정보를 섞는 convolution은 긴 문맥에서 특히 중요했고,
projection은 짧은 문맥에서도 성능을 받쳐 줬다.
이 결과는 논문의 주장을 다시 확인해 준다.
성능 향상은 단순히 "업데이트를 한 번 더 했다"에서 오지 않는다.
어디를 업데이트하고, 무엇을 목표로 저장하게 했는가가 핵심이다.
효율 비용은 얼마나 드나
긴 문맥에서 성능이 좋아도,
처리량과 메모리 비용이 너무 늘면 실전성이 떨어진다.
논문은 이 부분도 별도로 측정했다.
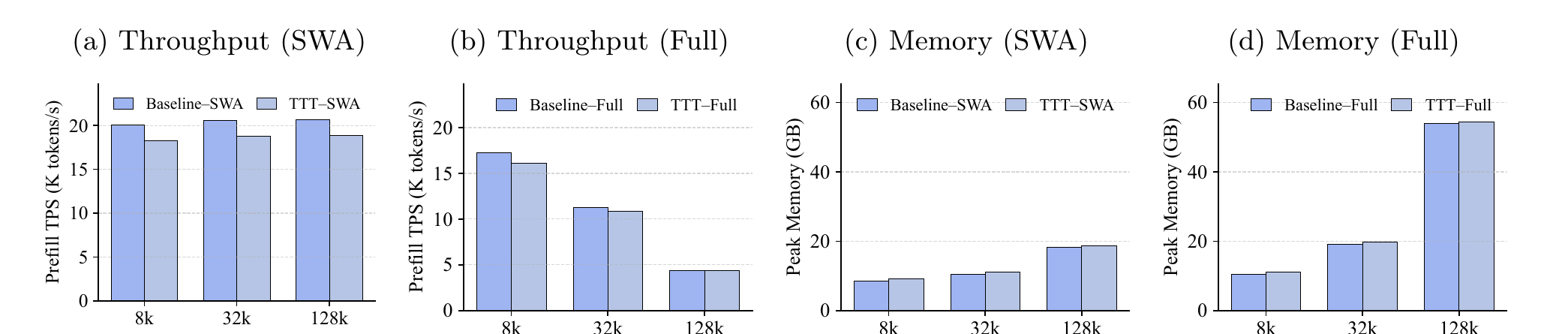
Crop 포인트: 각 막대쌍의 차이가 크지 않다는 점입니다. 성능 이득에 비해 처리량 감소와 메모리 증가가 제한적이라는 메시지입니다.
핵심 해석은 간단하다.
- Sliding Window Attention 환경에서도
- Full Attention 환경에서도
- prefill throughput과 peak memory의 차이가 아주 크지 않다.
즉, 이 방식은 성능 아이디어에만 그치지 않고 시스템 관점에서도 현실성을 확보하려고 했다.
이 논문이 특히 좋은 이유
이 논문이 눈에 띄는 이유는 "메모리를 추가했다"가 아니다.
기존 LLM 생태계에 들어갈 수 있는 방식으로 설계했다는 점이 더 중요하다.
좋은 점을 정리하면:
- attention을 대체하지 않는다.
그래서 기존 LLM의 강점을 보존하기 쉽다. - MLP를 재활용한다.
그래서 구조 변경이 비교적 작다. - 목표 함수가 언어모델과 직접 연결된다.
"다음 토큰 예측"과 더 가까운 적응이 가능하다. - 큰 chunk와 context parallelism을 지원한다.
그래서 이론보다 구현이 먼저 무너지는 문제를 줄인다.
남는 한계와 질문
물론 아직 열린 문제도 있다.
- 실험의 중심은 여전히 언어모델링과 long-context 벤치마크다.
진짜 온라인 학습, 에이전트형 장기 작업, 지속적 세계지식 업데이트까지 바로 입증한 것은 아니다. - "drop-in"이라고 해도 지속 학습 비용이 완전히 사라지는 것은 아니다.
그냥 붙이고 바로 끝나는 수준은 아니다. - fast weight는 문서 경계에서 리셋된다.
즉, 세션을 넘는 장기 기억까지 다루는 방식은 아니다. - 안전성 측면에서도 질문이 남는다.
추론 중 가중치가 바뀌는 구조는, 잘못된 문맥이나 공격적 입력에 어떻게 반응할지 더 많은 검증이 필요하다.
결론
이 논문은 TTT를 거대한 새 아키텍처로 밀어붙이지 않는다.
대신 LLM 안에 이미 있는 MLP를 적응 메모리로 다시 해석한다.
이 선택이 좋다.
구조 변화는 작다.
목표는 언어모델에 맞다.
긴 문맥에서 성능 이득도 분명하다.
효율도 꽤 현실적이다.
결국 이 논문의 메시지는 선명하다.
긴 문맥 시대의 LLM은 더 많은 토큰만 읽는 것으로는 부족하다.
읽으면서, 아주 조금씩 내부를 바꿀 수 있어야 한다.
In-Place TTT는 그 방향으로 가는 꽤 실용적인 첫걸음에 가깝다.
Source
- Guhao Feng, Shengjie Luo, Kai Hua, Ge Zhang, Di He, Wenhao Huang, Tianle Cai. In-Place Test-Time Training. arXiv:2604.06169v1, April 2026.
- Paper: https://arxiv.org/abs/2604.06169
- PDF: https://arxiv.org/pdf/2604.06169
- Code: https://github.com/ByteDance-Seed/In-Place-TTT
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| DFlash: Block Diffusion for Flash Speculative Decoding 논문 정리 (0) | 2026.04.09 |
|---|---|
| EAGLE-3 논문 정리 (0) | 2026.04.09 |
| LLM-based Multi-Agent Blackboard System for Information Discovery in Data Science 정리 (0) | 2026.04.09 |
| SHINE: 하이퍼네트워크 정리 (0) | 2026.04.07 |
| Enhancing Retrieval-Augmented Generation: A Study of Best Practices 논문 정리 (0) | 2026.04.07 |



