한눈에 보기
- 이 논문은 LLM 추론의 가장 큰 병목인 순차 디코딩을 정면으로 다룹니다.
- 핵심 질문은 단순합니다.
초안 생성도 병렬로 만들 수 없을까? - 저자들은 그 답으로 block diffusion drafter를 제안합니다.
- 중요한 점은 diffusion 모델을 최종 생성기로 쓰지 않았다는 것입니다.
대신 빠른 초안 생성기로만 쓰고, 최종 품질은 큰 target model이 검증합니다. - 그래서 결과는 lossless acceleration입니다.
빠르지만, 최종 출력은 기존 target model의 검증을 통과한 토큰만 남습니다.
논문의 한 줄 요약은 이렇습니다.
작은 diffusion 모델이 혼자 맞히게 하지 말고, 큰 target model이 이미 알고 있는 문맥 힌트를 받아 한 번에 여러 토큰을 초안으로 내게 하자.
그 결과는 꽤 강합니다.
Qwen3-8B 기준으로 여러 벤치마크에서 최대 6.08배 가속을 기록했고, 기존 대표 기법인 EAGLE-3보다 대체로 훨씬 큰 속도 이득을 냈습니다.

Crop 포인트: 파란 막대와 초록 막대의 간격이 핵심입니다. 같은 품질을 유지한 상태에서 DFlash가 기존 speculative decoding보다 실제 속도 이득을 얼마나 더 크게 벌렸는지 바로 드러납니다.
왜 기존 speculative decoding도 한계가 있었나
speculative decoding은 기본적으로 좋은 아이디어입니다.
작은 draft model이 다음 토큰들을 먼저 제안합니다.
큰 target model은 그 제안을 한 번에 확인합니다.
맞은 토큰은 통과시키고, 틀린 지점부터 다시 큰 모델이 이어서 생성합니다.
문제는 draft 단계 자체가 또 순차적이었다는 점입니다.
최신 방법도 초안 토큰을 여러 개 만들 때, 실제로는 한 칸씩 차례대로 예측하는 경우가 많았습니다.
그러면 초안 길이를 늘릴수록 draft 비용도 같이 늘어납니다.
이 구조에서는 두 가지가 동시에 생깁니다.
- draft model을 아주 얕고 작게 유지해야 합니다.
- 그러면 초안 품질이 충분히 올라가지 못합니다.
- 초안 길이를 길게 잡아도 실제로 많이 통과되지 않습니다.
- 결국 속도 향상 폭이 일찍 포화됩니다.
diffusion 계열 모델은 여기서 다른 선택지를 줍니다.
빈칸이 많은 짧은 구간을 한 번에 채울 수 있기 때문입니다.
하지만 diffusion LLM을 그대로 최종 생성기로 쓰면 품질과 속도 사이의 타협이 다시 생깁니다.
품질을 유지하려면 여러 번 다듬는 단계가 필요하고, 그러면 생각보다 빨라지지 않습니다.
이 논문은 바로 그 틈을 찌릅니다.
diffusion은 최종 답안을 쓰게 하지 말고, 빠른 초안만 쓰게 하자.
그리고 최종 품질은 autoregressive target model이 보증하게 하자는 발상입니다.

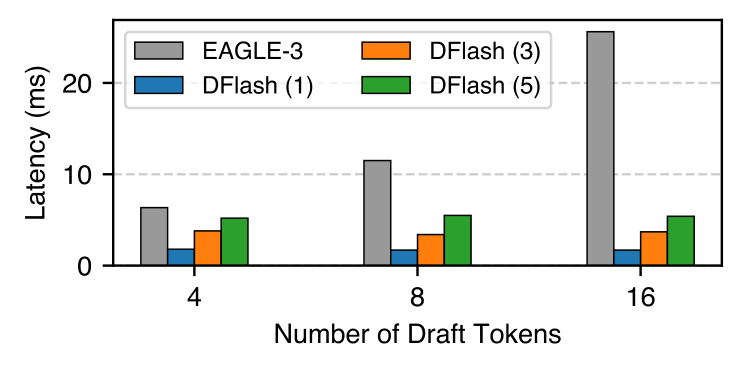
Crop 포인트: 오른쪽으로 갈수록 회색 막대는 급격히 커지지만 DFlash 막대는 완만합니다. 초안 토큰 수가 늘어날 때 병목이 어디서 생기는지, 그리고 DFlash가 왜 더 유리한지 보여줍니다.
DFlash의 핵심 아이디어
1. 작은 모델이 혼자 추측하지 않게 한다
저자들의 직관은 간단합니다.
정답에 가장 가까운 쪽은 결국 target model이라는 것입니다.
큰 autoregressive 모델의 내부 표현에는 단순한 다음 토큰 확률 이상이 들어 있습니다.
문맥의 구조, 의미, 그리고 가까운 미래 토큰에 대한 힌트까지 담겨 있습니다.
DFlash는 이 숨은 표현을 여러 층에서 뽑아 합친 뒤, draft model이 참고할 수 있는 압축된 문맥 신호로 만듭니다.
즉, 작은 diffusion drafter가 처음부터 스스로 추론하는 것이 아닙니다.
이미 강한 이해력을 가진 target model의 내부 힌트를 받아서 병렬 초안 작성만 담당합니다.
2. 힌트를 입력에서 한 번만 주지 않는다
기존 계열 기법도 target model의 feature를 쓰긴 합니다.
하지만 입력 쪽에 한 번 섞어 넣는 방식에 가깝습니다.
이 경우 draft model이 깊어질수록 그 정보가 희미해질 수 있습니다.
DFlash는 더 직접적입니다.
압축된 문맥 힌트를 draft model 각 층이 계속 참조하는 메모리처럼 넣습니다.
덕분에 모델이 조금 더 깊어져도 조건 정보가 덜 흐려집니다.
논문이 보여주는 핵심은 여기입니다.
깊이를 늘렸을 때 초안 통과 길이가 실제로 더 잘 늘어납니다.
3. 다음 구간을 한 번에 쓴다
DFlash는 다음 토큰들을 나무처럼 한 칸씩 뻗어나가며 쓰지 않습니다.
대신 짧은 블록 안에서 비어 있는 위치들을 한 번에 채웁니다.
이 병렬성이 GPU에 잘 맞습니다.
그래서 같은 크기의 작은 모델이라도, 여러 번 순차 호출하는 방식보다 실제 draft 시간이 훨씬 낮아집니다.
정리하면 DFlash는 두 가지를 동시에 얻습니다.
- target model의 문맥 이해력
- diffusion의 병렬 초안 생성 속도
Crop 포인트: 왼쪽의 target feature가 가운데 draft layer들로 계속 흘러 들어가는 연결부를 보면 됩니다. DFlash의 속도와 정확도를 동시에 만드는 설계 핵심이 바로 그 지점입니다.
학습 방식도 추론 시나리오에 맞춰 바꿨다
이 논문의 강점은 추론 설계만이 아닙니다.
학습 과정도 실제 speculative decoding 흐름에 맞게 바꿨습니다.
anchor token 기준으로 블록을 만든다
일반적인 block diffusion 학습은 응답을 균등하게 자른 뒤 일부를 가리는 식입니다.
DFlash는 더 실전적입니다.
응답 안에서 깨끗한 토큰 하나를 anchor로 잡고, 그 뒤의 위치들을 가린 채 한 번에 맞히도록 학습합니다.
이 설계가 중요한 이유는 실제 추론과 닮아 있기 때문입니다.
speculative decoding에서는 직전 검증 단계에서 이미 확정된 토큰을 기준으로 다음 블록을 초안 생성합니다.
DFlash는 학습에서도 같은 상황을 반복해서 보게 만듭니다.
블록을 무작위로 뽑아 데이터 효율을 높인다
anchor 위치를 매번 바꾸면 같은 데이터에서도 더 다양한 문맥 조건을 볼 수 있습니다.
논문은 이 무작위 샘플링이 초안 통과 길이와 속도 모두에 도움이 된다고 보고합니다.
여러 블록을 한 번에 학습하되, 블록끼리 새지 않게 막는다
학습 중에는 여러 draft block을 한 시퀀스로 묶어 같이 처리합니다.
대신 attention mask를 조절해서 같은 블록 안에서는 서로 보되, 다른 블록 정보는 못 보게 합니다.
그래서 병렬 학습 효율은 챙기고, 추론 시의 인과 구조도 어기지 않습니다.

Crop 포인트: 노란 anchor 뒤에 초록 mask가 붙는 패턴을 보면 됩니다. DFlash가 “확정된 한 토큰을 기준으로 다음 구간을 병렬 예측한다”는 학습 의도가 그대로 드러납니다.
앞쪽 토큰을 더 중요하게 가르친다
블록 초반에서 틀리면 뒤쪽 토큰은 통째로 의미가 약해집니다.
그래서 DFlash는 블록 앞부분 예측에 더 큰 학습 비중을 둡니다.
이 선택은 직관적입니다.
실전에서는 첫 몇 칸을 맞히는 능력이 전체 초안 통과 길이를 좌우하기 때문입니다.
임베딩과 출력 헤드는 공유한다
draft model은 token embedding과 LM head를 target model과 공유하고, 그 부분은 고정합니다.
학습해야 할 파라미터 수를 줄이고, draft model이 target 표현 공간에 더 가깝게 붙도록 만들기 위한 선택입니다.
실험에서 무엇을 보여줬나
1. Qwen3 Instruct 계열에서 일관되게 앞섰다
논문은 Qwen3 4B, 8B 모델에서 수학, 코드, 대화 벤치마크를 폭넓게 평가했습니다.
핵심 결과는 명확합니다.
- greedy decoding에서는 평균적으로 대략 4.9배 수준의 가속을 달성했습니다.
- sampling이 들어가는 설정에서도 평균적으로 4배 안팎의 가속을 유지했습니다.
- 같은 조건의 EAGLE-3보다 대체로 2배 이상 큰 속도 향상을 냈습니다.
- verification 비용이 더 큰 큰 tree 설정의 EAGLE-3와 비교해도 DFlash가 더 강한 경우가 많았습니다.
즉, DFlash는 "이론상 빠를 수 있다" 수준이 아닙니다.
실제 benchmark 전반에서 일관되게 우위가 나옵니다.
2. reasoning 모델에서도 효과가 유지됐다
thinking mode가 켜진 Qwen3 설정에서도 성능이 유지됩니다.
논문은 reasoning trace가 있는 출력에서도 대략 4배 전후의 가속을 보고합니다.
이 지점은 실무적으로 특히 중요합니다.
긴 추론 체인을 쓰는 모델일수록 생성 시간이 길어집니다.
따라서 초안 생성 가속의 체감 이득도 더 커집니다.
3. 실제 serving 환경에서도 통했다
저자들은 SGLang 환경에서도 실험했습니다.
단순한 연구용 루프가 아니라, 실제 서빙 프레임워크에서 throughput을 봤다는 의미입니다.
여기서도 DFlash는 동시성 수준이 올라가도 속도 이득을 유지했습니다.
- Qwen3-8B에서는 최대 5.1배 수준의 가속을 기록했습니다.
- Qwen3-Coder-30B-A3B-Instruct에서도 코드 작업에서 2배대 후반에서 3배대 개선이 나왔습니다.
- 동시성이 커질수록 절대 속도 이득은 줄어들 수 있지만, 전반적으로 여전히 의미 있는 개선이 남았습니다.
4. LLaMA-3.1-8B-Instruct에서도 우위였다
DFlash는 Qwen 계열에만 맞춘 트릭이 아니었습니다.
LLaMA-3.1-8B-Instruct에서도 공식 EAGLE-3 체크포인트보다 더 나은 속도 향상을 보였습니다.
수학, 코드, 채팅 태스크 전반에서 비슷한 경향이 반복됐습니다.
아블레이션이 말해주는 핵심
이 논문은 왜 빨라졌는지를 비교적 투명하게 보여줍니다.
- target feature 없이 diffusion drafter만 쓰면 속도 향상은 대체로 2배에서 3배 수준에 머뭅니다.
- draft layer를 깊게 하면 통과 길이는 늘어납니다.
- 하지만 너무 깊으면 draft 자체가 무거워집니다.
- 이 균형점에서 논문은 5-layer 설정이 가장 좋은 평균 속도 향상을 보였다고 정리합니다.
- target model에서 가져오는 hidden feature를 더 많이 쓰면 통과 길이가 좋아집니다.
- 큰 block size로 학습한 모델은 더 작은 block size 추론에도 비교적 잘 적응합니다.
- anchor를 무작위 샘플링하는 학습 전략도 실제로 성능을 올립니다.
그리고 앞서 언급한 앞부분 토큰 가중 학습도 의미가 있었습니다.
초기 epoch부터 더 빨리 수렴하고, 최종 통과 길이도 더 좋았습니다.

Crop 포인트: 초반 epoch에서 파란 선이 더 빨리 올라가는 부분이 핵심입니다. 블록 앞쪽 토큰에 더 큰 비중을 두는 학습이 실제 수렴 속도와 최종 품질에 모두 도움이 됐음을 보여줍니다.
이 논문이 중요한 이유
이 논문이 흥미로운 이유는 단순히 "더 빨랐다"에만 있지 않습니다.
diffusion LLM의 역할을 다시 정의했다는 점이 더 중요합니다.
기존에는 diffusion LLM을 autoregressive LLM의 대체재로 보려는 시선이 강했습니다.
하지만 이 논문은 방향을 바꿉니다.
- diffusion은 최종 생성기가 아니라 고속 drafter로 쓰자.
- 품질 보증은 target model의 검증 단계가 맡자.
- 그러면 diffusion의 약점은 숨기고, 병렬성이라는 장점만 실전적으로 쓸 수 있다.
이 관점은 꽤 설득력이 있습니다.
standalone generation에서는 약점이 되던 부분이, speculative decoding 안에서는 훨씬 덜 치명적이기 때문입니다.
초안이 완벽할 필요는 없습니다.
충분히 자주 맞고, 충분히 싸게 많이 내면 됩니다.
한계와 읽을 때 체크할 점
좋은 결과에도 불구하고 몇 가지는 분명히 봐야 합니다.
- 비교 대상 중 일부 diffusion 기반 speculative decoding 방법은 오픈소스 구현 부재로 직접 비교되지 않았습니다.
- 이 방식은 target model의 hidden feature를 여러 층에서 뽑아 써야 하므로, 서빙 통합 난도가 낮지는 않습니다.
- offline 학습에서는 cached hidden feature 저장 비용이 feature 개수에 비례해 커집니다.
- block size는 무조건 클수록 좋은 것이 아닙니다.
큰 block은 특정 서빙 조건에서는 verification 비용을 키울 수 있습니다. - 실험은 주로 H200, B200, Transformers, SGLang 같은 특정 스택에서 수행됐기 때문에, 재현 시 시스템 조건 차이를 봐야 합니다.
즉, DFlash는 매우 유망하지만, 그냥 드롭인 한 줄 교체라고 보기는 어렵습니다.
대신 모델 내부 feature를 활용하는 병렬 drafter 설계라는 방향 자체는 앞으로도 확장 가능성이 큽니다.
정리
DFlash의 메시지는 분명합니다.
LLM 추론 가속의 병목은 "검증"만이 아니라 "초안 생성"에도 있었습니다.
그리고 그 초안 생성을 순차 방식에서 병렬 방식으로 바꾸면 속도 상한이 크게 올라갑니다.
여기에 target model의 내부 문맥 힌트를 깊게 주입하자, 작은 diffusion drafter가 예상보다 훨씬 정확한 초안을 만들 수 있었습니다.
그래서 DFlash는 diffusion과 autoregressive 모델을 경쟁시키지 않습니다.
둘의 역할을 분리하고, 각자의 강점만 실전에 맞게 조합합니다.
긴 추론을 자주 요구하는 최신 LLM 환경에서는 이런 발상이 더 중요해질 가능성이 큽니다.
이 논문은 diffusion LLM의 실전 위치를 다시 생각하게 만드는 사례입니다.
Source
- Jian Chen, Yesheng Liang, Zhijian Liu, DFlash: Block Diffusion for Flash Speculative Decoding, preprint, February 6, 2026.
- arXiv: https://arxiv.org/abs/2602.06036
- Project page: https://z-lab.ai/projects/dflash
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| MegaTrain 논문 정리 (1) | 2026.04.10 |
|---|---|
| PaperOrchestra 논문 정리 (0) | 2026.04.10 |
| EAGLE-3 논문 정리 (0) | 2026.04.09 |
| In-Place Test-Time Training 논문 정리 (0) | 2026.04.09 |
| LLM-based Multi-Agent Blackboard System for Information Discovery in Data Science 정리 (0) | 2026.04.09 |



