한눈에 보기
- 이 논문은 연구 메모와 실험 로그를 학회 제출용 논문으로 바꾸는 일을 별도 문제로 다룹니다.
- 핵심 주장은 단순합니다. 좋은 논문 쓰기는 한 번에 끝나는 생성 문제가 아니라, 계획-탐색-작성-정제의 파이프라인 문제라는 것입니다.
- 그래서 저자들은 단일 프롬프트 대신 역할이 나뉜 멀티 에이전트 시스템을 제안합니다.
- 동시에 이 과제를 제대로 재려면 벤치마크가 필요하다고 보고, PaperWritingBench도 함께 만듭니다.
왜 이 문제가 중요한가
최근 자율 연구 시스템은 아이디어를 만들고, 코드를 짜고, 실험을 돌리는 쪽으로 빠르게 발전했습니다.
그런데 실제 연구에서는 마지막 병목이 자주 남습니다.
바로 정리되지 않은 재료를 제출 가능한 원고로 바꾸는 일입니다.
짧은 아이디어 메모, 실험 로그, 학회 템플릿, 가이드라인, 그리고 몇 장의 그림만 가지고도 논문은 써져야 합니다.
문제는 여기서 끝나지 않습니다.
좋은 논문은 결과만 나열하면 되지 않습니다.
왜 이 문제가 중요한지, 이전 연구는 어디까지 왔는지, 내 방법이 어디를 넘어서려는지, 그림과 표는 어떤 메시지를 증명하는지까지 함께 설계되어야 합니다.
이 논문은 그 과정을 독립된 자동화 문제로 꺼내서 다룹니다.
이 논문의 핵심 아이디어
PaperOrchestra는 사람이 미리 정리해 둔 연구 재료를 받아, 학회 제출용 LaTeX 원고와 PDF까지 만드는 시스템입니다.
여기서 중요한 포인트는 두 가지입니다.
- 기존의 자동 논문 작성기는 대개 특정 실험 파이프라인에 강하게 묶여 있었습니다.
- 반대로 문헌 리뷰 생성기는 리뷰는 잘 써도, 실험 로그를 읽고 전체 논문 구조로 엮는 데는 약했습니다.
PaperOrchestra는 이 둘 사이를 노립니다.
즉, 연구 수행 시스템의 부산물만 받는 작성기도 아니고, 문헌 조사만 잘하는 리뷰 생성기도 아닙니다.
아이디어 설명과 실험 기록처럼 아직 거친 재료를 받아, 관련 연구 조사와 시각화 생성까지 묶어서 원고를 완성하는 쪽에 초점을 둡니다.
시스템은 어떻게 돌아가나
저자들은 이 과정을 다섯 단계로 나눕니다.
- Outline Agent가 먼저 전체 설계를 잡습니다.
어떤 그림이 필요한지, 어떤 문헌을 어떤 층위에서 찾을지, 각 섹션에 무엇을 써야 할지 먼저 정리합니다. - Plotting Agent가 그림과 플롯을 만듭니다.
단순 그래프뿐 아니라 개념도까지 생성합니다. - Literature Review Agent가 관련 논문을 찾고 검증합니다.
그냥 검색 결과를 믿지 않고, 실제 논문이 맞는지 확인하고, 인용 목록까지 정리합니다. - Section Writing Agent가 본문을 씁니다.
실험 로그에서 숫자를 뽑아 표를 만들고, 앞 단계에서 준비한 그림과 인용을 본문 안에 엮습니다. - Content Refinement Agent가 가상 리뷰어처럼 초안을 다시 깎습니다.
수정본이 실제로 더 좋아졌다고 판단될 때만 반영하고, 나빠지면 되돌립니다.
이 구조의 장점은 분명합니다.
처음부터 한 번에 잘 쓰려 하지 않고, 논문 작성에 필요한 판단을 단계별로 분리합니다.
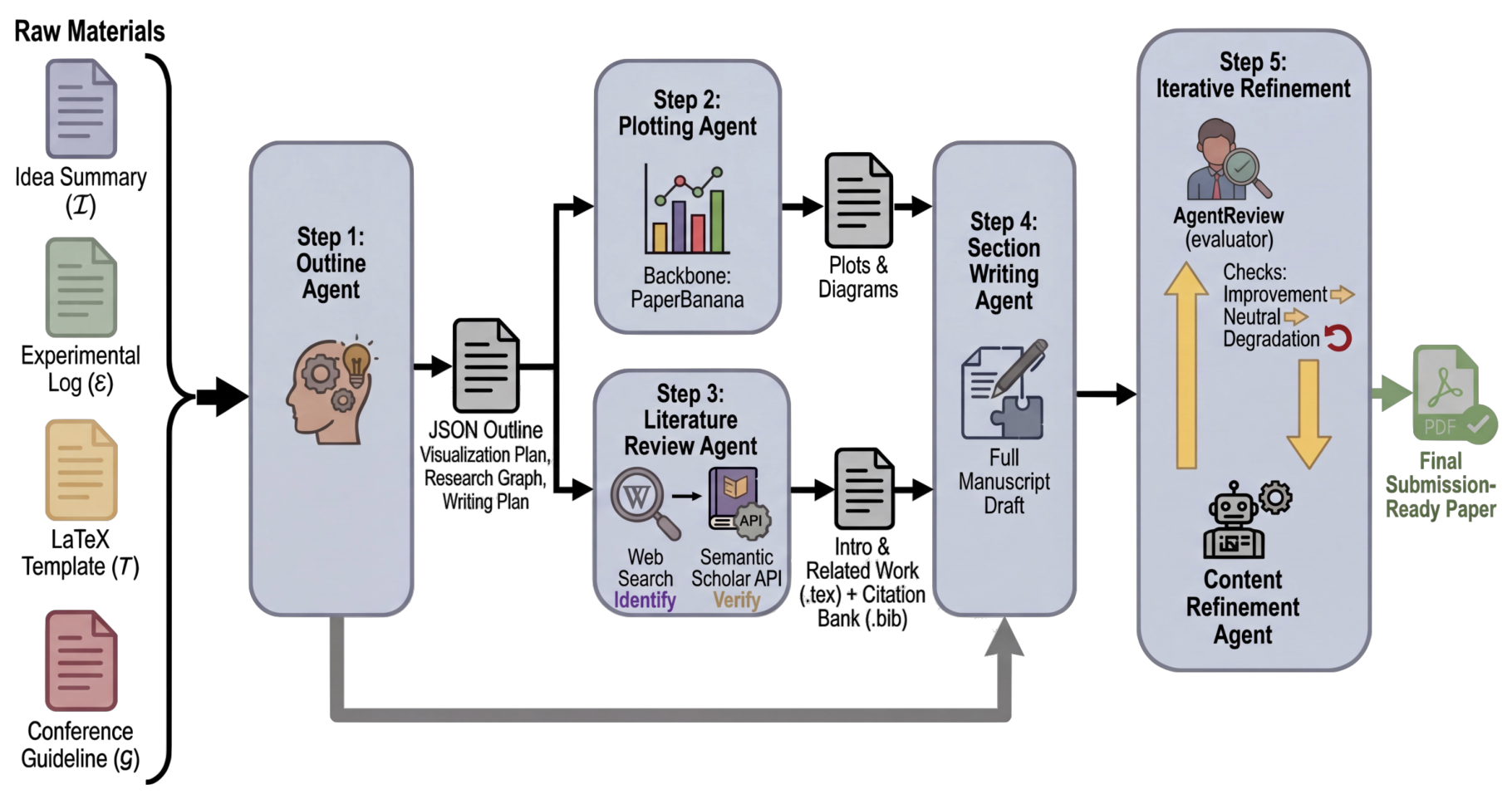
주목 포인트: 가운데에서 시각화 생성과 문헌 탐색이 병렬로 갈라지고, 마지막에 별도의 정제 루프가 붙는 점이 이 시스템의 설계 철학을 가장 잘 보여줍니다.
왜 벤치마크까지 함께 만들었나
저자들은 시스템만 내놓지 않았습니다.
함께 제안한 PaperWritingBench는 CVPR 2025와 ICLR 2025에 채택된 논문 200편을 바탕으로 만들어졌습니다.
각 논문에서 아이디어 요약, 실험 로그, 템플릿, 가이드라인, 그림을 역으로 뽑아내서, 마치 연구자가 초벌 재료만 들고 있는 상황을 재현합니다.
이 설계가 중요한 이유는 간단합니다.
기존 자동 연구 시스템은 실험까지 포함한 전체 루프를 같이 평가하는 경우가 많았습니다.
그러면 “논문을 잘 썼는가”와 “실험을 잘 했는가”가 섞입니다.
PaperWritingBench는 이 둘을 분리합니다.
즉, 작성 능력만 따로 재는 실험장을 만든 셈입니다.
또 하나 흥미로운 점은 입력을 두 버전으로 만든다는 것입니다.
- Sparse idea는 높은 수준의 개념만 남깁니다.
- Dense idea는 보다 기술적인 정의와 세부 표현까지 살립니다.
이렇게 하면, 인간이 얼마나 자세한 초안을 줬는지에 따라 시스템이 얼마나 흔들리는지도 볼 수 있습니다.
CVPR 쪽 샘플은 비교적 압축적입니다.
인용 수는 충분하지만, 실험 로그와 시각 자료의 양은 ICLR보다 덜 복잡합니다.

주목 포인트: 왼쪽과 가운데 분포를 보면, 이 벤치마크는 단순 텍스트 요약이 아니라 인용량과 원시 재료 길이까지 함께 통제한다는 점이 드러납니다.
반대로 ICLR 쪽 샘플은 더 빽빽합니다.
평균적으로 그림은 약 9.19개, 표는 8.13개로 CVPR의 5.20개, 4.20개보다 많고, 실험 로그 길이도 약 2,387단어로 더 깁니다.
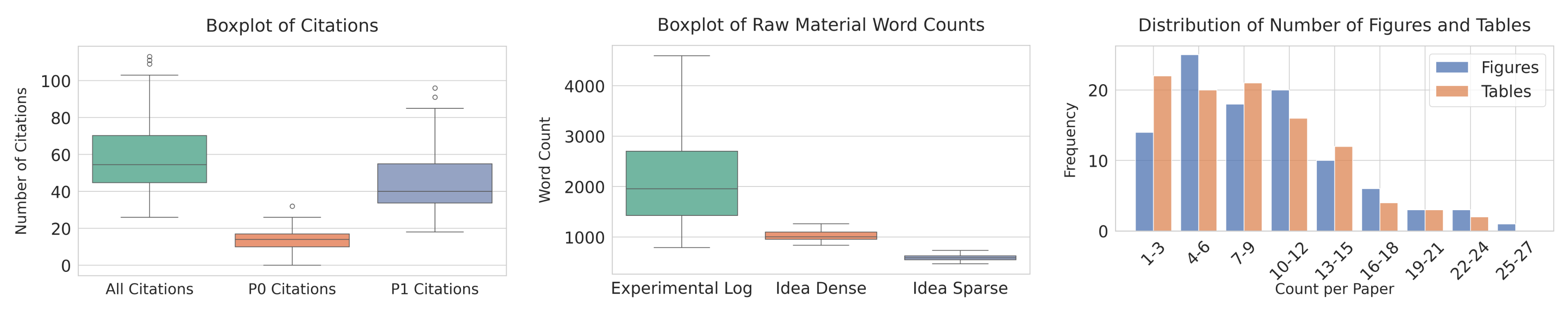
주목 포인트: 오른쪽 히스토그램과 가운데 분포를 보면, ICLR 분할은 시각 자료와 로그 길이가 더 커서 실제로 더 어려운 작성 조건을 만듭니다.
결과는 어떻게 봐야 하나
1) 자동 평가에서는 거의 전 구간에서 앞선다
자동 SxS 평가에서는 Single Agent와 AI Scientist-v2를 상대로 우세가 매우 뚜렷합니다.
특히 관련 연구 품질과 전체 원고 품질 모두에서, 파란 영역이 크게 잡힙니다.
저자들의 해석대로라면, 이 시스템은 문헌 리뷰를 깊게 쓰는 능력과 전체 원고를 정리하는 능력을 동시에 개선합니다.
다만 이 그림은 어디까지나 자동 심사기의 판단입니다.
그래서 이 논문은 자동 평가만으로 끝내지 않고, 뒤에서 사람 평가를 따로 붙입니다.

주목 포인트: 사람 원고와의 비교는 자동 심사기가 구조적인 글쓰기를 얼마나 선호하는지 보여주고, AI baseline과의 비교는 PaperOrchestra의 우세가 거의 일관적이라는 점을 보여줍니다.
자동 평가 외에 세부 수치도 인상적입니다.
- ScholarPeer 기준 시뮬레이션 수락률은 CVPR 84%, ICLR 81%입니다.
- 가장 강한 AI baseline 대비 수락률 이득은 CVPR에서 13%p, ICLR에서 9%p입니다.
- 생성한 참고문헌 수는 약 46~48개로, baseline의 약 10~14개보다 훨씬 많고 인간 원고의 평균인 약 59개에도 꽤 근접합니다.
이 숫자가 의미하는 바는 명확합니다.
이 시스템은 몇 편의 뻔한 핵심 논문만 집어 넣는 방식이 아니라, 주변 맥락까지 채우는 관련 연구 작성을 시도합니다.
2) 사람 평가에서도 이긴다
인간 평가에서는 11명의 AI 연구자가 40편의 샘플을 읽고, 총 180개의 쌍대 비교를 수행했습니다.
여기서도 결과는 유지됩니다.
- 문헌 리뷰 품질에서는 AI baseline 대비 50~68%p의 절대 우세를 보였습니다.
- 전체 논문 품질에서는 14~38%p의 절대 우세를 보였습니다.
- 인간이 쓴 원고와 비교해도, 문헌 리뷰에서는 43%의 tie/win 비율을 기록합니다.
이 지점이 중요합니다.
자동 심사기만 좋아하는 구조적 글쓰기가 아니라, 사람이 읽어도 관련 연구와 원고 완성도가 더 낫다는 신호가 나온 것입니다.

주목 포인트: 왼쪽 막대는 사람 평가에서도 baseline 대비 우세가 유지된다는 점을, 오른쪽 표는 전체 원고 품질에 대해서는 자동 평가가 인간 판단과 꽤 비슷하게 움직인다는 점을 보여줍니다.
3) 진짜 차이는 “핵심 인용”보다 “맥락 인용”에서 난다
이 논문에서 흥미로운 부분은 인용 평가 방식입니다.
저자들은 참고문헌을 두 층으로 나눕니다.
- 꼭 들어가야 하는 인용: 직접 비교한 baseline, 사용한 데이터셋, 평가 지표, 직접적으로 기대고 있는 핵심 방법
- 들어가면 더 좋은 인용: 넓은 배경과 주변 맥락을 채우는 관련 연구
Baseline도 첫 번째 부류는 어느 정도 따라갑니다.
하지만 두 번째 부류에서는 크게 약합니다.
즉, “논문 제목 몇 개 맞히기”는 되지만,
왜 이 연구가 지금 여기에서 필요한가를 설계하는 문헌 리뷰는 잘 못합니다.
PaperOrchestra의 강점은 바로 여기에 있습니다.
관련 연구를 많이 넣는 데서 끝나지 않고, 소개와 관련 연구를 새 논문의 문제 설정에 맞춰 재구성합니다.
4) 마지막 정제 루프의 효과가 크다
이 시스템이 잘 쓰는 이유를 한 줄로 줄이면, 초안 생성보다 후반 정제가 강하다는 것입니다.
저자들은 마지막 Content Refinement Agent만 따로 떼어 실험합니다.
그 결과, 정제 후 원고는 정제 전 원고를 상대로 자동 SxS에서 79~81% 승률을 기록했고, 패배는 없었습니다.
시뮬레이션 수락률도 CVPR에서 19%p, ICLR에서 22%p 올라갑니다.
이건 꽤 중요한 메시지입니다.
좋은 논문 작성은 “한 번에 잘 쓰기”보다, 리뷰를 흉내 낸 피드백 루프로 논리를 정리하는 일에 가깝다는 뜻입니다.

주목 포인트: 왼쪽은 정제 후 버전이 정제 전 버전을 거의 일방적으로 이긴다는 점을, 오른쪽은 그 개선이 실제 심사 점수 상승으로도 이어진다는 점을 보여줍니다.
이 논문이 특히 흥미로운 이유
이 논문은 단순히 “논문도 LLM이 쓸 수 있다”를 보여주는 데서 끝나지 않습니다.
오히려 더 중요한 메시지는 아래 세 가지입니다.
- 논문 쓰기는 스타일링 문제가 아니다.
관련 연구 탐색, 근거 검증, 표와 그림 배치, 섹션별 목적 분리, 리뷰 대응까지 포함한 복합 작업이다. - 문헌 리뷰는 별도 전문 작업이다.
일반적인 RAG나 키워드 검색만으로는 부족하고, 새 논문의 문제 설정에 맞는 타깃형 비교가 필요하다. - 좋은 자동 작성기는 실험 로그를 이야기로 바꿔야 한다.
숫자를 복사하는 것이 아니라, 어떤 결과가 어떤 주장과 연결되는지 설명해야 한다.
실무적으로 읽을 포인트
이 논문을 실제 도구 관점에서 보면 더 흥미롭습니다.
- 전체 시스템은 평균적으로 약 60~70회의 LLM 호출과 약 39.6분의 처리 시간을 사용합니다.
단일 프롬프트 방식보다 훨씬 무겁지만, 품질 향상을 위해 그 비용을 감수하는 설계입니다. - Dense idea를 주면 전체 논문 품질은 더 좋아집니다.
즉, 방법 정의가 촘촘할수록 본문 품질이 올라갑니다. - 그런데 문헌 리뷰는 sparse input에서도 꽤 강합니다.
이는 관련 연구 작성이 입력 밀도보다 검색 전략과 구조화에 더 크게 좌우된다는 뜻으로 읽힙니다. - 자동 생성 그림도 생각보다 나쁘지 않습니다.
사람이 만든 그림을 준 설정과 비교해도 51~66%의 tie/win 비율을 보입니다.
한계도 분명하다
저자들도 한계를 솔직하게 적습니다.
- 그림 생성은 외부 시각화 시스템에 기대고 있어서, 그림 자체의 환각을 완전히 통제하지 못합니다.
- 벤치마크가 공개 논문에서 역으로 만들어졌기 때문에, 사전학습 오염 가능성을 완전히 지우기는 어렵습니다.
- 무엇보다 이 시스템은 저자 책임을 대체하는 도구가 아닙니다.
최종 주장, 실험의 타당성, 윤리적 책임은 여전히 인간 연구자에게 있습니다.
마무리
PaperOrchestra의 진짜 기여는 “논문 작성 자동화”라는 말을 더 구체적인 문제로 쪼갰다는 데 있습니다.
좋은 원고는 한 번에 쓰는 것이 아니라,
- 먼저 무엇을 보여줄지 계획하고,
- 어떤 문헌이 필요한지 찾고,
- 실험 로그를 이야기 구조로 바꾸고,
- 마지막으로 리뷰 관점에서 다시 다듬는 과정 속에서 나온다는 것입니다.
그래서 이 논문은 단순한 데모보다,
AI 연구 보조 도구가 앞으로 어디까지 분업화되어야 하는지 보여주는 설계도에 더 가깝습니다.
Source
- Yiwen Song, Yale Song, Tomas Pfister, Jinsung Yoon.
PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing. - arXiv: 2604.05018
https://arxiv.org/abs/2604.05018 - Project Page
https://yiwen-song.github.io/paper_orchestra/
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| MiroFish — 문서 기반 GraphRAG와 OASIS 멀티에이전트 시뮬레이션으로 “미래를 리허설”하는 예측 엔진 (0) | 2026.04.10 |
|---|---|
| MegaTrain 논문 정리 (1) | 2026.04.10 |
| DFlash: Block Diffusion for Flash Speculative Decoding 논문 정리 (0) | 2026.04.09 |
| EAGLE-3 논문 정리 (0) | 2026.04.09 |
| In-Place Test-Time Training 논문 정리 (0) | 2026.04.09 |



