한눈에 보기
- 핵심 주장: GPU 메모리에 모델 전체를 상주시킬 필요는 없다. CPU 메모리를 주 저장소로 쓰고, GPU는 레이어 단위 계산 장치처럼 잠깐만 쓰면 된다.
- 핵심 성과: 단일 H200 GPU와 1.5TB 호스트 메모리에서 120B 규모 모델 학습을 시연했다.
- 성능 포인트: GH200에서 14B 학습 시 ZeRO-3 CPU Offload 대비 1.84배 높은 처리량을 보고했다.
- 확장성 포인트: 단일 GH200에서 최대 512K 컨텍스트까지 학습 가능하다고 보여준다.
이 논문의 진짜 메시지는 단순히 "오프로딩을 더 잘했다"가 아니다.
GPU를 주 저장소로 보는 관점을 버리고, 메모리 계층 전체를 다시 설계했다는 데 있다.
모델이 커질수록 이 차이는 더 선명해진다. 작은 모델에서만 잠깐 빠른 방식이 아니라, 기존 오프로딩 방식이 메모리 한계에 걸리는 구간에서도 MegaTrain은 계속 처리량을 유지한다.

주목 포인트: 32B 이후에도 MegaTrain의 막대가 계속 남아 있는 반면, 비교 대상은 메모리 한계로 사라지는 구간이 이 논문의 요지를 가장 압축해서 보여준다.
왜 기존 방식으로는 한계가 빨리 오나
대형 언어모델 학습은 단순히 가중치만 올려두는 문제가 아니다.
학습 중에는 다음이 함께 메모리를 차지한다.
- 모델 파라미터
- 그래디언트
- 옵티마이저 상태
- 중간 활성값
- 연산용 작업 공간
논문이 강조하는 포인트는 여기서 시작된다.
기존 오프로딩 시스템도 CPU 메모리를 활용하긴 하지만, GPU를 여전히 중심 저장소처럼 대한다. CPU는 넘친 것을 잠시 받아주는 보조 공간에 가깝다.
MegaTrain은 이 관계를 뒤집는다.
호스트 메모리가 진짜 저장소이고, GPU 메모리는 계산 직전에 필요한 레이어만 잠깐 담아두는 캐시가 된다. 그래서 모델 크기와 GPU 메모리 크기의 결합이 크게 약해진다.
이 관점 전환은 호스트 메모리 사용 패턴에서도 드러난다. 다른 시스템은 중복 버퍼와 파편화 때문에 메모리 사용량이 빠르게 부풀지만, MegaTrain은 보다 직접적으로 이론적 필요량에 가깝게 증가한다.

주목 포인트: 모델이 커질수록 경쟁 방식은 메모리 곡선이 더 가파르게 올라가지만, MegaTrain은 불필요한 중복을 줄여 증가 폭을 상대적으로 눌러 놓는다.
MegaTrain은 어떻게 작동하나
1) CPU가 정본이고 GPU는 계산 캐시다
MegaTrain의 아키텍처는 단순하다.
파라미터와 옵티마이저 상태는 CPU 메모리에 두고, GPU에는 지금 계산할 레이어의 가중치만 스트리밍해서 넣는다. 해당 레이어 계산이 끝나면 바로 비운다. 역전파 때는 다시 불러와 그래디언트를 계산한 뒤 곧바로 CPU로 돌려보낸다.
이 구조 덕분에 GPU가 계속 붙잡고 있어야 하는 상태가 크게 줄어든다.
모델 전체가 아니라 "지금 필요한 한 층" 중심으로 메모리를 쓴다.

주목 포인트: GPU 영역에 모델 전체가 아니라 weight buffer, gradient slab, template 같은 임시 실행 구성요소만 남아 있다는 점이 설계의 핵심이다.
2) 계산과 전송을 동시에 굴린다
이 방식의 가장 큰 위험은 분명하다.
CPU와 GPU 사이를 계속 오가면 전송이 병목이 될 수 있다.
MegaTrain은 여기서 이중 버퍼링(double buffering) 과 다중 CUDA 스트림을 사용한다.
- 한 버퍼에서 현재 레이어를 계산하는 동안
- 다른 버퍼에는 다음 레이어 가중치를 미리 올려두고
- 동시에 이전 레이어의 그래디언트는 CPU로 내려보낸다
즉, 가중치 업로드, 실제 계산, 그래디언트 오프로드가 시간축에서 겹치도록 만든다. GPU가 데이터를 기다리며 노는 시간을 줄이는 방식이다.
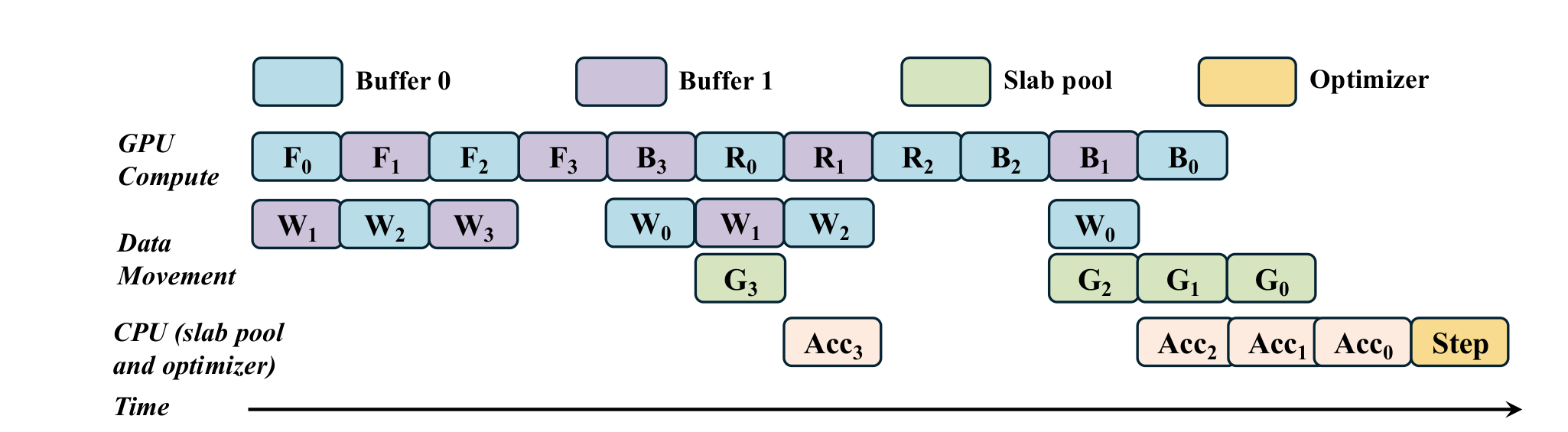
주목 포인트: 같은 시간축 위에 W(가중치 전송), F/R/B(전방·재계산·역전파), G(그래디언트 오프로드)가 겹쳐 배치된 부분이 많을수록 GPU 유휴 시간이 줄어든다.
3) 거대한 자동미분 그래프를 들고 있지 않는다
일반적인 자동미분은 "모든 것이 GPU에 계속 남아 있다"는 가정을 깔고 움직인다.
하지만 MegaTrain은 레이어를 계속 불러오고 바로 비우기 때문에 이 가정이 맞지 않는다.
그래서 논문은 stateless layer template라는 방식을 쓴다.
- GPU에는 빈 Transformer 레이어 틀만 남겨 둔다
- 실제 가중치는 계산 직전에 동적으로 연결한다
- 역전파를 위해 필요한 활성값은 몇 층마다 체크포인트만 남기고, 나머지는 필요할 때 다시 계산한다
직관적으로 보면, "모델을 GPU에 올려 둔다"가 아니라 "레이어 틀은 고정해 두고 가중치만 갈아 끼운다" 에 가깝다.
4) 옵티마이저 업데이트는 CPU에서 처리한다
이 선택도 중요하다.
Adam 같은 옵티마이저는 계산 자체보다 데이터를 많이 읽고 쓰는 비용이 더 크다. 이 작업까지 GPU에서 하려면 파라미터와 상태를 다시 왕복시켜야 한다.
MegaTrain은 옵티마이저 상태를 CPU에 둔 채 업데이트도 CPU에서 처리한다.
논문은 이 판단이 추가 전송을 줄이는 데 더 유리하다고 본다.
실험에서 무엇이 확인됐나
처리량은 단순히 "돌아가는 수준"이 아니다
논문은 GH200과 H200에서 MegaTrain이 단지 더 큰 모델을 억지로 올리는 것이 아니라, 실제 처리량도 상당히 높게 유지한다고 보고한다.
- GH200에서 7B는 284 TFLOPS
- GH200에서 14B는 264 TFLOPS
- GH200에서 32B도 250 TFLOPS 이상 유지
- H200에서는 72B와 120B까지 확장
특히 14B에서 ZeRO-3 Offload 대비 1.84배 높은 처리량을 보였다는 점이 대표 결과다.
정확도도 유지된다
성능만 좋아지고 학습 결과가 틀어지면 의미가 없다.
논문은 7B와 14B에서 MegaTrain의 정확도가 일반 full-GPU 학습 및 ZeRO 계열과 사실상 같은 수준이라고 보고한다.
- 7B 정확도: 88.99%
- 14B 정확도: 92.52%
즉, 메모리 구조를 바꾸면서 정확도를 희생하지 않았다는 것이 논문의 주장이다.
어떤 요소가 가장 중요했나
아블레이션 결과에서 가장 눈에 띄는 것은 double buffering의 중요성이다.
이 기능을 빼면 처리량이 크게 떨어진다. 반대로 gradient slab pool 제거는 상대적으로 영향이 작다.
해석은 분명하다.
MegaTrain의 경쟁력은 "오프로딩을 한다" 자체보다, 오프로딩을 계산과 얼마나 잘 겹치게 설계했는가에서 나온다.
깊이를 늘렸을 때도 버티는가
깊이 확장 실험은 특히 흥미롭다.
논문은 GPU 메모리 할당량을 거의 고정해 둔 상태에서, 레이어 수만 늘려 모델을 더 깊게 만든다. 이 조건은 시스템의 메모리 조율 능력을 직접 시험한다.
결과는 명확하다.
- 28층에서 180층으로 깊이가 커져도 MegaTrain 처리량은 비교적 완만하게 감소
- 동일 조건에서 ZeRO-3와 FSDP 계열은 더 빨리 무너지거나 OOM
- MegaTrain은 180층, 약 43B 규모까지 계속 동작

주목 포인트: 왼쪽 그래프에서는 깊이가 늘어도 MegaTrain 처리량이 비교적 안정적으로 유지되고, 오른쪽 그래프에서는 호스트 메모리가 예측 가능한 속도로만 증가한다.
이 결과는 "깊이가 깊어질수록 레이어를 순차적으로 흘려보내는 구조가 더 유리해질 수 있다"는 해석으로 이어진다.
너비를 키우면 어떤 일이 생기나
너비 확장은 깊이 확장과 다르게, 레이어 하나하나가 무거워지는 상황이다.
이 경우는 전송량, 활성값 크기, 행렬곱 비용이 함께 커지므로 더 까다롭다.
여기서도 MegaTrain은 비교적 완만하게 성능이 감소한다.
- 1.0배 너비에서 3.0배 너비로 가도 처리량 감소 폭이 상대적으로 작다
- 3.5배 이후에는 ZeRO-3가 더 빠르게 흔들린다
- 4.0배를 넘는 구간에서는 경쟁 방식이 OOM에 더 빨리 도달한다
- MegaTrain은 5.0배 너비까지 동작한다

주목 포인트: 3.5배 이후부터 비교 대상 막대가 급격히 줄거나 사라지는 반면, MegaTrain은 마지막 구간까지 남아 있다는 점이 폭넓은 스케일링 특성을 보여준다.
즉, 이 시스템은 "깊은 모델"뿐 아니라 한 층이 큰 모델에도 일정 수준 버틸 수 있다.
긴 컨텍스트에서도 통하나
논문은 단일 GH200에서 긴 컨텍스트 학습도 실험한다.
- 1K에서 512K까지 컨텍스트를 확장
- 512K에서는 batch size가 1까지 내려가지만 학습은 계속 진행
- 처리량은 오히려 284.7 TFLOPS에서 407.4 TFLOPS까지 상승
- 메모리 사용량은 대체로 60~80GB대에서 관리된다
이 결과가 의미하는 바는 단순하다.
MegaTrain은 모델 크기만이 아니라, 시퀀스 길이가 길어져도 활성값 폭발을 레이어 단위 실행과 재계산으로 제어한다는 것이다.
다른 장비에서도 효과가 있나
논문은 GH200/H200 같은 고급 장비만 보지 않는다.
A100 PCIe, RTX A6000, RTX 3090 같은 더 현실적인 장비에서도 결과를 제시한다.
A100 PCIe 결과만 봐도 차이는 분명하다.
- 7B: MegaTrain 128 TFLOPS, Gemini 53, ZeRO-3 36
- 14B: MegaTrain 122 TFLOPS, Gemini 15, ZeRO-3 10
- 32B: 비교 대상은 OOM, MegaTrain은 114 TFLOPS
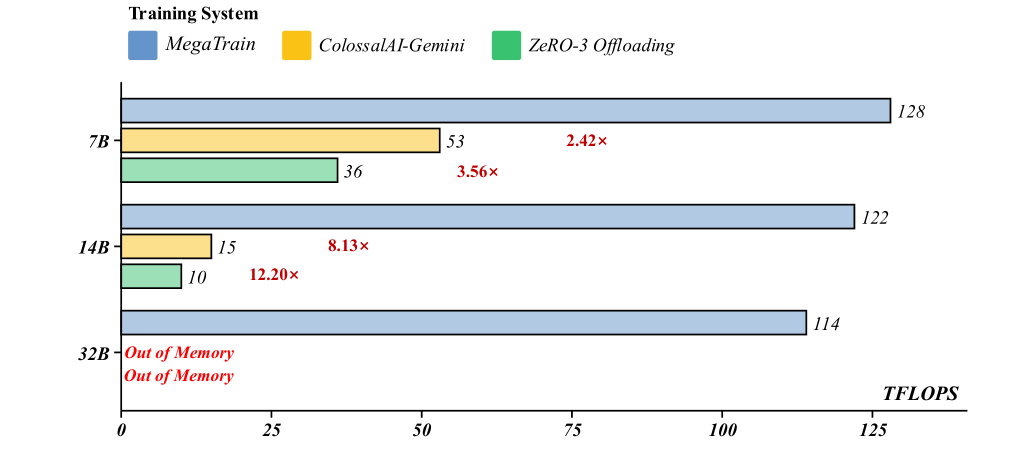
주목 포인트: 14B와 32B 구간에서 비교 대상 막대가 급격히 줄거나 사라지는 반면 MegaTrain은 끝까지 유지되는 모습이 하드웨어 범용성을 보여준다.
소비자급 카드에서도 비슷한 메시지가 나온다.
- RTX A6000 48GB에서 14B 학습 가능
- RTX 3090 24GB에서도 14B 학습 가능
- 같은 조건의 ZeRO-3 Offload는 14B에서 OOM
이 부분은 특히 실용적이다.
논문이 겨냥하는 대상이 대규모 프리트레이닝 전용 슈퍼클러스터가 아니라, GPU는 적지만 CPU 메모리는 상대적으로 확보 가능한 연구실과 소규모 팀이라는 점이 분명해진다.
이 논문의 의미
이 논문은 대형 모델 학습의 질문을 이렇게 바꾼다.
- "GPU 메모리가 얼마나 큰가?"
- 가 아니라
- "메모리 계층을 얼마나 영리하게 쓰는가?"
그래서 MegaTrain의 기여는 세 가지로 요약할 수 있다.
- 메모리 계층의 역할을 뒤집었다.
CPU는 보조 공간이 아니라 주 저장소가 된다. - 전송 지연을 계산 뒤로 숨겼다.
스트리밍을 하면서도 GPU를 계속 바쁘게 만든다. - 그래프 기반 실행의 고정관념을 버렸다.
stateless template와 블록 단위 재계산으로 GPU 상주 상태를 최소화한다.
한계와 읽을 때 주의할 점
좋은 결과와 별개로, 현실적인 제약도 분명하다.
- 호스트 메모리 요구량이 크다.
120B 결과는 H200 + 1.5TB 호스트 메모리 환경에서 나온다. 단일 GPU라고 해서 값싼 구성이 되는 것은 아니다. - 인터커넥트 품질에 민감하다.
GH200처럼 CPU-GPU 연결이 강한 시스템에서는 특히 유리하고, 일반 PCIe 환경에서는 이점이 줄어들 수 있다. 다만 논문은 A100 PCIe에서도 충분한 효과를 보였다고 주장한다. - 평가 범위는 주로 단일 GPU 후처리 학습 관점이다.
대규모 프리트레이닝, 장기 안정성, 다양한 태스크 일반화, 멀티 GPU 확장은 앞으로 더 확인이 필요하다. - 업로드된 버전은 arXiv preprint다.
따라서 후속 구현이나 재현 결과를 함께 확인하는 것이 좋다.
정리
MegaTrain은 "GPU에 전부 올려야 학습할 수 있다"는 상식을 깨는 시스템 논문이다.
핵심은 화려한 트릭보다도, 무엇을 어디에 오래 두고 무엇을 잠깐만 두는가를 다시 정의한 데 있다.
대형 모델의 단일 GPU 학습은 앞으로도 쉬운 문제가 아니다.
하지만 이 논문은 최소한 하나의 분명한 방향을 제시한다.
GPU 용량을 키우는 것만이 답이 아니라, 메모리 계층 전체를 다시 설계하는 것이 답이 될 수 있다.
Source
- Zhengqing Yuan, Hanchi Sun, Lichao Sun, Yanfang Ye. MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU. arXiv:2604.05091v1, 2026.
- Paper: arXiv 2604.05091
- Code: DLYuanGod/MegaTrain
'AI 생성 글 정리 > agent' 카테고리의 다른 글
| MiroFish — 문서 기반 GraphRAG와 OASIS 멀티에이전트 시뮬레이션으로 “미래를 리허설”하는 예측 엔진 (0) | 2026.04.10 |
|---|---|
| PaperOrchestra 논문 정리 (0) | 2026.04.10 |
| DFlash: Block Diffusion for Flash Speculative Decoding 논문 정리 (0) | 2026.04.09 |
| EAGLE-3 논문 정리 (0) | 2026.04.09 |
| In-Place Test-Time Training 논문 정리 (0) | 2026.04.09 |



